 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Benchmarks for Subseasonal Forecasting
Sep 21, 2021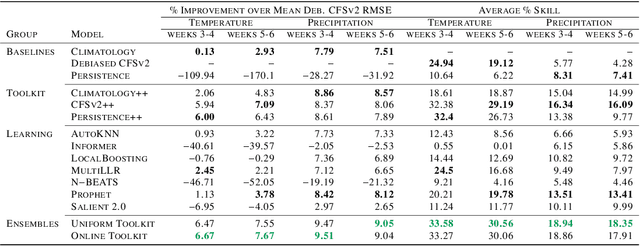
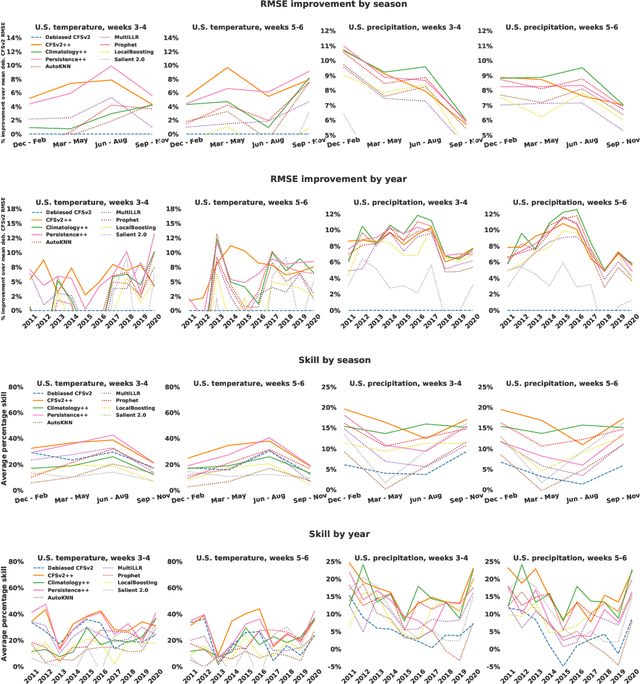
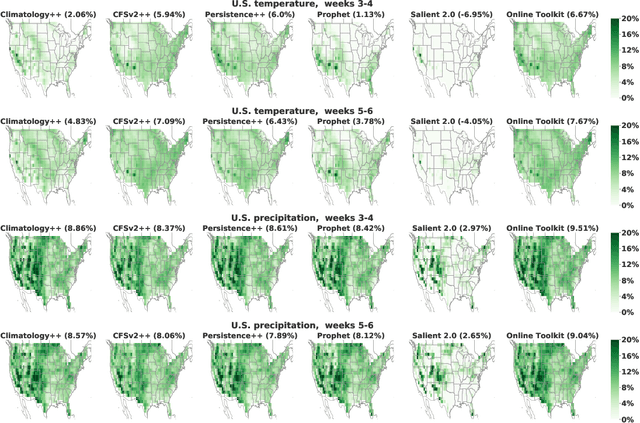
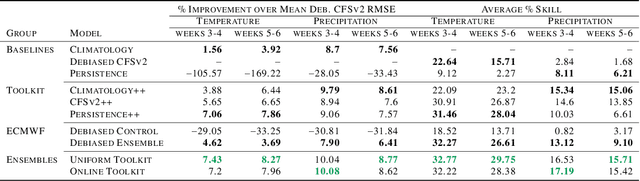
We develop a subseasonal forecasting toolkit of simple learned benchmark models that outperform both operational practice and state-of-the-art machine learning and deep learning methods. Our new models include (a) Climatology++, an adaptive alternative to climatology that, for precipitation, is 9% more accurate and 250% more skillful than the United States operational Climate Forecasting System (CFSv2); (b) CFSv2++, a learned CFSv2 correction that improves temperature and precipitation accuracy by 7-8% and skill by 50-275%; and (c) Persistence++, an augmented persistence model that combines CFSv2 forecasts with lagged measurements to improve temperature and precipitation accuracy by 6-9% and skill by 40-130%. Across the contiguous U.S., our Climatology++, CFSv2++, and Persistence++ toolkit consistently outperforms standard meteorological baselines, state-of-the-art machine and deep learning methods, and the European Centre for Medium-Range Weather Forecasts ensemble. Overall, we find that augmenting traditional forecasting approaches with learned enhancements yields an effective and computationally inexpensive strategy for building the next generation of subseasonal forecasting benchmarks.
Social Norm Bias: Residual Harms of Fairness-Aware Algorithms
Aug 29, 2021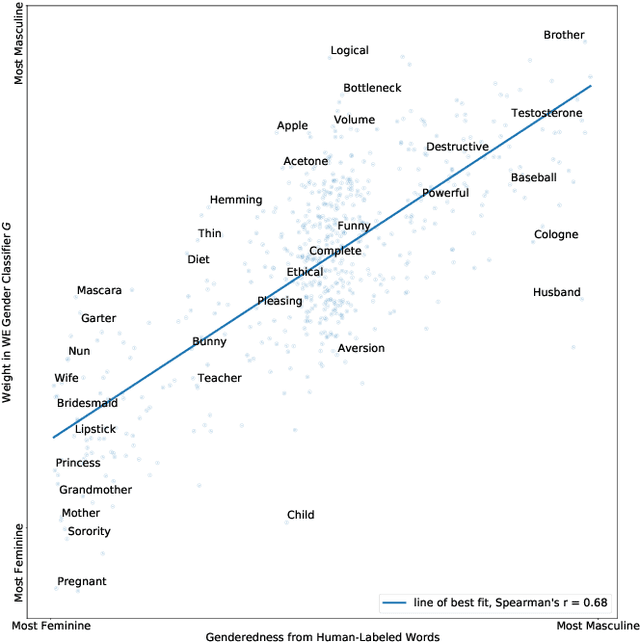
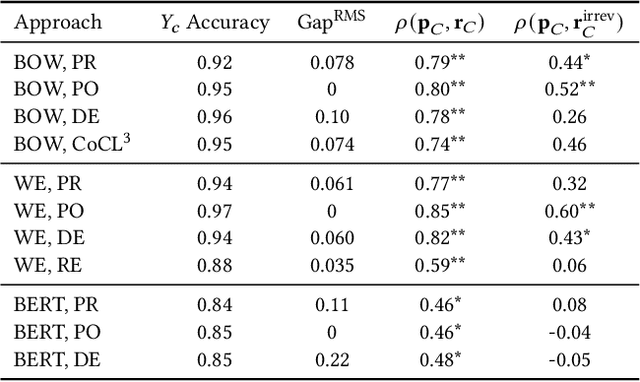
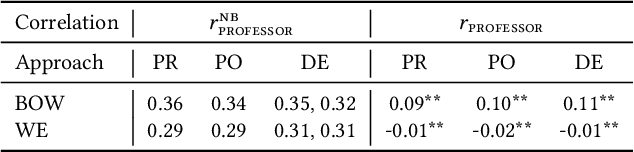
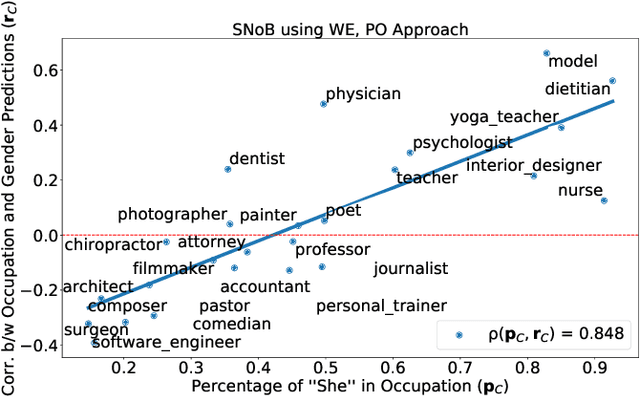
Many modern learning algorithms mitigate bias by enforcing fairness across coarsely-defined groups related to a sensitive attribute like gender or race. However, the same algorithms seldom account for the within-group biases that arise due to the heterogeneity of group members. In this work, we characterize Social Norm Bias (SNoB), a subtle but consequential type of discrimination that may be exhibited by automated decision-making systems, even when these systems achieve group fairness objectives. We study this issue through the lens of gender bias in occupation classification from biographies. We quantify SNoB by measuring how an algorithm's predictions are associated with conformity to gender norms, which is measured using a machine learning approach. This framework reveals that for classification tasks related to male-dominated occupations, fairness-aware classifiers favor biographies written in ways that align with masculine gender norms. We compare SNoB across fairness intervention techniques and show that post-processing interventions do not mitigate this type of bias at all.
Near-optimal inference in adaptive linear regression
Jul 14, 2021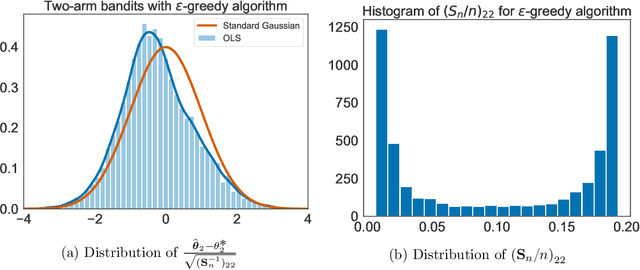
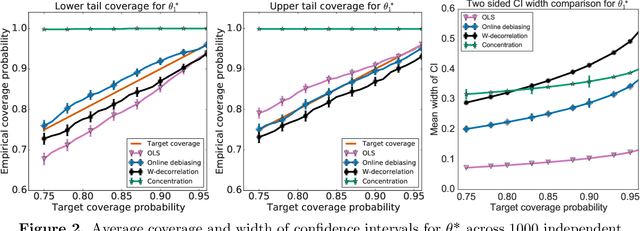
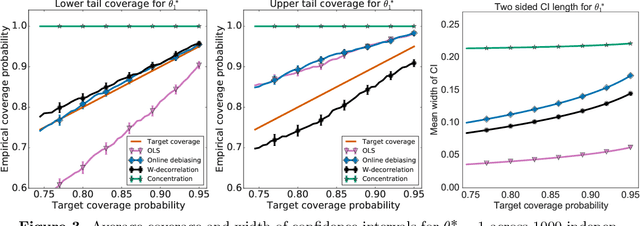
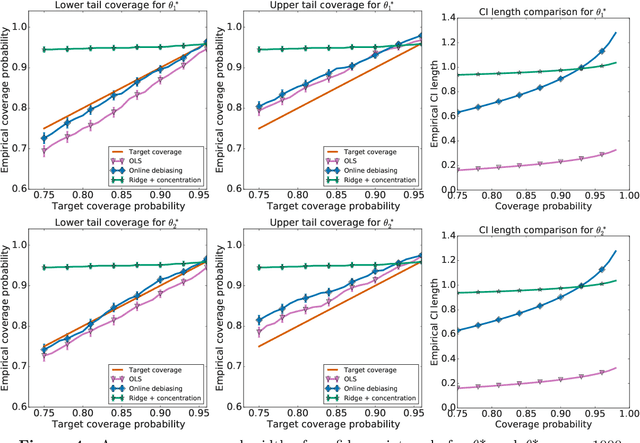
When data is collected in an adaptive manner, even simple methods like ordinary least squares can exhibit non-normal asymptotic behavior. As an undesirable consequence, hypothesis tests and confidence intervals based on asymptotic normality can lead to erroneous results. We propose an online debiasing estimator to correct these distributional anomalies in least squares estimation. Our proposed method takes advantage of the covariance structure present in the dataset and provides sharper estimates in directions for which more information has accrued. We establish an asymptotic normality property for our proposed online debiasing estimator under mild conditions on the data collection process, and provide asymptotically exact confidence intervals. We additionally prove a minimax lower bound for the adaptive linear regression problem, thereby providing a baseline by which to compare estimators. There are various conditions under which our proposed estimator achieves the minimax lower bound up to logarithmic factors. We demonstrate the usefulness of our theory via applications to multi-armed bandit, autoregressive time series estimation, and active learning with exploration.
Online Learning with Optimism and Delay
Jul 12, 2021
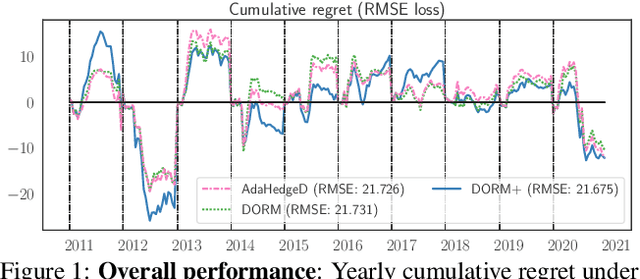
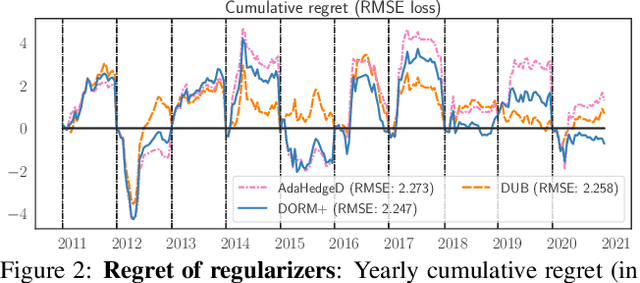

Inspired by the demands of real-time climate and weather forecasting, we develop optimistic online learning algorithms that require no parameter tuning and have optimal regret guarantees under delayed feedback. Our algorithms -- DORM, DORM+, and AdaHedgeD -- arise from a novel reduction of delayed online learning to optimistic online learning that reveals how optimistic hints can mitigate the regret penalty caused by delay. We pair this delay-as-optimism perspective with a new analysis of optimistic learning that exposes its robustness to hinting errors and a new meta-algorithm for learning effective hinting strategies in the presence of delay. We conclude by benchmarking our algorithms on four subseasonal climate forecasting tasks, demonstrating low regret relative to state-of-the-art forecasting models.
Sampling with Mirrored Stein Operators
Jun 23, 2021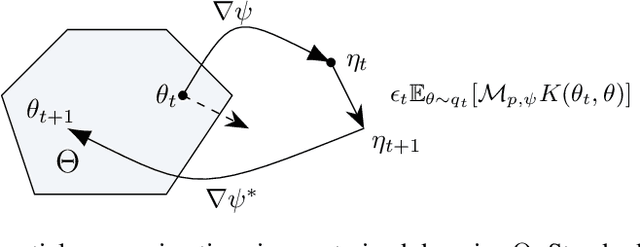
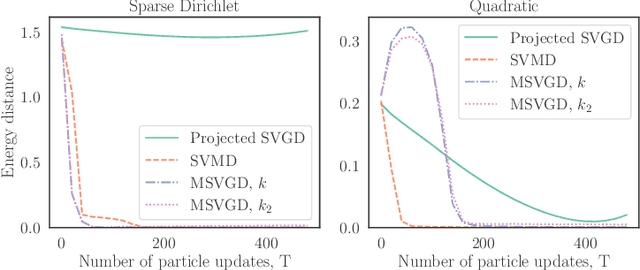
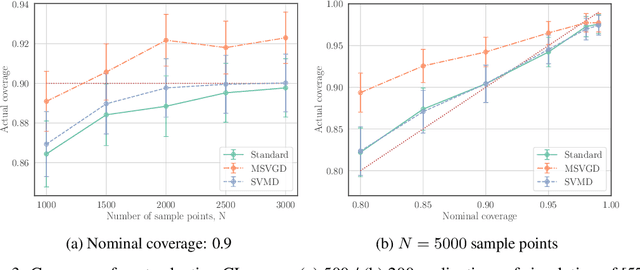
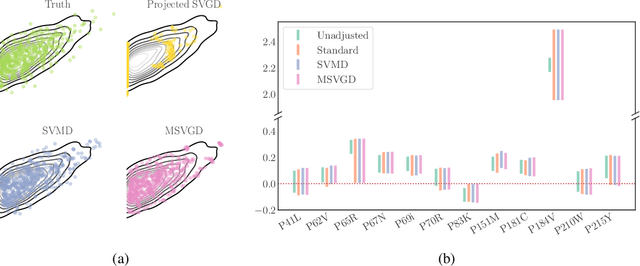
We introduce a new family of particle evolution samplers suitable for constrained domains and non-Euclidean geometries. Stein Variational Mirror Descent and Mirrored Stein Variational Gradient Descent minimize the Kullback-Leibler (KL) divergence to constrained target distributions by evolving particles in a dual space defined by a mirror map. Stein Variational Natural Gradient exploits non-Euclidean geometry to more efficiently minimize the KL divergence to unconstrained targets. We derive these samplers from a new class of mirrored Stein operators and adaptive kernels developed in this work. We demonstrate that these new samplers yield accurate approximations to distributions on the simplex, deliver valid confidence intervals in post-selection inference, and converge more rapidly than prior methods in large-scale unconstrained posterior inference. Finally, we establish the convergence of our new procedures under verifiable conditions on the target distribution.
Kernel Thinning
May 17, 2021
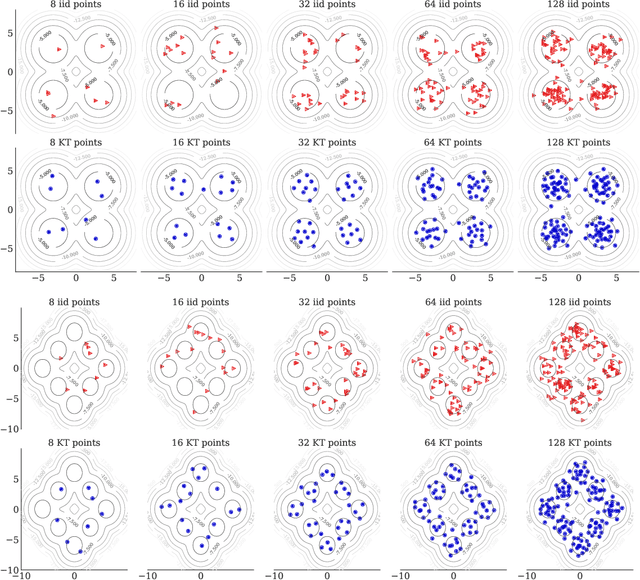
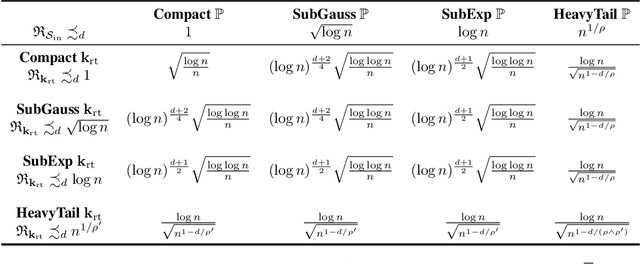
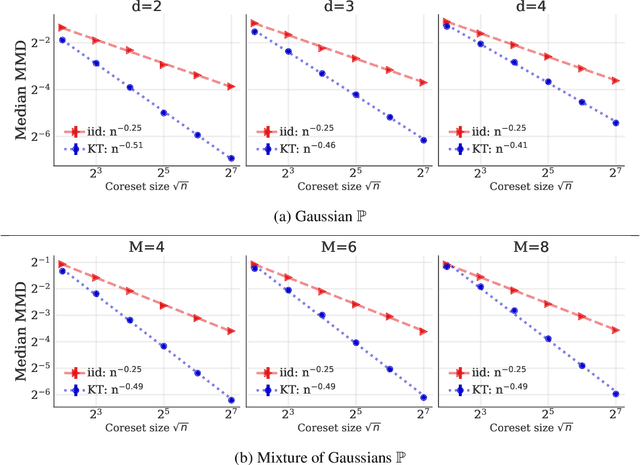
We introduce kernel thinning, a new procedure for compressing a distribution $\mathbb{P}$ more effectively than i.i.d. sampling or standard thinning. Given a suitable reproducing kernel $\mathbf{k}$ and $\mathcal{O}(n^2)$ time, kernel thinning compresses an $n$-point approximation to $\mathbb{P}$ into a $\sqrt{n}$-point approximation with comparable worst-case integration error in the associated reproducing kernel Hilbert space. With high probability, the maximum discrepancy in integration error is $\mathcal{O}_d(n^{-\frac{1}{2}}\sqrt{\log n})$ for compactly supported $\mathbb{P}$ and $\mathcal{O}_d(n^{-\frac{1}{2}} \sqrt{(\log n)^{d+1}\log\log n})$ for sub-exponential $\mathbb{P}$ on $\mathbb{R}^d$. In contrast, an equal-sized i.i.d. sample from $\mathbb{P}$ suffers $\Omega(n^{-\frac14})$ integration error. Our sub-exponential guarantees resemble the classical quasi-Monte Carlo error rates for uniform $\mathbb{P}$ on $[0,1]^d$ but apply to general distributions on $\mathbb{R}^d$ and a wide range of common kernels. We use our results to derive explicit non-asymptotic maximum mean discrepancy bounds for Gaussian, Mat\'ern, and B-spline kernels and present two vignettes illustrating the practical benefits of kernel thinning over i.i.d. sampling and standard Markov chain Monte Carlo thinning.
Initialization and Regularization of Factorized Neural Layers
May 03, 2021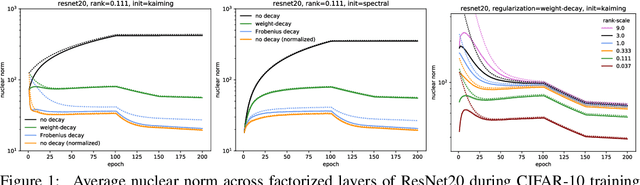
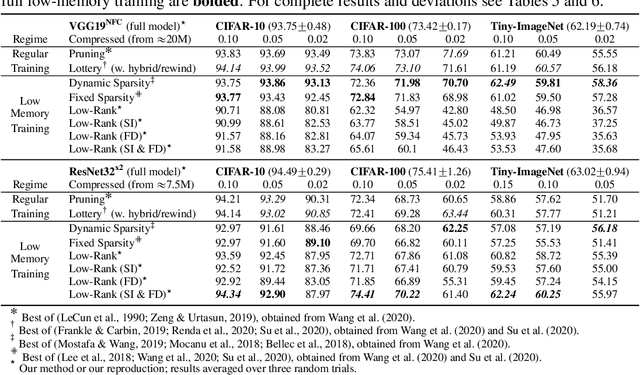
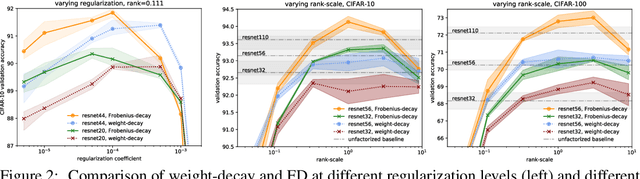
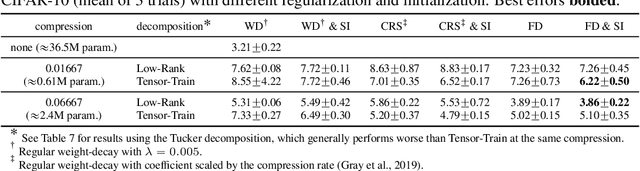
Factorized layers--operations parameterized by products of two or more matrices--occur in a variety of deep learning contexts, including compressed model training, certain types of knowledge distillation, and multi-head self-attention architectures. We study how to initialize and regularize deep nets containing such layers, examining two simple, understudied schemes, spectral initialization and Frobenius decay, for improving their performance. The guiding insight is to design optimization routines for these networks that are as close as possible to that of their well-tuned, non-decomposed counterparts; we back this intuition with an analysis of how the initialization and regularization schemes impact training with gradient descent, drawing on modern attempts to understand the interplay of weight-decay and batch-normalization. Empirically, we highlight the benefits of spectral initialization and Frobenius decay across a variety of settings. In model compression, we show that they enable low-rank methods to significantly outperform both unstructured sparsity and tensor methods on the task of training low-memory residual networks; analogs of the schemes also improve the performance of tensor decomposition techniques. For knowledge distillation, Frobenius decay enables a simple, overcomplete baseline that yields a compact model from over-parameterized training without requiring retraining with or pruning a teacher network. Finally, we show how both schemes applied to multi-head attention lead to improved performance on both translation and unsupervised pre-training.
Knowledge Distillation as Semiparametric Inference
Apr 20, 2021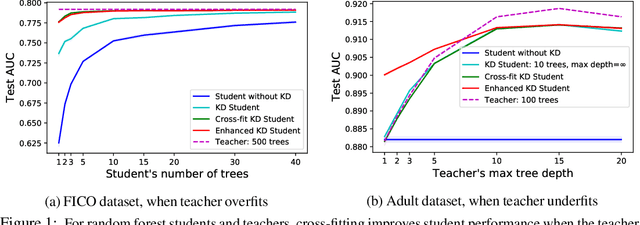

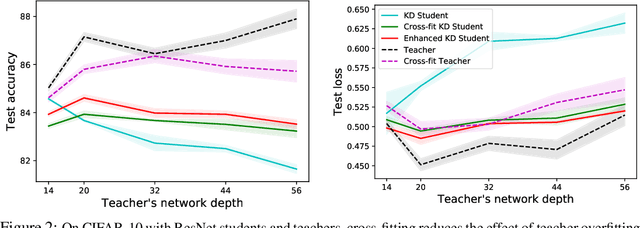
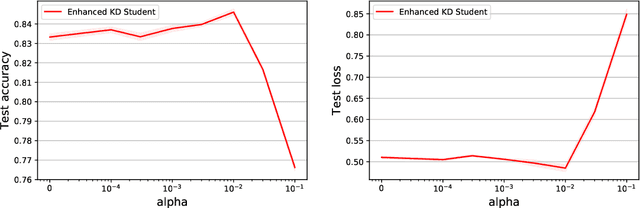
A popular approach to model compression is to train an inexpensive student model to mimic the class probabilities of a highly accurate but cumbersome teacher model. Surprisingly, this two-step knowledge distillation process often leads to higher accuracy than training the student directly on labeled data. To explain and enhance this phenomenon, we cast knowledge distillation as a semiparametric inference problem with the optimal student model as the target, the unknown Bayes class probabilities as nuisance, and the teacher probabilities as a plug-in nuisance estimate. By adapting modern semiparametric tools, we derive new guarantees for the prediction error of standard distillation and develop two enhancements -- cross-fitting and loss correction -- to mitigate the impact of teacher overfitting and underfitting on student performance. We validate our findings empirically on both tabular and image data and observe consistent improvements from our knowledge distillation enhancements.
Model-specific Data Subsampling with Influence Functions
Oct 20, 2020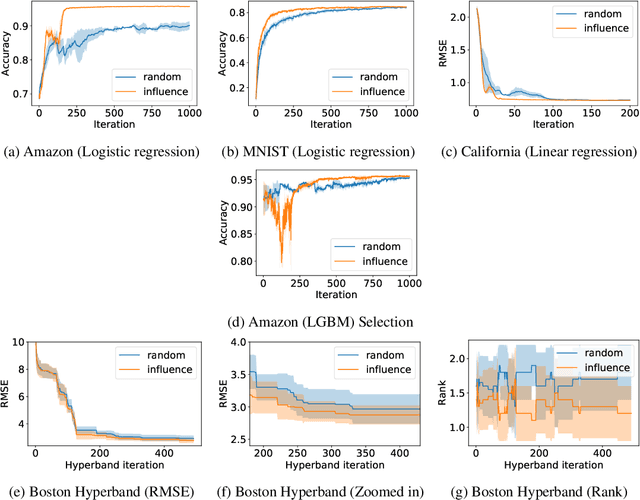
Model selection requires repeatedly evaluating models on a given dataset and measuring their relative performances. In modern applications of machine learning, the models being considered are increasingly more expensive to evaluate and the datasets of interest are increasing in size. As a result, the process of model selection is time-consuming and computationally inefficient. In this work, we develop a model-specific data subsampling strategy that improves over random sampling whenever training points have varying influence. Specifically, we leverage influence functions to guide our selection strategy, proving theoretically, and demonstrating empirically that our approach quickly selects high-quality models.
Independent finite approximations for Bayesian nonparametric inference: construction, error bounds, and practical implications
Sep 22, 2020
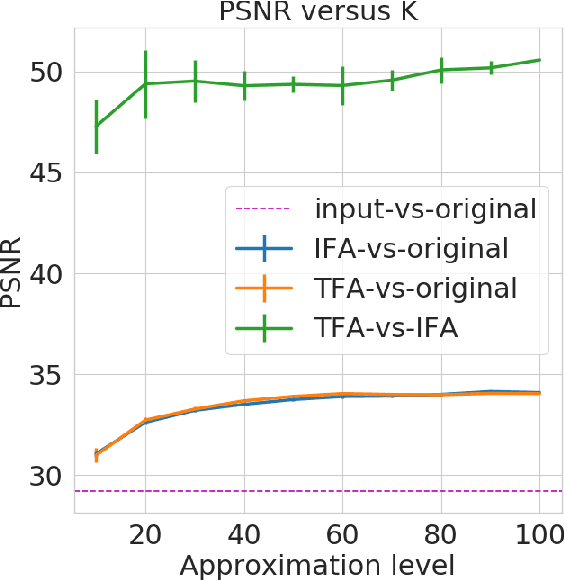
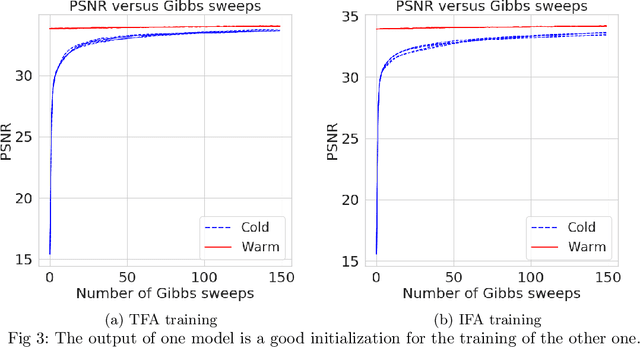
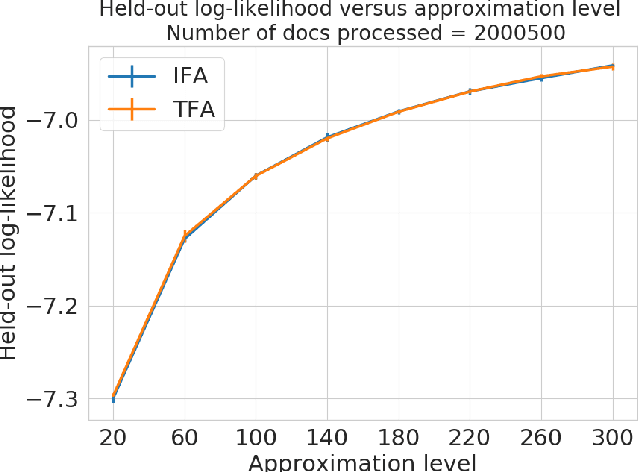
Bayesian nonparametrics based on completely random measures (CRMs) offers a flexible modeling approach when the number of clusters or latent components in a dataset is unknown. However, managing the infinite dimensionality of CRMs often leads to slow computation. Practical inference typically relies on either integrating out the infinite-dimensional parameter or using a finite approximation: a truncated finite approximation (TFA) or an independent finite approximation (IFA). The atom weights of TFAs are constructed sequentially, while the atoms of IFAs are independent, which (1) make them well-suited for parallel and distributed computation and (2) facilitates more convenient inference schemes. While IFAs have been developed in certain special cases in the past, there has not yet been a general template for construction or a systematic comparison to TFAs. We show how to construct IFAs for approximating distributions in a large family of CRMs, encompassing all those typically used in practice. We quantify the approximation error between IFAs and the target nonparametric prior, and prove that, in the worst-case, TFAs provide more component-efficient approximations than IFAs. However, in experiments on image denoising and topic modeling tasks with real data, we find that the error of Bayesian approximation methods overwhelms any finite approximation error, and IFAs perform very similarly to TFAs.