 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePubTables-v2: A new large-scale dataset for full-page and multi-page table extraction
Dec 11, 2025



Table extraction (TE) is a key challenge in visual document understanding. Traditional approaches detect tables first, then recognize their structure. Recently, interest has surged in developing methods, such as vision-language models (VLMs), that can extract tables directly in their full page or document context. However, progress has been difficult to demonstrate due to a lack of annotated data. To address this, we create a new large-scale dataset, PubTables-v2. PubTables-v2 supports a number of current challenging table extraction tasks. Notably, it is the first large-scale benchmark for multi-page table structure recognition. We demonstrate its usefulness by evaluating domain-specialized VLMs on these tasks and highlighting current progress. Finally, we use PubTables-v2 to create the Page-Object Table Transformer (POTATR), an image-to-graph extension of the Table Transformer to comprehensive page-level TE. Data, code, and trained models will be released.
Deep Maxout Network Gaussian Process
Aug 08, 2022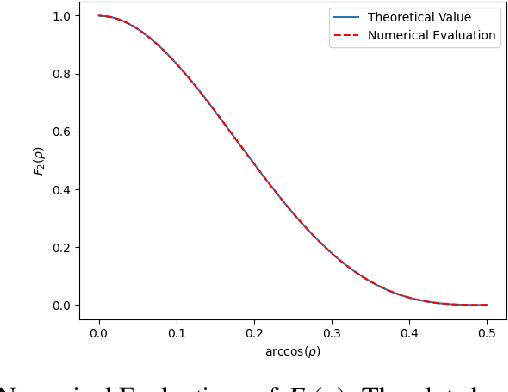
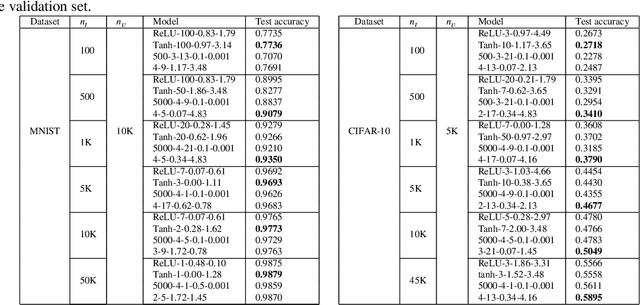
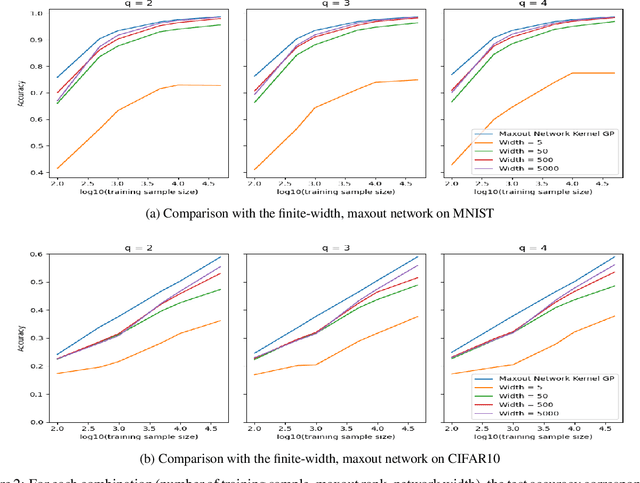
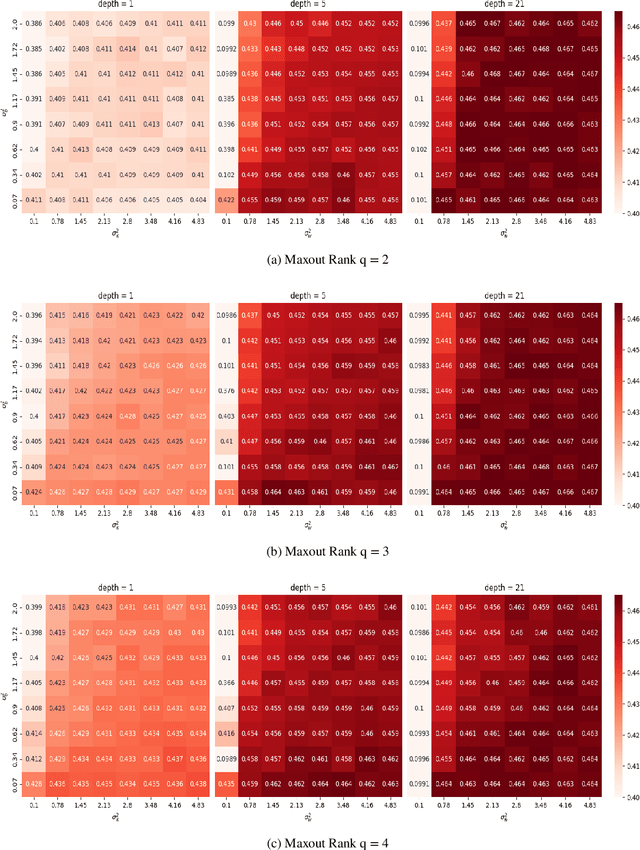
Study of neural networks with infinite width is important for better understanding of the neural network in practical application. In this work, we derive the equivalence of the deep, infinite-width maxout network and the Gaussian process (GP) and characterize the maxout kernel with a compositional structure. Moreover, we build up the connection between our deep maxout network kernel and deep neural network kernels. We also give an efficient numerical implementation of our kernel which can be adapted to any maxout rank. Numerical results show that doing Bayesian inference based on the deep maxout network kernel can lead to competitive results compared with their finite-width counterparts and deep neural network kernels. This enlightens us that the maxout activation may also be incorporated into other infinite-width neural network structures such as the convolutional neural network (CNN).