 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning From State and Temporal Differences
Dec 23, 2025TD($λ$) with function approximation has proved empirically successful for some complex reinforcement learning problems. For linear approximation, TD($λ$) has been shown to minimise the squared error between the approximate value of each state and the true value. However, as far as policy is concerned, it is error in the relative ordering of states that is critical, rather than error in the state values. We illustrate this point, both in simple two-state and three-state systems in which TD($λ$)--starting from an optimal policy--converges to a sub-optimal policy, and also in backgammon. We then present a modified form of TD($λ$), called STD($λ$), in which function approximators are trained with respect to relative state values on binary decision problems. A theoretical analysis, including a proof of monotonic policy improvement for STD($λ$) in the context of the two-state system, is presented, along with a comparison with Bertsekas' differential training method [1]. This is followed by successful demonstrations of STD($λ$) on the two-state system and a variation on the well known acrobot problem.
The Optimal Reward Baseline for Gradient-Based Reinforcement Learning
Jan 10, 2013



There exist a number of reinforcement learning algorithms which learnby climbing the gradient of expected reward. Their long-runconvergence has been proved, even in partially observableenvironments with non-deterministic actions, and without the need fora system model. However, the variance of the gradient estimator hasbeen found to be a significant practical problem. Recent approacheshave discounted future rewards, introducing a bias-variance trade-offinto the gradient estimate. We incorporate a reward baseline into thelearning system, and show that it affects variance without introducingfurther bias. In particular, as we approach the zero-bias,high-variance parameterization, the optimal (or variance minimizing)constant reward baseline is equal to the long-term average expectedreward. Modified policy-gradient algorithms are presented, and anumber of experiments demonstrate their improvement over previous work.
KnightCap: A chess program that learns by combining TD with game-tree search
Jan 10, 1999
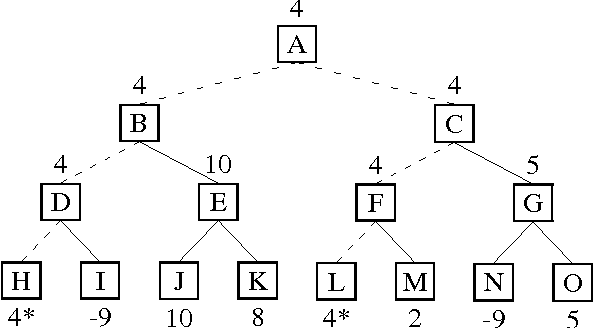


In this paper we present TDLeaf(lambda), a variation on the TD(lambda) algorithm that enables it to be used in conjunction with game-tree search. We present some experiments in which our chess program ``KnightCap'' used TDLeaf(lambda) to learn its evaluation function while playing on the Free Internet Chess Server (FICS, fics.onenet.net). The main success we report is that KnightCap improved from a 1650 rating to a 2150 rating in just 308 games and 3 days of play. As a reference, a rating of 1650 corresponds to about level B human play (on a scale from E (1000) to A (1800)), while 2150 is human master level. We discuss some of the reasons for this success, principle among them being the use of on-line, rather than self-play.
* 9 pages
TDLeaf(lambda): Combining Temporal Difference Learning with Game-Tree Search
Jan 05, 1999
In this paper we present TDLeaf(lambda), a variation on the TD(lambda) algorithm that enables it to be used in conjunction with minimax search. We present some experiments in both chess and backgammon which demonstrate its utility and provide comparisons with TD(lambda) and another less radical variant, TD-directed(lambda). In particular, our chess program, ``KnightCap,'' used TDLeaf(lambda) to learn its evaluation function while playing on the Free Internet Chess Server (FICS, fics.onenet.net). It improved from a 1650 rating to a 2100 rating in just 308 games. We discuss some of the reasons for this success and the relationship between our results and Tesauro's results in backgammon.
* 5 pages. Also in Proceedings of the Ninth Australian Conference on Neural Networks (ACNN'98), Brisbane QLD, February 1998, pages 168-172
Evolution of Neural Networks to Play the Game of Dots-and-Boxes
Sep 28, 1998

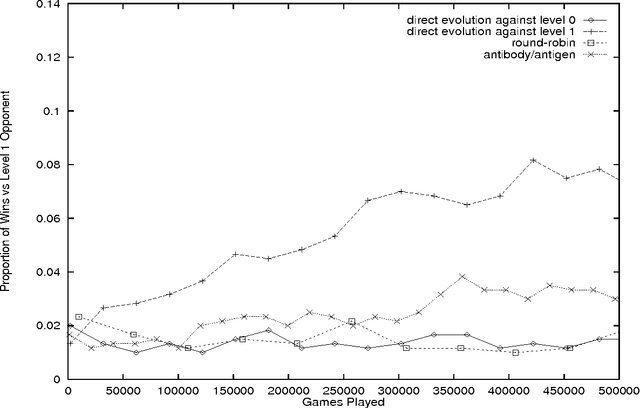

Dots-and-Boxes is a child's game which remains analytically unsolved. We implement and evolve artificial neural networks to play this game, evaluating them against simple heuristic players. Our networks do not evaluate or predict the final outcome of the game, but rather recommend moves at each stage. Superior generalisation of play by co-evolved populations is found, and a comparison made with networks trained by back-propagation using simple heuristics as an oracle.
* 8 pages, 5 figures, LaTeX 2.09 (works with LaTeX2e)