 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeStereo: A Context Integrated Residual Pyramid Network for Stereo Matching
Sep 23, 2018
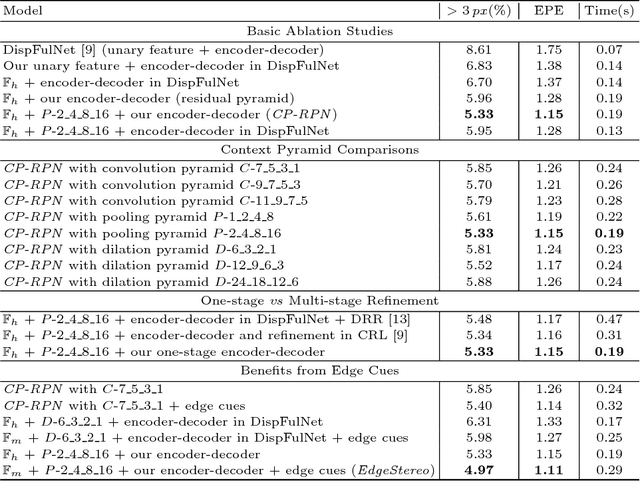
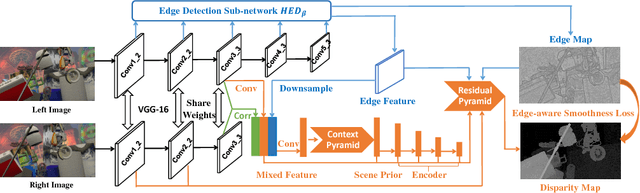
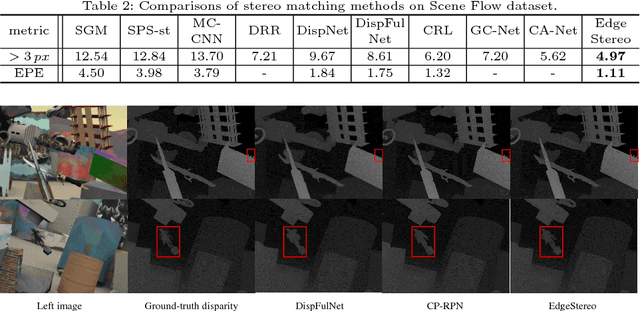
Recent convolutional neural networks, especially end-to-end disparity estimation models, achieve remarkable performance on stereo matching task. However, existed methods, even with the complicated cascade structure, may fail in the regions of non-textures, boundaries and tiny details. Focus on these problems, we propose a multi-task network EdgeStereo that is composed of a backbone disparity network and an edge sub-network. Given a binocular image pair, our model enables end-to-end prediction of both disparity map and edge map. Basically, we design a context pyramid to encode multi-scale context information in disparity branch, followed by a compact residual pyramid for cascaded refinement. To further preserve subtle details, our EdgeStereo model integrates edge cues by feature embedding and edge-aware smoothness loss regularization. Comparative results demonstrates that stereo matching and edge detection can help each other in the unified model. Furthermore, our method achieves state-of-art performance on both KITTI Stereo and Scene Flow benchmarks, which proves the effectiveness of our design.
Discriminative Representation Combinations for Accurate Face Spoofing Detection
Aug 28, 2018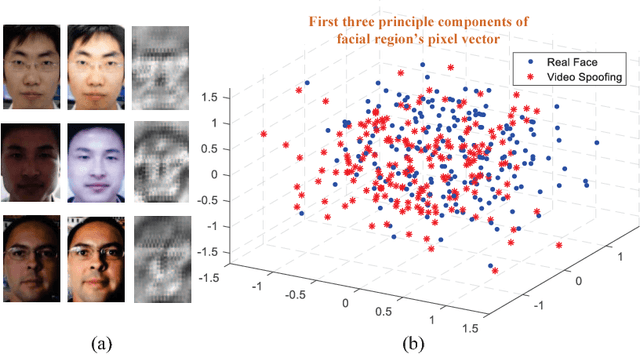
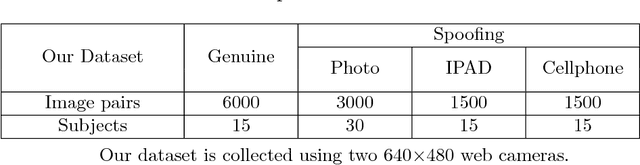
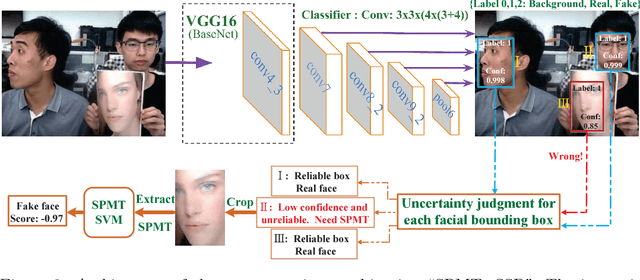
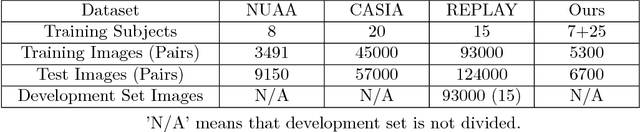
Three discriminative representations for face presentation attack detection are introduced in this paper. Firstly we design a descriptor called spatial pyramid coding micro-texture (SPMT) feature to characterize local appearance information. Secondly we utilize the SSD, which is a deep learning framework for detection, to excavate context cues and conduct end-to-end face presentation attack detection. Finally we design a descriptor called template face matched binocular depth (TFBD) feature to characterize stereo structures of real and fake faces. For accurate presentation attack detection, we also design two kinds of representation combinations. Firstly, we propose a decision-level cascade strategy to combine SPMT with SSD. Secondly, we use a simple score fusion strategy to combine face structure cues (TFBD) with local micro-texture features (SPMT). To demonstrate the effectiveness of our design, we evaluate the representation combination of SPMT and SSD on three public datasets, which outperforms all other state-of-the-art methods. In addition, we evaluate the representation combination of SPMT and TFBD on our dataset and excellent performance is also achieved.