 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Compression with Generative Adversarial Networks
Dec 05, 2018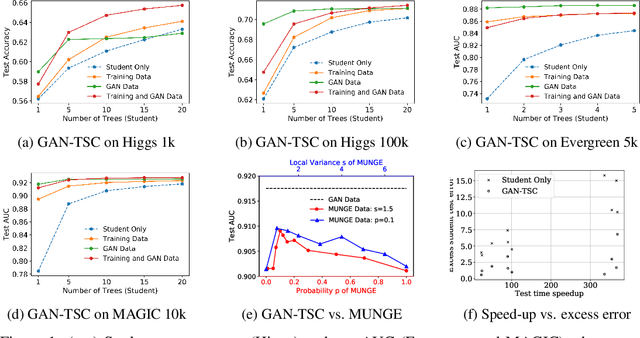

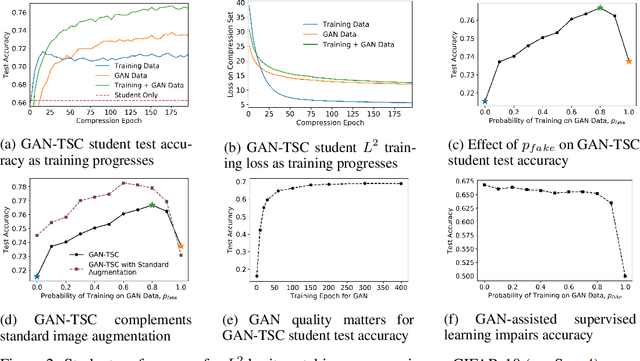

More accurate machine learning models often demand more computation and memory at test time, making them difficult to deploy on CPU- or memory-constrained devices. Model compression (also known as distillation) alleviates this burden by training a less expensive student model to mimic the expensive teacher model while maintaining most of the original accuracy. However, when fresh data is unavailable for the compression task, the teacher's training data is typically reused, leading to suboptimal compression. In this work, we propose to augment the compression dataset with synthetic data from a generative adversarial network (GAN) designed to approximate the training data distribution. Our GAN-assisted model compression (GAN-MC) significantly improves student accuracy for expensive models such as deep neural networks and large random forests on both image and tabular datasets. Building on these results, we propose a comprehensive metric---the Compression Score---to evaluate the quality of synthetic datasets based on their induced model compression performance. The Compression Score captures both data diversity and discriminability, and we illustrate its benefits over the popular Inception Score in the context of image classification.
Global Non-convex Optimization with Discretized Diffusions
Oct 29, 2018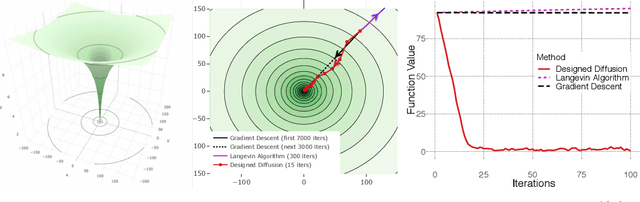
An Euler discretization of the Langevin diffusion is known to converge to the global minimizers of certain convex and non-convex optimization problems. We show that this property holds for any suitably smooth diffusion and that different diffusions are suitable for optimizing different classes of convex and non-convex functions. This allows us to design diffusions suitable for globally optimizing convex and non-convex functions not covered by the existing Langevin theory. Our non-asymptotic analysis delivers computable optimization and integration error bounds based on easily accessed properties of the objective and chosen diffusion. Central to our approach are new explicit Stein factor bounds on the solutions of Poisson equations. We complement these results with improved optimization guarantees for targets other than the standard Gibbs measure.
Random Feature Stein Discrepancies
Oct 27, 2018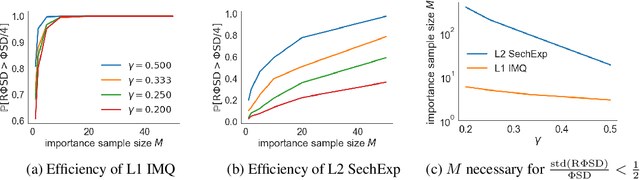
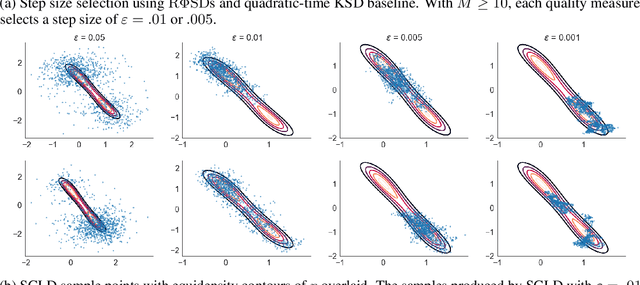
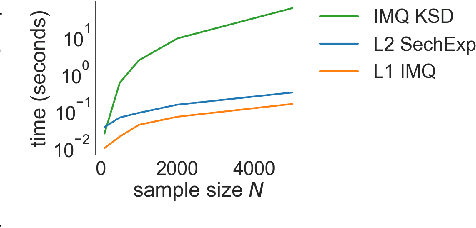
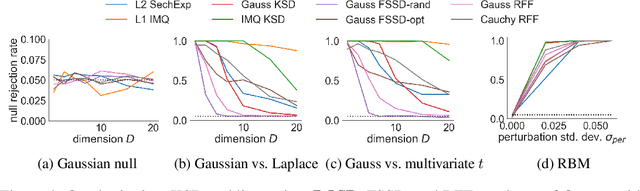
Computable Stein discrepancies have been deployed for a variety of applications, ranging from sampler selection in posterior inference to approximate Bayesian inference to goodness-of-fit testing. Existing convergence-determining Stein discrepancies admit strong theoretical guarantees but suffer from a computational cost that grows quadratically in the sample size. While linear-time Stein discrepancies have been proposed for goodness-of-fit testing, they exhibit avoidable degradations in testing power---even when power is explicitly optimized. To address these shortcomings, we introduce feature Stein discrepancies ($\Phi$SDs), a new family of quality measures that can be cheaply approximated using importance sampling. We show how to construct $\Phi$SDs that provably determine the convergence of a sample to its target and develop high-accuracy approximations---random $\Phi$SDs (R$\Phi$SDs)---which are computable in near-linear time. In our experiments with sampler selection for approximate posterior inference and goodness-of-fit testing, R$\Phi$SDs perform as well or better than quadratic-time KSDs while being orders of magnitude faster to compute.
Improving Subseasonal Forecasting in the Western U.S. with Machine Learning
Sep 19, 2018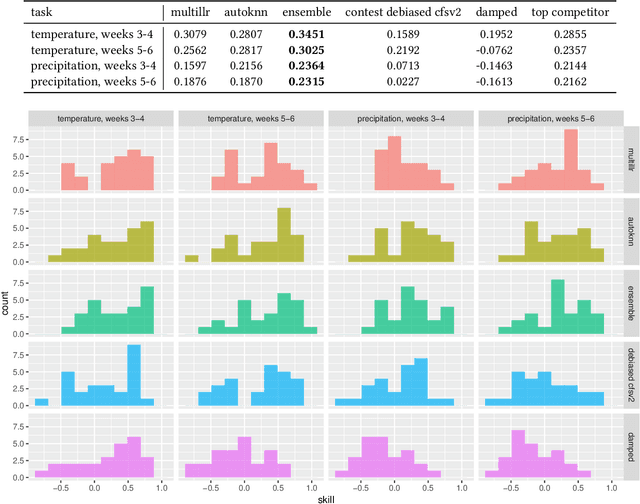
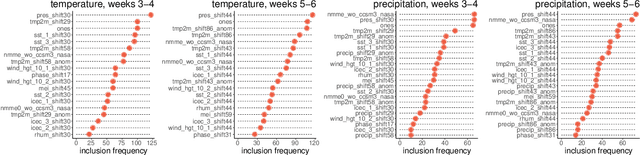
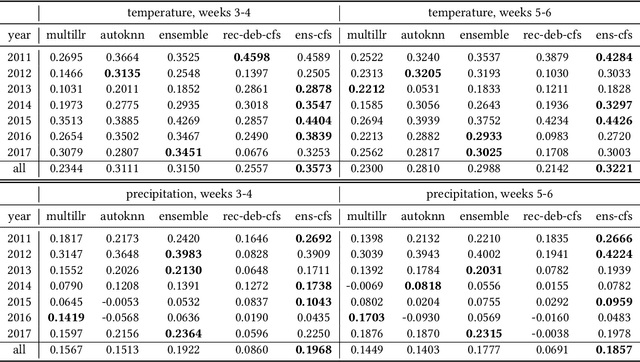
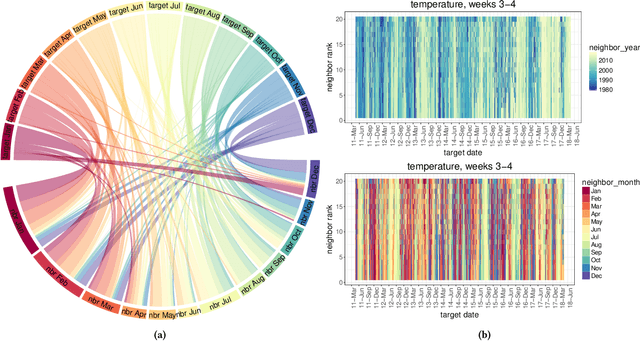
Water managers in the western United States (U.S.) rely on longterm forecasts of temperature and precipitation to prepare for droughts and other wet weather extremes. To improve the accuracy of these longterm forecasts, the Bureau of Reclamation and the National Oceanic and Atmospheric Administration (NOAA) launched the Subseasonal Climate Forecast Rodeo, a year-long real-time forecasting challenge, in which participants aimed to skillfully predict temperature and precipitation in the western U.S. two to four weeks and four to six weeks in advance. Here we present and evaluate our machine learning approach to the Rodeo and release our SubseasonalRodeo dataset, collected to train and evaluate our forecasting system. Our system is an ensemble of two regression models. The first integrates the diverse collection of meteorological measurements and dynamic model forecasts in the SubseasonalRodeo dataset and prunes irrelevant predictors using a customized multitask model selection procedure. The second uses only historical measurements of the target variable (temperature or precipitation) and introduces multitask nearest neighbor features into a weighted local linear regression. Each model alone is significantly more accurate than the operational U.S. Climate Forecasting System (CFSv2), and our ensemble skill exceeds that of the top Rodeo competitor for each target variable and forecast horizon. We hope that both our dataset and our methods will serve as valuable benchmarking tools for the subseasonal forecasting problem.
Orthogonal Machine Learning: Power and Limitations
Aug 01, 2018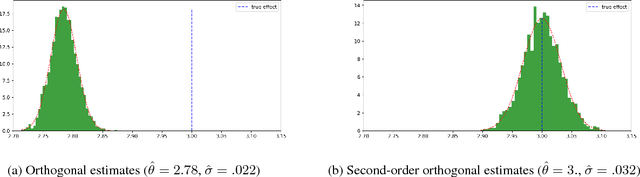
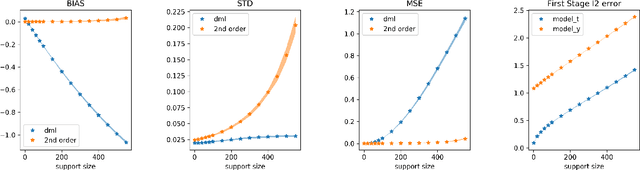
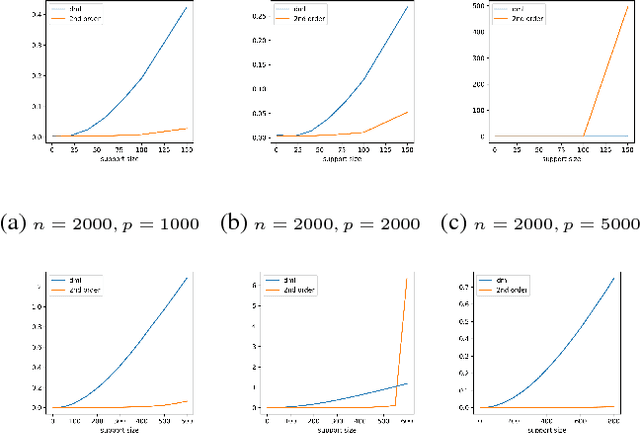
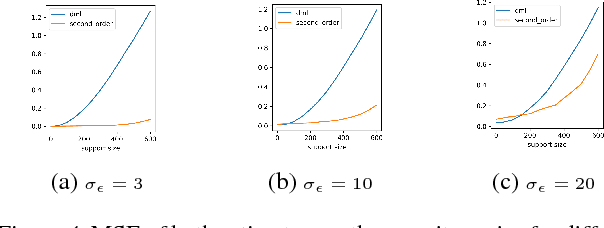
Double machine learning provides $\sqrt{n}$-consistent estimates of parameters of interest even when high-dimensional or nonparametric nuisance parameters are estimated at an $n^{-1/4}$ rate. The key is to employ Neyman-orthogonal moment equations which are first-order insensitive to perturbations in the nuisance parameters. We show that the $n^{-1/4}$ requirement can be improved to $n^{-1/(2k+2)}$ by employing a $k$-th order notion of orthogonality that grants robustness to more complex or higher-dimensional nuisance parameters. In the partially linear regression setting popular in causal inference, we show that we can construct second-order orthogonal moments if and only if the treatment residual is not normally distributed. Our proof relies on Stein's lemma and may be of independent interest. We conclude by demonstrating the robustness benefits of an explicit doubly-orthogonal estimation procedure for treatment effect.
Accurate Inference for Adaptive Linear Models
Jun 20, 2018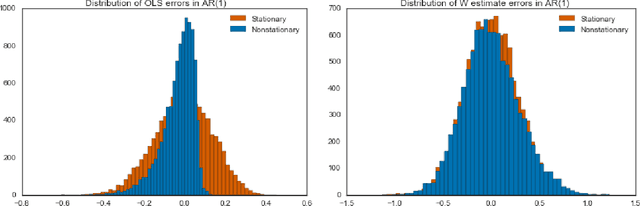
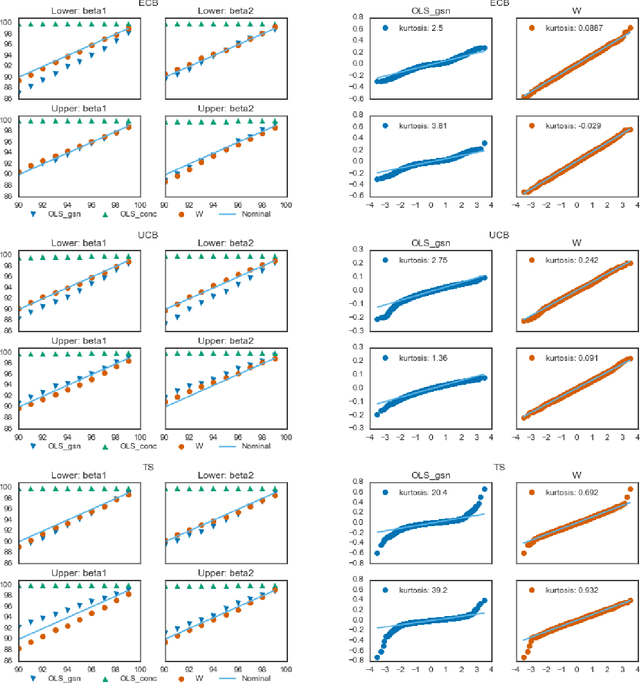
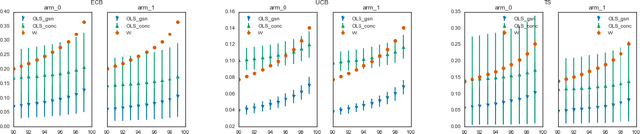
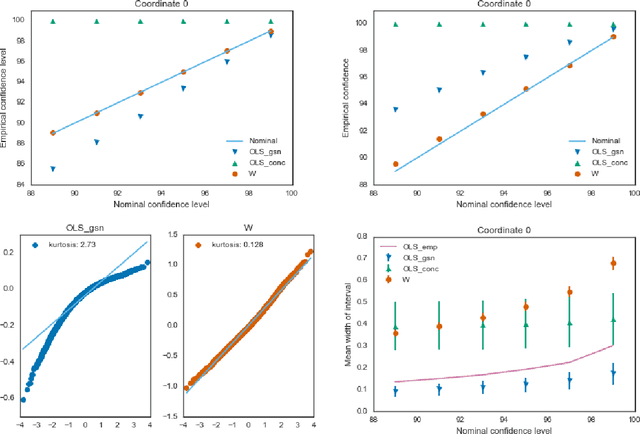
Estimators computed from adaptively collected data do not behave like their non-adaptive brethren. Rather, the sequential dependence of the collection policy can lead to severe distributional biases that persist even in the infinite data limit. We develop a general method -- $\mathbf{W}$-decorrelation -- for transforming the bias of adaptive linear regression estimators into variance. The method uses only coarse-grained information about the data collection policy and does not need access to propensity scores or exact knowledge of the policy. We bound the finite-sample bias and variance of the $\mathbf{W}$-estimator and develop asymptotically correct confidence intervals based on a novel martingale central limit theorem. We then demonstrate the empirical benefits of the generic $\mathbf{W}$-decorrelation procedure in two different adaptive data settings: the multi-armed bandit and the autoregressive time series.
Stein Points
Jun 19, 2018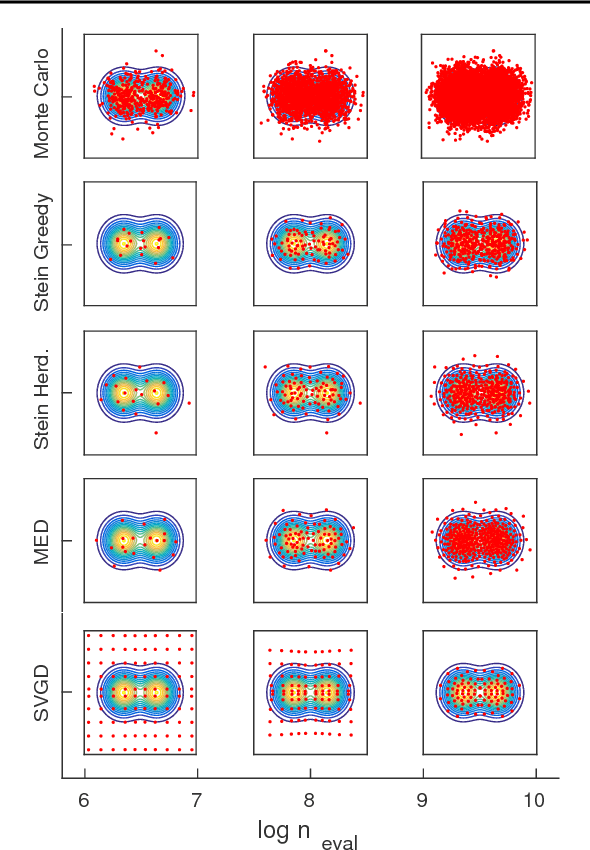
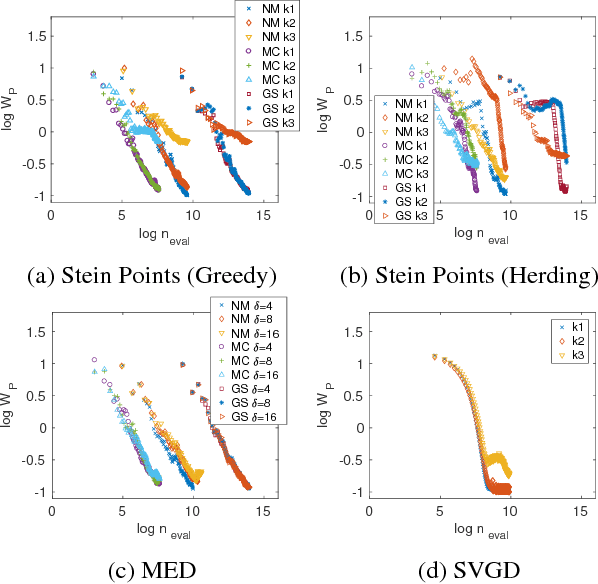
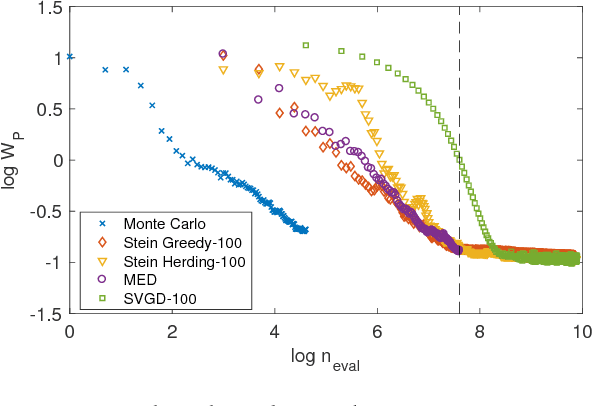
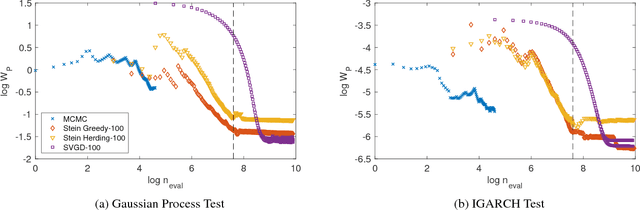
An important task in computational statistics and machine learning is to approximate a posterior distribution $p(x)$ with an empirical measure supported on a set of representative points $\{x_i\}_{i=1}^n$. This paper focuses on methods where the selection of points is essentially deterministic, with an emphasis on achieving accurate approximation when $n$ is small. To this end, we present `Stein Points'. The idea is to exploit either a greedy or a conditional gradient method to iteratively minimise a kernel Stein discrepancy between the empirical measure and $p(x)$. Our empirical results demonstrate that Stein Points enable accurate approximation of the posterior at modest computational cost. In addition, theoretical results are provided to establish convergence of the method.
DeepMiner: Discovering Interpretable Representations for Mammogram Classification and Explanation
May 31, 2018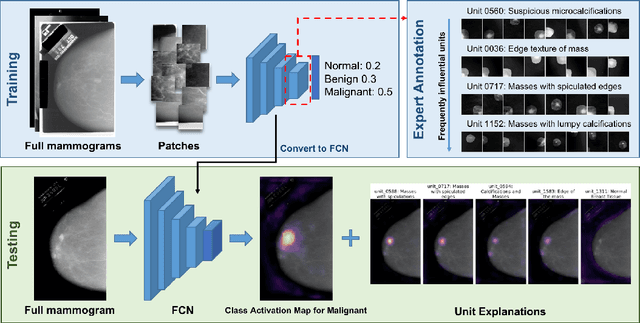

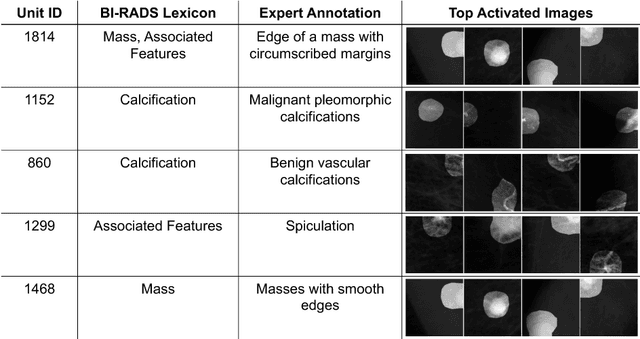
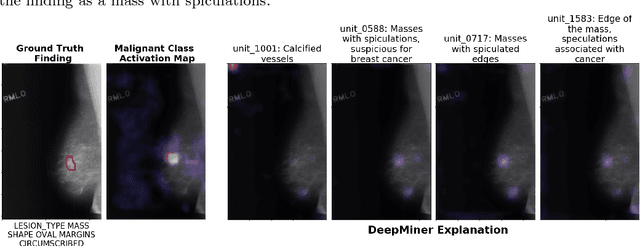
We propose DeepMiner, a framework to discover interpretable representations in deep neural networks and to build explanations for medical predictions. By probing convolutional neural networks (CNNs) trained to classify cancer in mammograms, we show that many individual units in the final convolutional layer of a CNN respond strongly to diseased tissue concepts specified by the BI-RADS lexicon. After expert annotation of the interpretable units, our proposed method is able to generate explanations for CNN mammogram classification that are correlated with ground truth radiology reports on the DDSM dataset. We show that DeepMiner not only enables better understanding of the nuances of CNN classification decisions, but also possibly discovers new visual knowledge relevant to medical diagnosis.
Expert identification of visual primitives used by CNNs during mammogram classification
Mar 13, 2018This work interprets the internal representations of deep neural networks trained for classification of diseased tissue in 2D mammograms. We propose an expert-in-the-loop interpretation method to label the behavior of internal units in convolutional neural networks (CNNs). Expert radiologists identify that the visual patterns detected by the units are correlated with meaningful medical phenomena such as mass tissue and calcificated vessels. We demonstrate that several trained CNN models are able to produce explanatory descriptions to support the final classification decisions. We view this as an important first step toward interpreting the internal representations of medical classification CNNs and explaining their predictions.
Measuring Sample Quality with Diffusions
Feb 21, 2018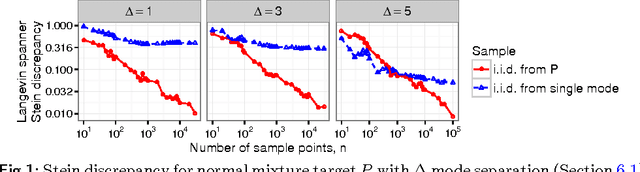
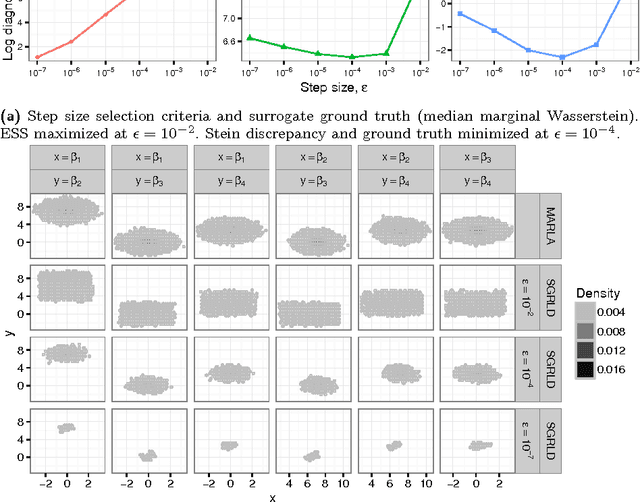
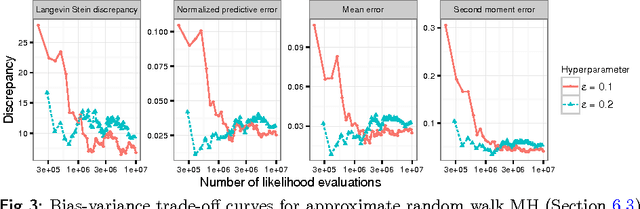
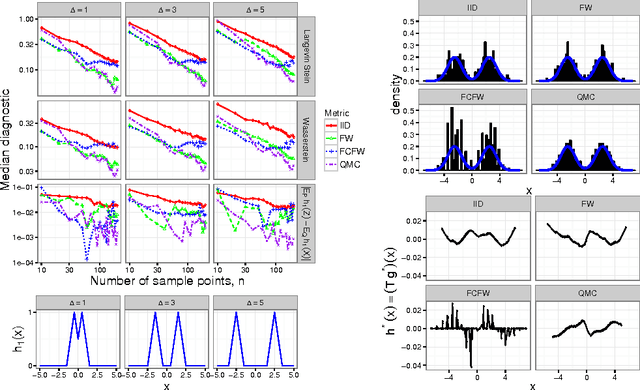
Stein's method for measuring convergence to a continuous target distribution relies on an operator characterizing the target and Stein factor bounds on the solutions of an associated differential equation. While such operators and bounds are readily available for a diversity of univariate targets, few multivariate targets have been analyzed. We introduce a new class of characterizing operators based on Ito diffusions and develop explicit multivariate Stein factor bounds for any target with a fast-coupling Ito diffusion. As example applications, we develop computable and convergence-determining diffusion Stein discrepancies for log-concave, heavy-tailed, and multimodal targets and use these quality measures to select the hyperparameters of biased Markov chain Monte Carlo (MCMC) samplers, compare random and deterministic quadrature rules, and quantify bias-variance tradeoffs in approximate MCMC. Our results establish a near-linear relationship between diffusion Stein discrepancies and Wasserstein distances, improving upon past work even for strongly log-concave targets. The exposed relationship between Stein factors and Markov process coupling may be of independent interest.