 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCUDiff: Latent Capacity Upgrade Diffusion for Faithful Human Body Restoration
Feb 04, 2026Existing methods for restoring degraded human-centric images often struggle with insufficient fidelity, particularly in human body restoration (HBR). Recent diffusion-based restoration methods commonly adapt pre-trained text-to-image diffusion models, where the variational autoencoder (VAE) can significantly bottleneck restoration fidelity. We propose LCUDiff, a stable one-step framework that upgrades a pre-trained latent diffusion model from the 4-channel latent space to the 16-channel latent space. For VAE fine-tuning, channel splitting distillation (CSD) is used to keep the first four channels aligned with pre-trained priors while allocating the additional channels to effectively encode high-frequency details. We further design prior-preserving adaptation (PPA) to smoothly bridge the mismatch between 4-channel diffusion backbones and the higher-dimensional 16-channel latent. In addition, we propose a decoder router (DeR) for per-sample decoder routing using restoration-quality score annotations, which improves visual quality across diverse conditions. Experiments on synthetic and real-world datasets show competitive results with higher fidelity and fewer artifacts under mild degradations, while preserving one-step efficiency. The code and model will be at https://github.com/gobunu/LCUDiff.
Rocks Coding, Not Development--A Human-Centric, Experimental Evaluation of LLM-Supported SE Tasks
Feb 21, 2024Recently, large language models (LLM) based generative AI has been gaining momentum for their impressive high-quality performances in multiple domains, particularly after the release of the ChatGPT. Many believe that they have the potential to perform general-purpose problem-solving in software development and replace human software developers. Nevertheless, there are in a lack of serious investigation into the capability of these LLM techniques in fulfilling software development tasks. In a controlled 2 x 2 between-subject experiment with 109 participants, we examined whether and to what degree working with ChatGPT was helpful in the coding task and typical software development task and how people work with ChatGPT. We found that while ChatGPT performed well in solving simple coding problems, its performance in supporting typical software development tasks was not that good. We also observed the interactions between participants and ChatGPT and found the relations between the interactions and the outcomes. Our study thus provides first-hand insights into using ChatGPT to fulfill software engineering tasks with real-world developers and motivates the need for novel interaction mechanisms that help developers effectively work with large language models to achieve desired outcomes.
Fast CRDNN: Towards on Site Training of Mobile Construction Machines
Jun 04, 2020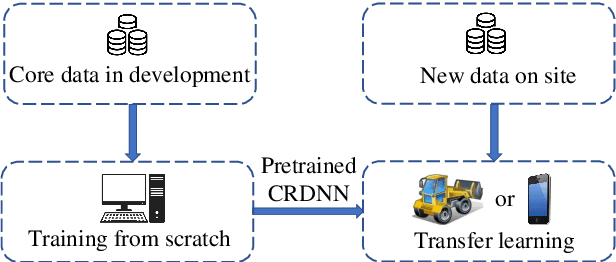

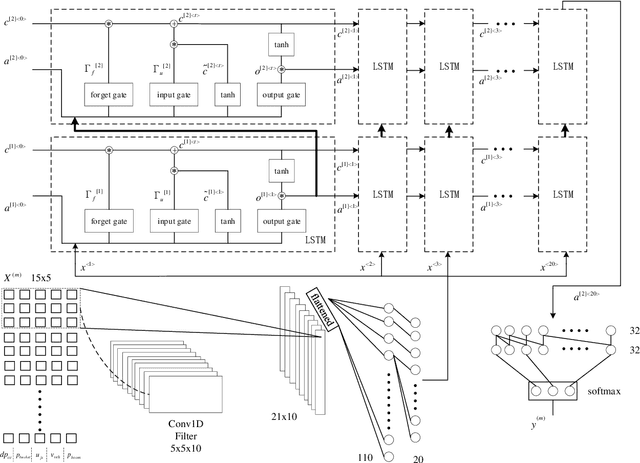

The CRDNN is a combined neural network that can increase the holistic efficiency of torque based mobile working machines by about 9% by means of accurately detecting the truck loading cycles. On the one hand, it is a robust but offline learning algorithm so that it is more accurate and much quicker than the previous methods. However, on the other hand, its accuracy can not always be guaranteed because of the diversity of the mobile machines industry and the nature of the offline method. To address the problem, we utilize the transfer learning algorithm and the Internet of Things (IoT) technology. Concretely, the CRDNN is first trained by computer and then saved in the on-board ECU. In case that the pre-trained CRDNN is not suitable for the new machine, the operator can label some new data by our App connected to the on-board ECU of that machine through Bluetooth. With the newly labeled data, we can directly further train the pretrained CRDNN on the ECU without overloading since transfer learning requires less computation effort than training the networks from scratch. In our paper, we prove this idea and show that CRDNN is always competent, with the help of transfer learning and IoT technology by field experiment, even the new machine may have a different distribution. Also, we compared the performance of other SOTA multivariate time series algorithms on predicting the working state of the mobile machines, which denotes that the CRDNNs are still the most suitable solution. As a by-product, we build up a human-machine communication system to label the dataset, which can be operated by engineers without knowledge about Artificial Intelligence (AI).