 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Classification via Categorical Memory Networks
Dec 12, 2020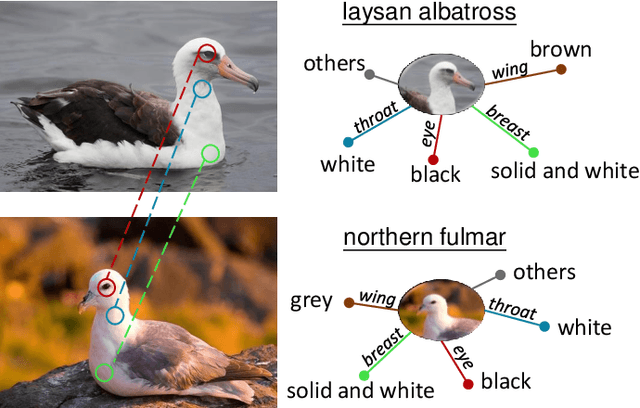


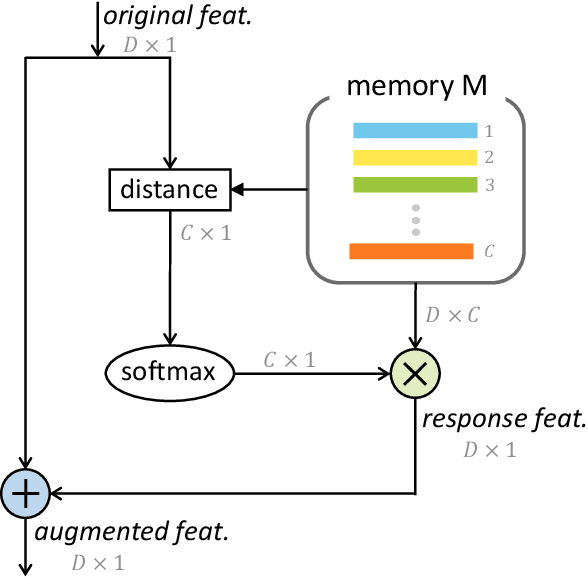
Motivated by the desire to exploit patterns shared across classes, we present a simple yet effective class-specific memory module for fine-grained feature learning. The memory module stores the prototypical feature representation for each category as a moving average. We hypothesize that the combination of similarities with respect to each category is itself a useful discriminative cue. To detect these similarities, we use attention as a querying mechanism. The attention scores with respect to each class prototype are used as weights to combine prototypes via weighted sum, producing a uniquely tailored response feature representation for a given input. The original and response features are combined to produce an augmented feature for classification. We integrate our class-specific memory module into a standard convolutional neural network, yielding a Categorical Memory Network. Our memory module significantly improves accuracy over baseline CNNs, achieving competitive accuracy with state-of-the-art methods on four benchmarks, including CUB-200-2011, Stanford Cars, FGVC Aircraft, and NABirds.
Combining Semantic Guidance and Deep Reinforcement Learning For Generating Human Level Paintings
Nov 25, 2020

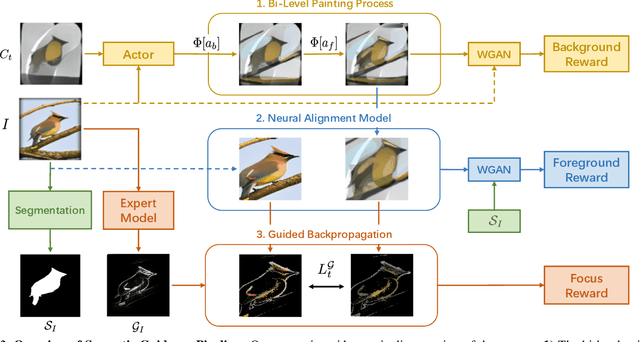

Generation of stroke-based non-photorealistic imagery, is an important problem in the computer vision community. As an endeavor in this direction, substantial recent research efforts have been focused on teaching machines "how to paint", in a manner similar to a human painter. However, the applicability of previous methods has been limited to datasets with little variation in position, scale and saliency of the foreground object. As a consequence, we find that these methods struggle to cover the granularity and diversity possessed by real world images. To this end, we propose a Semantic Guidance pipeline with 1) a bi-level painting procedure for learning the distinction between foreground and background brush strokes at training time. 2) We also introduce invariance to the position and scale of the foreground object through a neural alignment model, which combines object localization and spatial transformer networks in an end to end manner, to zoom into a particular semantic instance. 3) The distinguishing features of the in-focus object are then amplified by maximizing a novel guided backpropagation based focus reward. The proposed agent does not require any supervision on human stroke-data and successfully handles variations in foreground object attributes, thus, producing much higher quality canvases for the CUB-200 Birds and Stanford Cars-196 datasets. Finally, we demonstrate the further efficacy of our method on complex datasets with multiple foreground object instances by evaluating an extension of our method on the challenging Virtual-KITTI dataset.
Enhanced Scene Specificity with Sparse Dynamic Value Estimation
Nov 25, 2020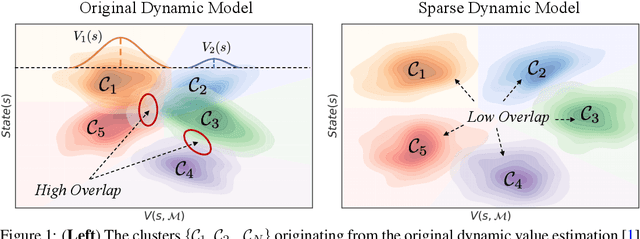
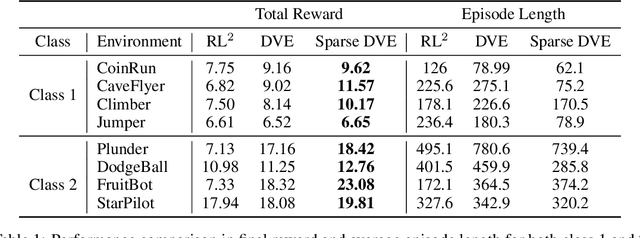
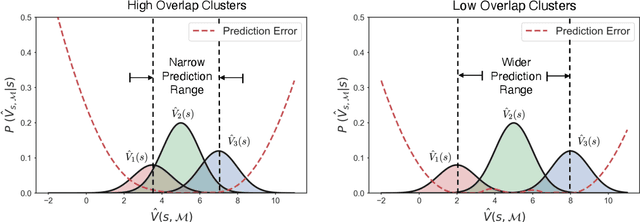
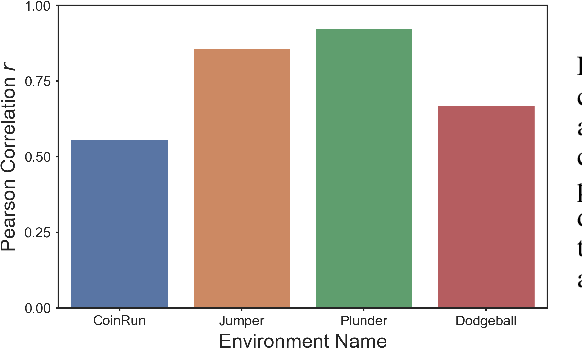
Multi-scene reinforcement learning involves training the RL agent across multiple scenes / levels from the same task, and has become essential for many generalization applications. However, the inclusion of multiple scenes leads to an increase in sample variance for policy gradient computations, often resulting in suboptimal performance with the direct application of traditional methods (e.g. PPO, A3C). One strategy for variance reduction is to consider each scene as a distinct Markov decision process (MDP) and learn a joint value function dependent on both state (s) and MDP (M). However, this is non-trivial as the agent is usually unaware of the underlying level at train / test times in multi-scene RL. Recently, Singh et al. [1] tried to address this by proposing a dynamic value estimation approach that models the true joint value function distribution as a Gaussian mixture model (GMM). In this paper, we argue that the error between the true scene-specific value function and the predicted dynamic estimate can be further reduced by progressively enforcing sparse cluster assignments once the agent has explored most of the state space. The resulting agents not only show significant improvements in the final reward score across a range of OpenAI ProcGen environments, but also exhibit increased navigation efficiency while completing a game level.
Source Free Domain Adaptation with Image Translation
Aug 17, 2020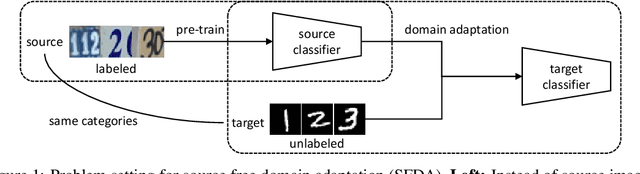

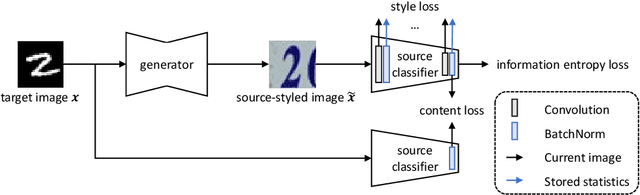
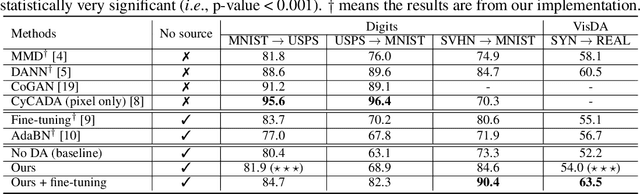
Effort in releasing large-scale datasets may be compromised by privacy and intellectual property considerations. A feasible alternative is to release pre-trained models instead. While these models are strong on their original task (source domain), their performance might degrade significantly when deployed directly in a new environment (target domain), which might not contain labels for training under realistic settings. Domain adaptation (DA) is a known solution to the domain gap problem, but usually requires labeled source data. In this paper, we study the problem of source free domain adaptation (SFDA), whose distinctive feature is that the source domain only provides a pre-trained model, but no source data. Being source free adds significant challenges to DA, especially when considering that the target dataset is unlabeled. To solve the SFDA problem, we propose an image translation approach that transfers the style of target images to that of unseen source images. To this end, we align the batch-wise feature statistics of generated images to that stored in batch normalization layers of the pre-trained model. Compared with directly classifying target images, higher accuracy is obtained with these style transferred images using the pre-trained model. On several image classification datasets, we show that the above-mentioned improvements are consistent and statistically significant.
Learning Object Relation Graph and Tentative Policy for Visual Navigation
Jul 21, 2020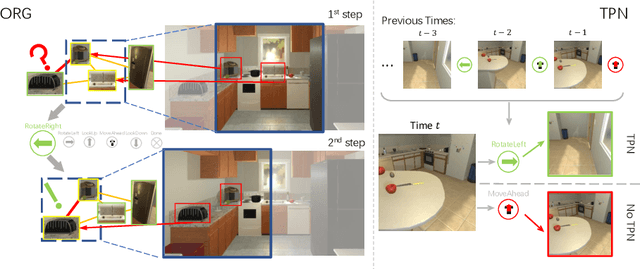
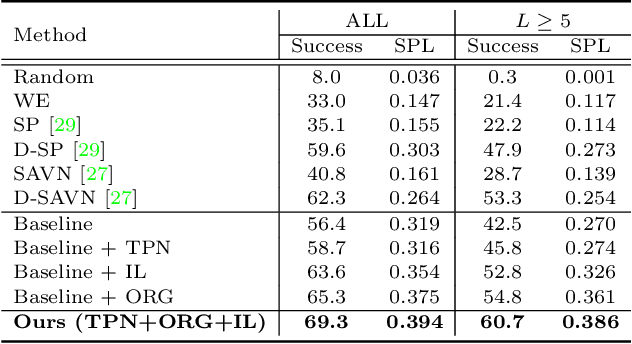
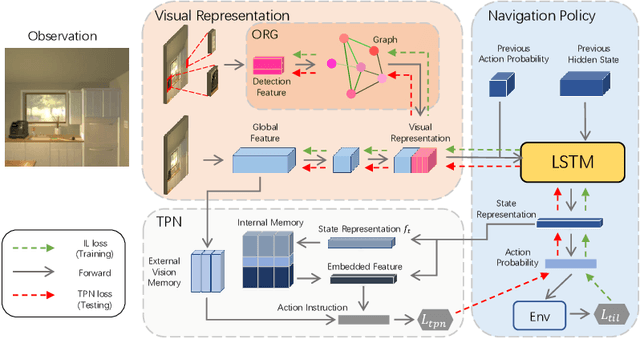
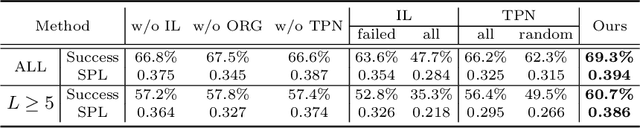
Target-driven visual navigation aims at navigating an agent towards a given target based on the observation of the agent. In this task, it is critical to learn informative visual representation and robust navigation policy. Aiming to improve these two components, this paper proposes three complementary techniques, object relation graph (ORG), trial-driven imitation learning (IL), and a memory-augmented tentative policy network (TPN). ORG improves visual representation learning by integrating object relationships, including category closeness and spatial correlations, e.g., a TV usually co-occurs with a remote spatially. Both Trial-driven IL and TPN underlie robust navigation policy, instructing the agent to escape from deadlock states, such as looping or being stuck. Specifically, trial-driven IL is a type of supervision used in policy network training, while TPN, mimicking the IL supervision in unseen environment, is applied in testing. Experiment in the artificial environment AI2-Thor validates that each of the techniques is effective. When combined, the techniques bring significantly improvement over baseline methods in navigation effectiveness and efficiency in unseen environments. We report 22.8% and 23.5% increase in success rate and Success weighted by Path Length (SPL), respectively. The code is available at https://github.com/xiaobaishu0097/ECCV-VN.git.
CycAs: Self-supervised Cycle Association for Learning Re-identifiable Descriptions
Jul 15, 2020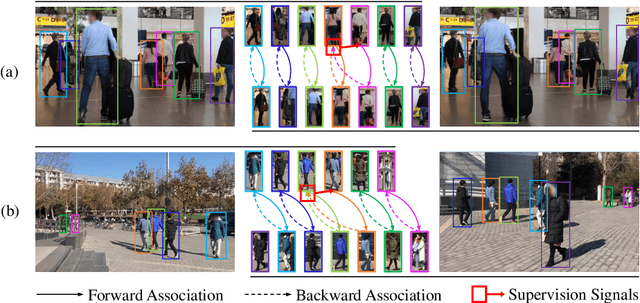
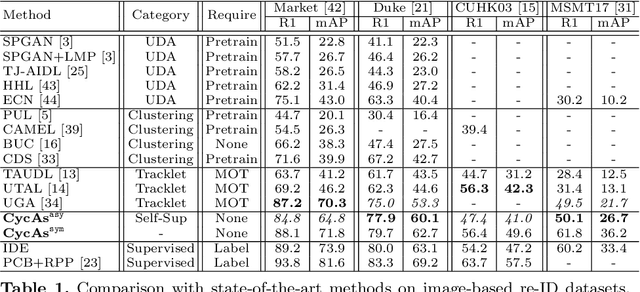
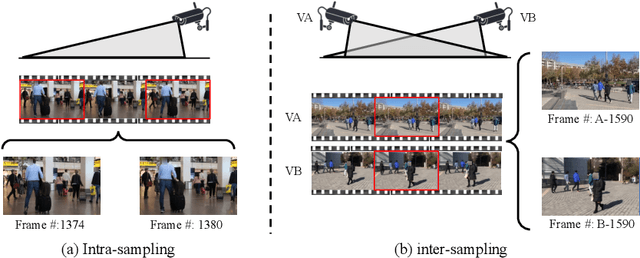
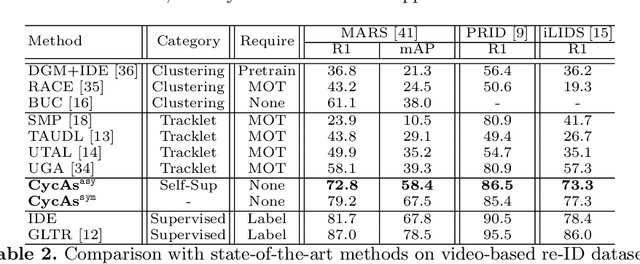
This paper proposes a self-supervised learning method for the person re-identification (re-ID) problem, where existing unsupervised methods usually rely on pseudo labels, such as those from video tracklets or clustering. A potential drawback of using pseudo labels is that errors may accumulate and it is challenging to estimate the number of pseudo IDs. We introduce a different unsupervised method that allows us to learn pedestrian embeddings from raw videos, without resorting to pseudo labels. The goal is to construct a self-supervised pretext task that matches the person re-ID objective. Inspired by the \emph{data association} concept in multi-object tracking, we propose the \textbf{Cyc}le \textbf{As}sociation (\textbf{CycAs}) task: after performing data association between a pair of video frames forward and then backward, a pedestrian instance is supposed to be associated to itself. To fulfill this goal, the model must learn a meaningful representation that can well describe correspondences between instances in frame pairs. We adapt the discrete association process to a differentiable form, such that end-to-end training becomes feasible. Experiments are conducted in two aspects: We first compare our method with existing unsupervised re-ID methods on seven benchmarks and demonstrate CycAs' superiority. Then, to further validate the practical value of CycAs in real-world applications, we perform training on self-collected videos and report promising performance on standard test sets.
Multiview Detection with Feature Perspective Transformation
Jul 14, 2020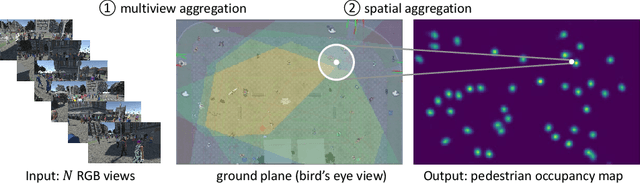

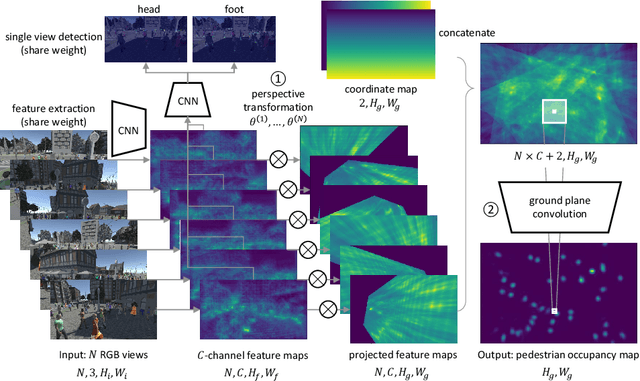
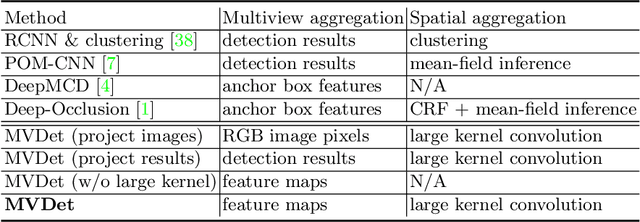
Incorporating multiple camera views for detection alleviates the impact of occlusions in crowded scenes. In a multiview system, we need to answer two important questions when dealing with ambiguities that arise from occlusions. First, how should we aggregate cues from the multiple views? Second, how should we aggregate unreliable 2D and 3D spatial information that has been tainted by occlusions? To address these questions, we propose a novel multiview detection system, MVDet. For multiview aggregation, existing methods combine anchor box features from the image plane, which potentially limits performance due to inaccurate anchor box shapes and sizes. In contrast, we take an anchor-free approach to aggregate multiview information by projecting feature maps onto the ground plane (bird's eye view). To resolve any remaining spatial ambiguity, we apply large kernel convolutions on the ground plane feature map and infer locations from detection peaks. Our entire model is end-to-end learnable and achieves 88.2% MODA on the standard Wildtrack dataset, outperforming the state-of-the-art by 14.1%. We also provide detailed analysis of MVDet on a newly introduced synthetic dataset, MultiviewX, which allows us to control the level of occlusion. Code and MultiviewX dataset are available at https://github.com/hou-yz/MVDet.
Are Labels Necessary for Classifier Accuracy Evaluation?
Jul 06, 2020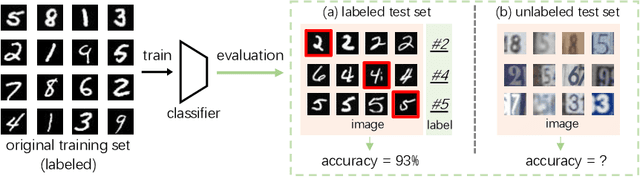
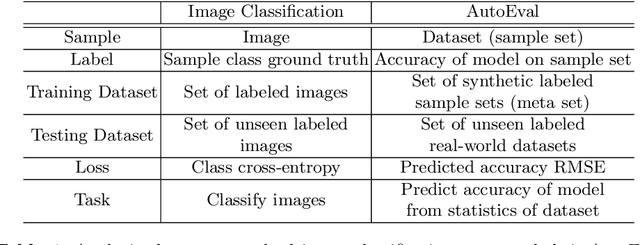
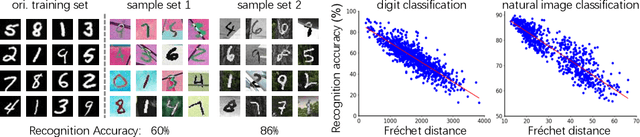

To calculate the model accuracy on a computer vision task, e.g., object recognition, we usually require a test set composed of test samples and their ground truth labels. Whilst standard usage cases satisfy this requirement, many real-world scenarios involve unlabeled test data, rendering common model evaluation methods infeasible. We investigate this important and under-explored problem, Automatic model Evaluation (AutoEval). Specifically, given a labeled training set and a model, we aim to estimate the model accuracy on unlabeled test datasets. We construct a meta-dataset: a dataset comprised of datasets generated from the original training set via various image transformations such as rotation, background substitution, foreground scaling, etc. As the classification accuracy of the model on each sample (dataset) is known from the original dataset labels, our task can be solved via regression. Using the feature statistics to represent the distribution of a sample dataset, we can train regression techniques (e.g., a regression neural network) to predict model performance. Using synthetic meta-dataset and real-world datasets in training and testing, respectively, we report reasonable and promising estimates of the model accuracy. We also provide insights into the application scope, limitation, and future directions of AutoEval.
Learning to simulate complex scenes
Jun 25, 2020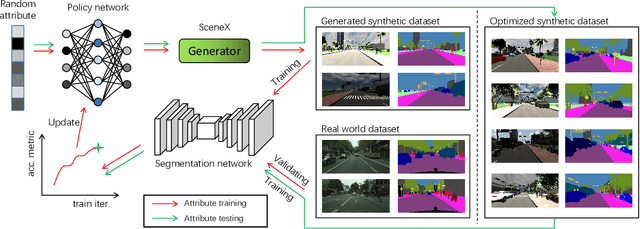
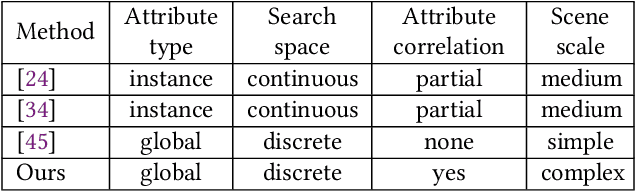

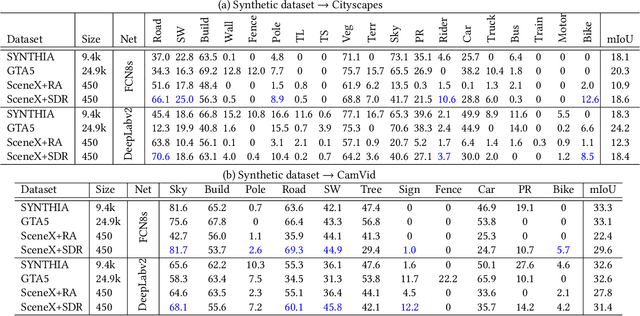
Data simulation engines like Unity are becoming an increasingly important data source that allows us to acquire ground truth labels conveniently. Moreover, we can flexibly edit the content of an image in the engine, such as objects (position, orientation) and environments (illumination, occlusion). When using simulated data as training sets, its editable content can be leveraged to mimic the distribution of real-world data, and thus reduce the content difference between the synthetic and real domains. This paper explores content adaptation in the context of semantic segmentation, where the complex street scenes are fully synthesized using 19 classes of virtual objects from a first person driver perspective and controlled by 23 attributes. To optimize the attribute values and obtain a training set of similar content to real-world data, we propose a scalable discretization-and-relaxation (SDR) approach. Under a reinforcement learning framework, we formulate attribute optimization as a random-to-optimized mapping problem using a neural network. Our method has three characteristics. 1) Instead of editing attributes of individual objects, we focus on global attributes that have large influence on the scene structure, such as object density and illumination. 2) Attributes are quantized to discrete values, so as to reduce search space and training complexity. 3) Correlated attributes are jointly optimized in a group, so as to avoid meaningless scene structures and find better convergence points. Experiment shows our system can generate reasonable and useful scenes, from which we obtain promising real-world segmentation accuracy compared with existing synthetic training sets.
Dynamic Value Estimation for Single-Task Multi-Scene Reinforcement Learning
May 25, 2020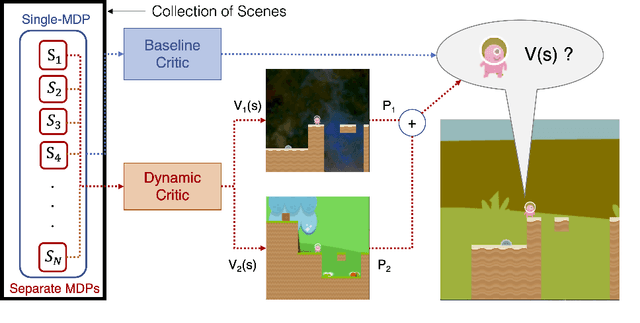
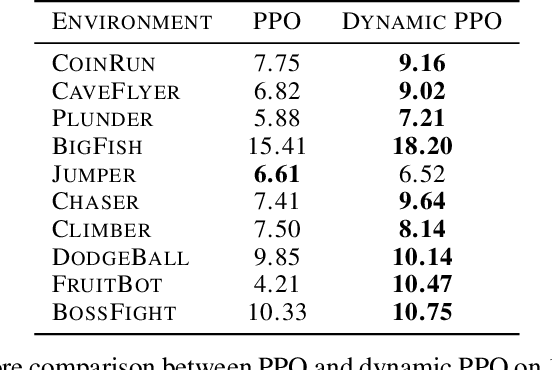
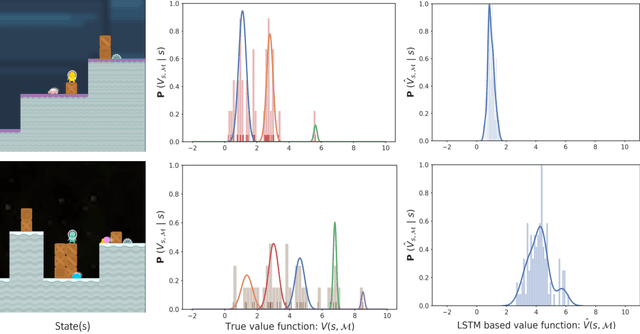
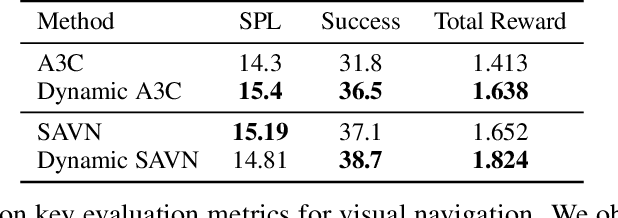
Training deep reinforcement learning agents on environments with multiple levels / scenes / conditions from the same task, has become essential for many applications aiming to achieve generalization and domain transfer from simulation to the real world. While such a strategy is helpful with generalization, the use of multiple scenes significantly increases the variance of samples collected for policy gradient computations. Current methods continue to view this collection of scenes as a single Markov Decision Process (MDP) with a common value function; however, we argue that it is better to treat the collection as a single environment with multiple underlying MDPs. To this end, we propose a dynamic value estimation (DVE) technique for these multiple-MDP environments, motivated by the clustering effect observed in the value function distribution across different scenes. The resulting agent is able to learn a more accurate and scene-specific value function estimate (and hence the advantage function), leading to a lower sample variance. Our proposed approach is simple to accommodate with several existing implementations (like PPO, A3C) and results in consistent improvements for a range of ProcGen environments and the AI2-THOR framework based visual navigation task.