 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Syntacto-Discourse Parsing and the Syntacto-Discourse Treebank
Aug 28, 2017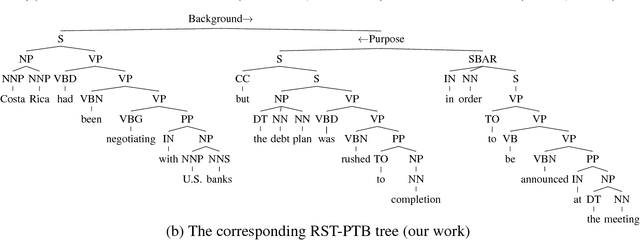
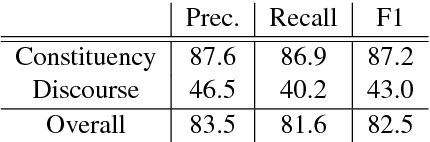
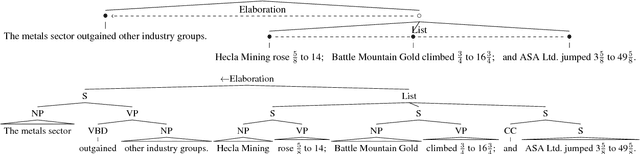

Discourse parsing has long been treated as a stand-alone problem independent from constituency or dependency parsing. Most attempts at this problem are pipelined rather than end-to-end, sophisticated, and not self-contained: they assume gold-standard text segmentations (Elementary Discourse Units), and use external parsers for syntactic features. In this paper we propose the first end-to-end discourse parser that jointly parses in both syntax and discourse levels, as well as the first syntacto-discourse treebank by integrating the Penn Treebank with the RST Treebank. Built upon our recent span-based constituency parser, this joint syntacto-discourse parser requires no preprocessing whatsoever (such as segmentation or feature extraction), achieves the state-of-the-art end-to-end discourse parsing accuracy.
* Accepted at EMNLP 2017
Textual Entailment with Structured Attentions and Composition
Jan 04, 2017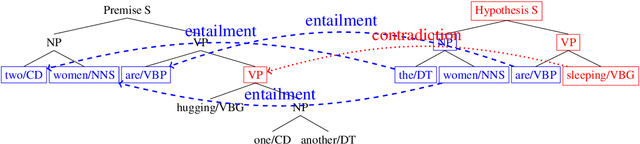
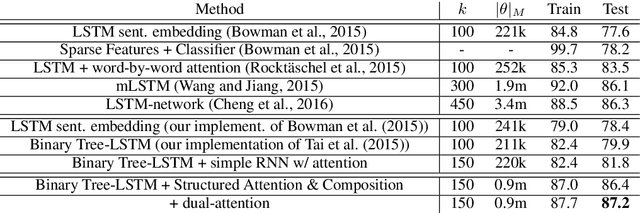
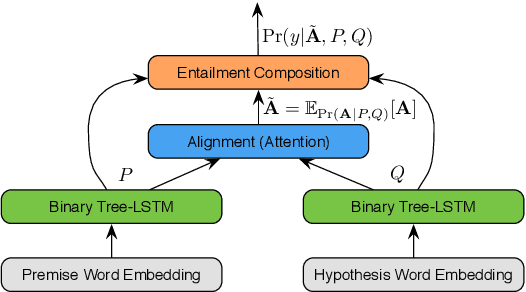
Deep learning techniques are increasingly popular in the textual entailment task, overcoming the fragility of traditional discrete models with hard alignments and logics. In particular, the recently proposed attention models (Rockt\"aschel et al., 2015; Wang and Jiang, 2015) achieves state-of-the-art accuracy by computing soft word alignments between the premise and hypothesis sentences. However, there remains a major limitation: this line of work completely ignores syntax and recursion, which is helpful in many traditional efforts. We show that it is beneficial to extend the attention model to tree nodes between premise and hypothesis. More importantly, this subtree-level attention reveals information about entailment relation. We study the recursive composition of this subtree-level entailment relation, which can be viewed as a soft version of the Natural Logic framework (MacCartney and Manning, 2009). Experiments show that our structured attention and entailment composition model can correctly identify and infer entailment relations from the bottom up, and bring significant improvements in accuracy.
Span-Based Constituency Parsing with a Structure-Label System and Provably Optimal Dynamic Oracles
Dec 20, 2016
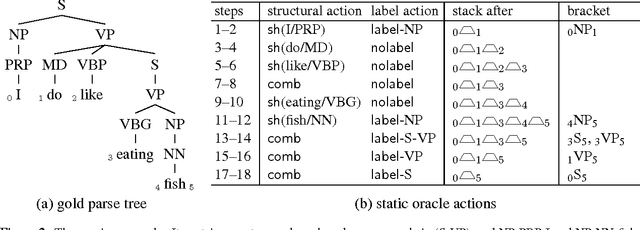

Parsing accuracy using efficient greedy transition systems has improved dramatically in recent years thanks to neural networks. Despite striking results in dependency parsing, however, neural models have not surpassed state-of-the-art approaches in constituency parsing. To remedy this, we introduce a new shift-reduce system whose stack contains merely sentence spans, represented by a bare minimum of LSTM features. We also design the first provably optimal dynamic oracle for constituency parsing, which runs in amortized O(1) time, compared to O(n^3) oracles for standard dependency parsing. Training with this oracle, we achieve the best F1 scores on both English and French of any parser that does not use reranking or external data.
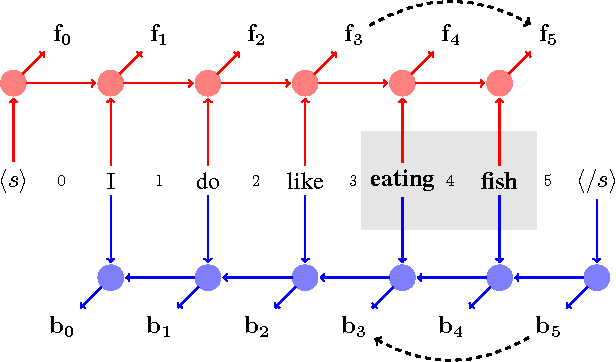
Incremental Parsing with Minimal Features Using Bi-Directional LSTM
Jun 21, 2016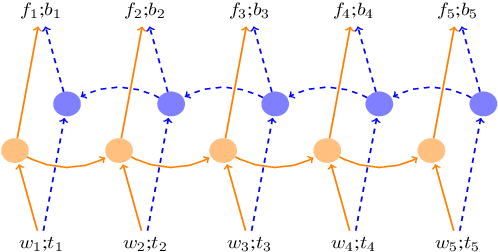

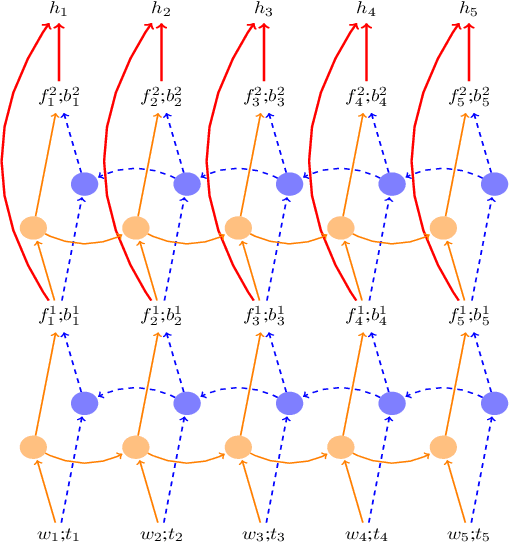
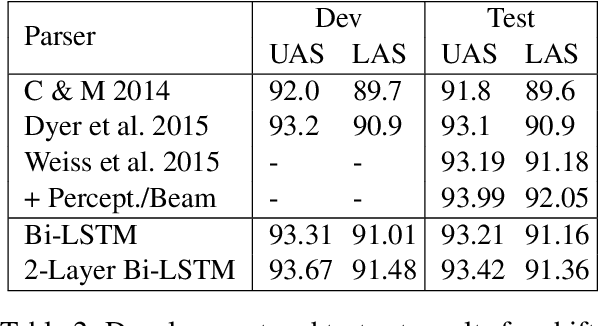
Recently, neural network approaches for parsing have largely automated the combination of individual features, but still rely on (often a larger number of) atomic features created from human linguistic intuition, and potentially omitting important global context. To further reduce feature engineering to the bare minimum, we use bi-directional LSTM sentence representations to model a parser state with only three sentence positions, which automatically identifies important aspects of the entire sentence. This model achieves state-of-the-art results among greedy dependency parsers for English. We also introduce a novel transition system for constituency parsing which does not require binarization, and together with the above architecture, achieves state-of-the-art results among greedy parsers for both English and Chinese.
Dependency-based Convolutional Neural Networks for Sentence Embedding
Aug 03, 2015
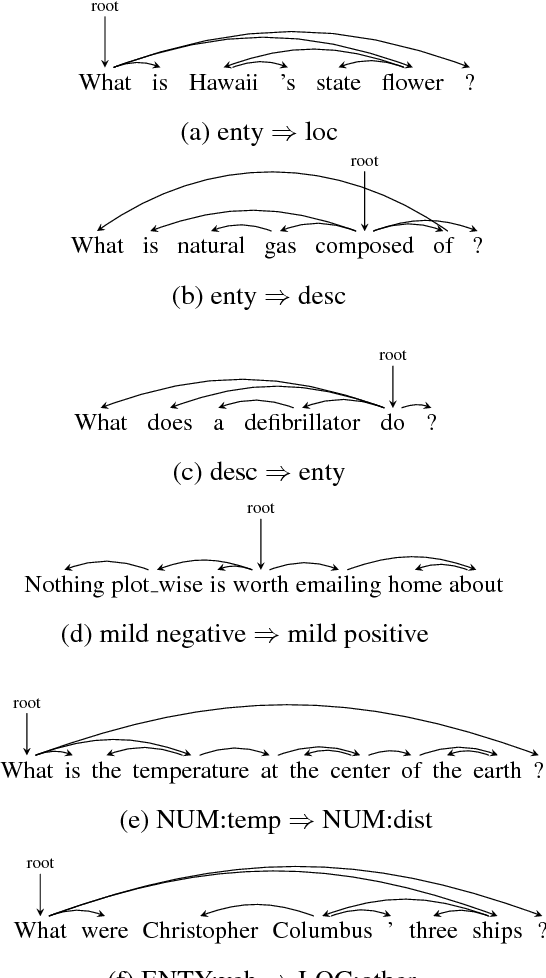
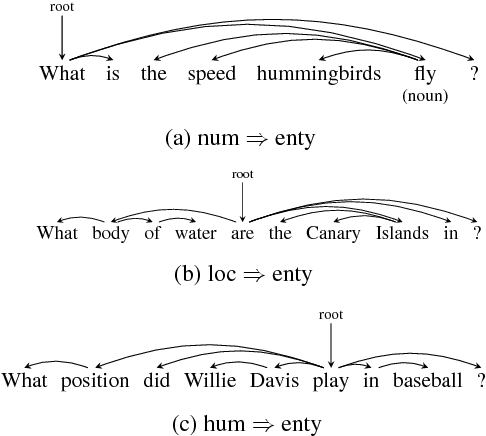
In sentence modeling and classification, convolutional neural network approaches have recently achieved state-of-the-art results, but all such efforts process word vectors sequentially and neglect long-distance dependencies. To exploit both deep learning and linguistic structures, we propose a tree-based convolutional neural network model which exploit various long-distance relationships between words. Our model improves the sequential baselines on all three sentiment and question classification tasks, and achieves the highest published accuracy on TREC.
Type-Driven Incremental Semantic Parsing with Polymorphism
Dec 16, 2014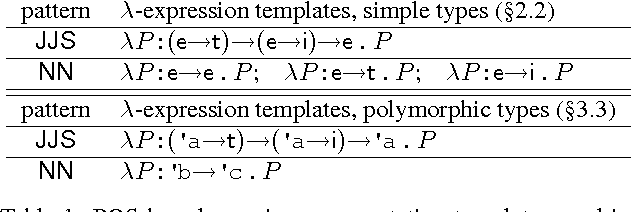
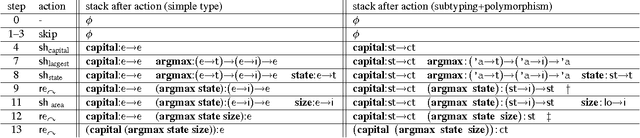
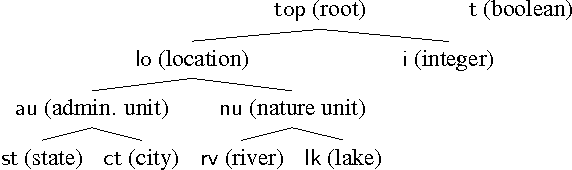
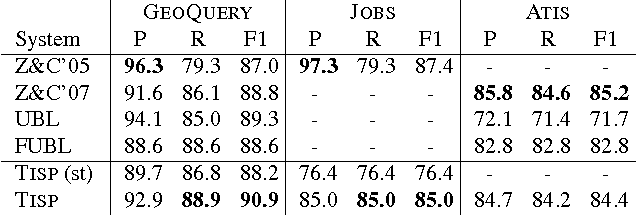
Semantic parsing has made significant progress, but most current semantic parsers are extremely slow (CKY-based) and rather primitive in representation. We introduce three new techniques to tackle these problems. First, we design the first linear-time incremental shift-reduce-style semantic parsing algorithm which is more efficient than conventional cubic-time bottom-up semantic parsers. Second, our parser, being type-driven instead of syntax-driven, uses type-checking to decide the direction of reduction, which eliminates the need for a syntactic grammar such as CCG. Third, to fully exploit the power of type-driven semantic parsing beyond simple types (such as entities and truth values), we borrow from programming language theory the concepts of subtype polymorphism and parametric polymorphism to enrich the type system in order to better guide the parsing. Our system learns very accurate parses in GeoQuery, Jobs and Atis domains.