 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiVPF: Numerical Invertible Volume Preserving Flow for Efficient Lossless Compression
Mar 30, 2021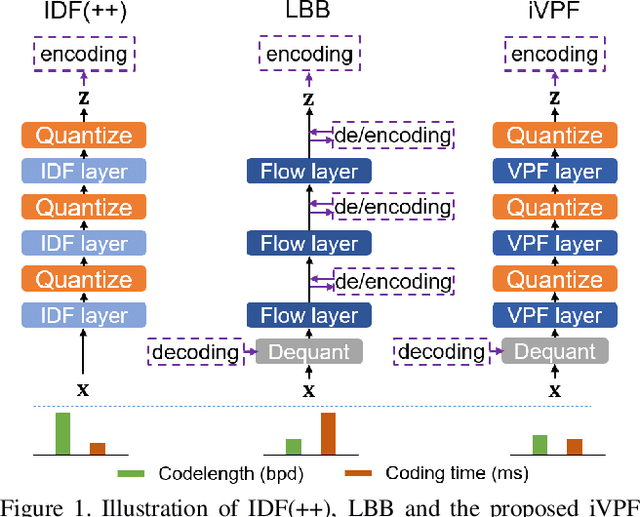
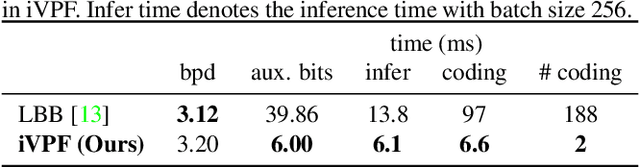

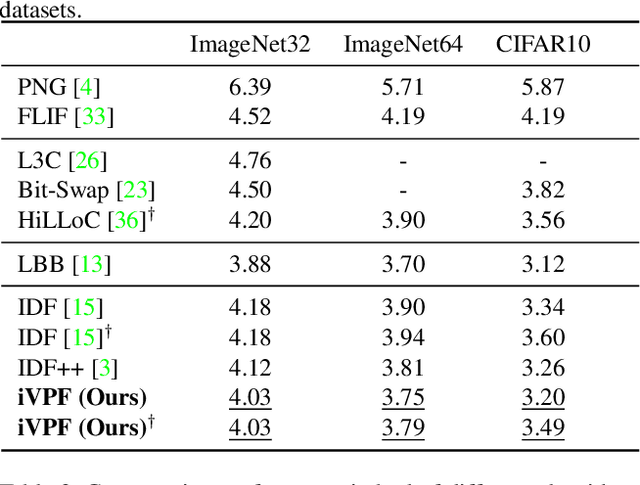
It is nontrivial to store rapidly growing big data nowadays, which demands high-performance lossless compression techniques. Likelihood-based generative models have witnessed their success on lossless compression, where flow based models are desirable in allowing exact data likelihood optimisation with bijective mappings. However, common continuous flows are in contradiction with the discreteness of coding schemes, which requires either 1) imposing strict constraints on flow models that degrades the performance or 2) coding numerous bijective mapping errors which reduces the efficiency. In this paper, we investigate volume preserving flows for lossless compression and show that a bijective mapping without error is possible. We propose Numerical Invertible Volume Preserving Flow (iVPF) which is derived from the general volume preserving flows. By introducing novel computation algorithms on flow models, an exact bijective mapping is achieved without any numerical error. We also propose a lossless compression algorithm based on iVPF. Experiments on various datasets show that the algorithm based on iVPF achieves state-of-the-art compression ratio over lightweight compression algorithms.