 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Bayesian Imitation Learning with Logic over Programs
Apr 12, 2019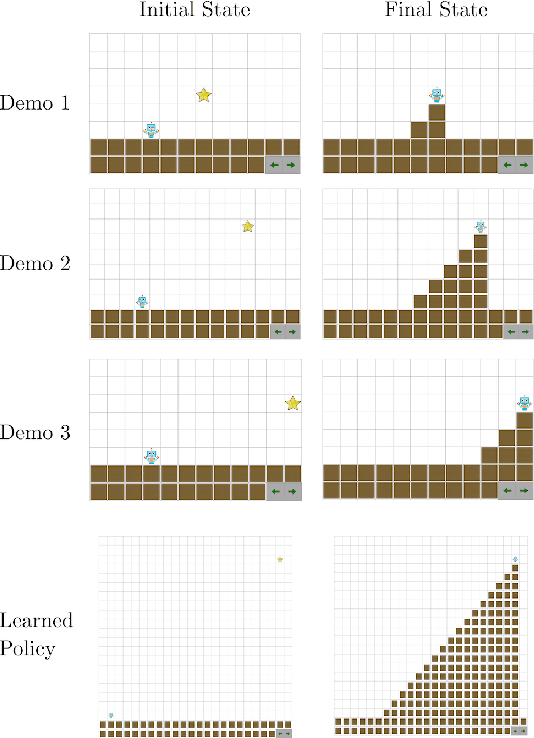



We describe an expressive class of policies that can be efficiently learned from a few demonstrations. Policies are represented as logical combinations of programs drawn from a small domain-specific language (DSL). We define a prior over policies with a probabilistic grammar and derive an approximate Bayesian inference algorithm to learn policies from demonstrations. In experiments, we study five strategy games played on a 2D grid with one shared DSL. After a few demonstrations of each game, the inferred policies generalize to new game instances that differ substantially from the demonstrations. We argue that the proposed method is an apt choice for policy learning tasks that have scarce training data and feature significant, structured variation between task instances.
Every Local Minimum is a Global Minimum of an Induced Model
Apr 07, 2019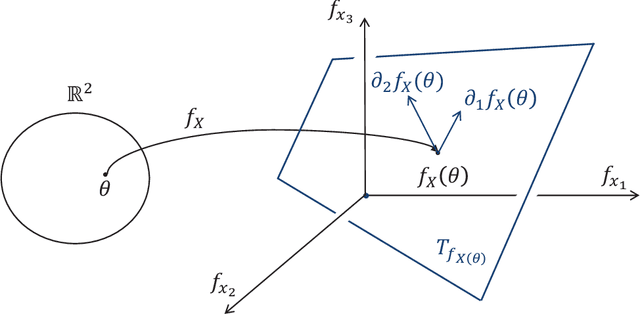
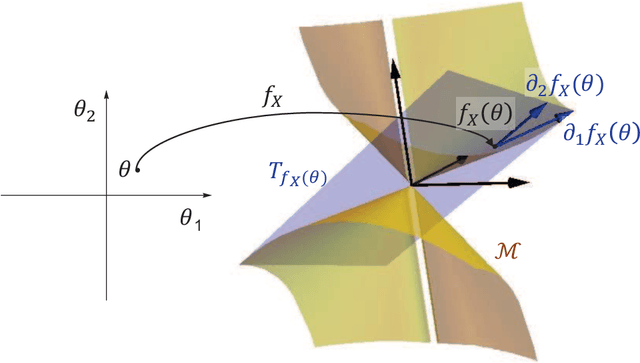
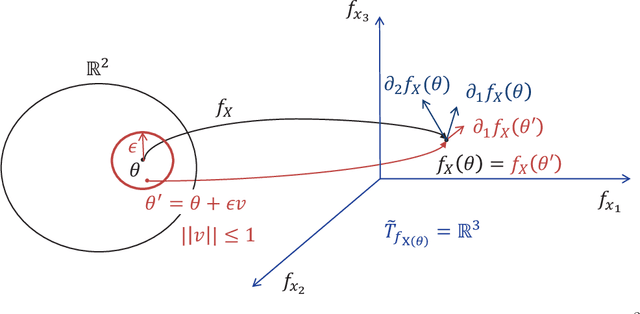
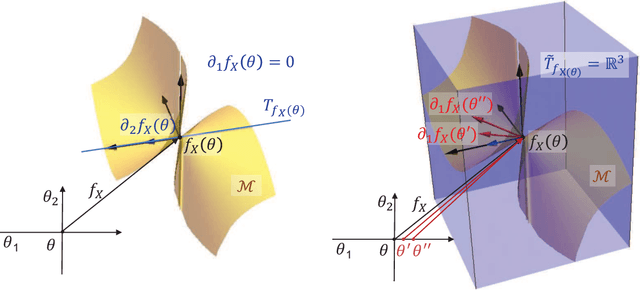
For non-convex optimization in machine learning, this paper proves that every local minimum achieves the global optimality of the perturbable gradient basis model at any differentiable point. As a result, non-convex machine learning is theoretically as supported as convex machine learning with a hand-crafted basis in terms of the loss at differentiable local minima, except in the case when a preference is given to the hand-crafted basis over the perturbable gradient basis. The proofs of these results are derived under mild assumptions. Accordingly, the proven results are directly applicable to many machine learning models, including practical deep neural networks, without any modification of practical methods. Furthermore, as special cases of our general results, this paper improves or complements several state-of-the-art theoretical results in the literature with a simple and unified proof technique.
STRIPStream: Integrating Symbolic Planners and Blackbox Samplers
Feb 27, 2019
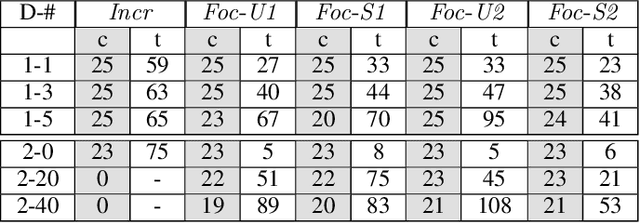
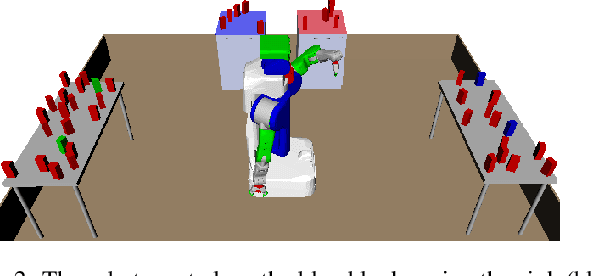
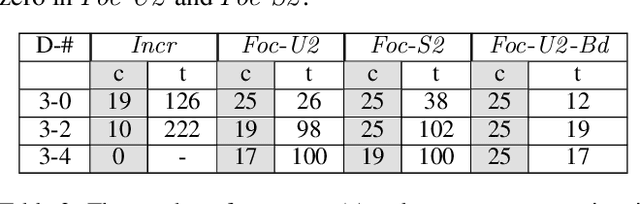
Many planning applications involve complex relationships defined on high-dimensional, continuous variables. For example, robotic manipulation requires planning with kinematic, collision, visibility, and motion constraints involving robot configurations, object transforms, and robot trajectories. These constraints typically require specialized procedures to sample satisfying values. We extend the STRIPS planning language to support a generic, declarative specification for these procedures while treating their implementation as black boxes. We also describe cost-sensitive planning within this framework. We provide several domain-independent algorithms that reduce STRIPStream problems to a sequence of finite-domain STRIPS planning problems. Finally, we evaluate our algorithms on three robotic planning domains.
Learning Quickly to Plan Quickly Using Modular Meta-Learning
Feb 16, 2019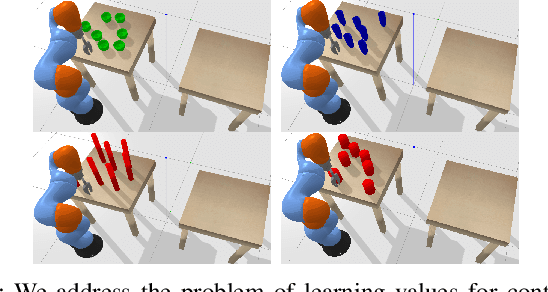
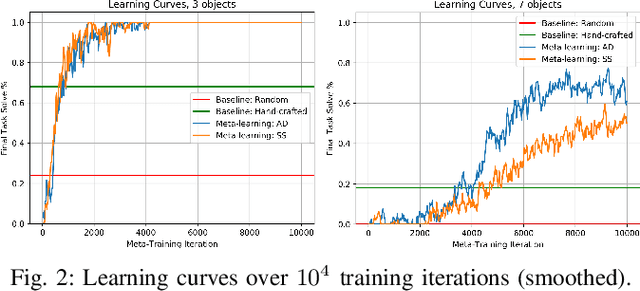
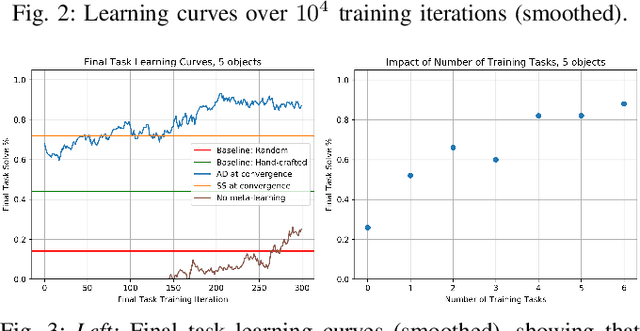
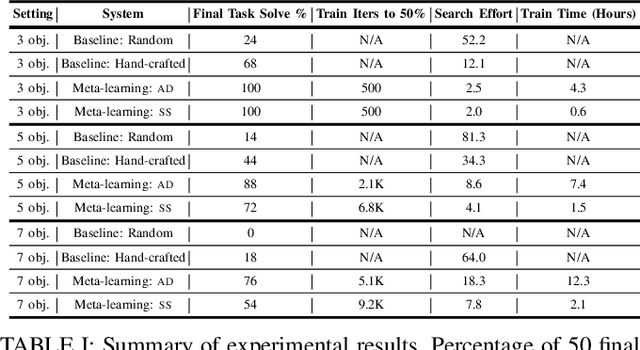
Multi-object manipulation problems in continuous state and action spaces can be solved by planners that search over sampled values for the continuous parameters of operators. The efficiency of these planners depends critically on the effectiveness of the samplers used, but effective sampling in turn depends on details of the robot, environment, and task. Our strategy is to learn functions called "specializers" that generate values for continuous operator parameters, given a state description and values for the discrete parameters. Rather than trying to learn a single specializer for each operator from large amounts of data on a single task, we take a modular meta-learning approach. We train on multiple tasks and learn a variety of specializers that, on a new task, can be quickly adapted using relatively little data -- thus, our system "learns quickly to plan quickly" using these specializers. We validate our approach experimentally in simulated 3D pick-and-place tasks with continuous state and action spaces. Visit http://tinyurl.com/chitnis-icra-19 for a supplementary video.
Sampling-Based Methods for Factored Task and Motion Planning
Feb 12, 2019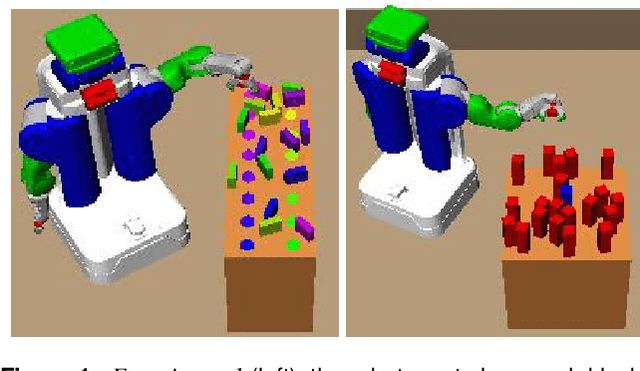

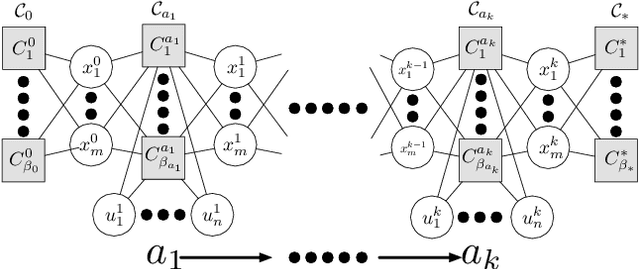

This paper presents a general-purpose formulation of a large class of discrete-time planning problems, with hybrid state and control-spaces, as factored transition systems. Factoring allows state transitions to be described as the intersection of several constraints each affecting a subset of the state and control variables. Robotic manipulation problems with many movable objects involve constraints that only affect several variables at a time and therefore exhibit large amounts of factoring. We develop a theoretical framework for solving factored transition systems with sampling-based algorithms. The framework characterizes conditions on the submanifold in which solutions lie, leading to a characterization of robust feasibility that incorporates dimensionality-reducing constraints. It then connects those conditions to corresponding conditional samplers that can be composed to produce values on this submanifold. We present two domain-independent, probabilistically complete planning algorithms that take, as input, a set of conditional samplers. We demonstrate the empirical efficiency of these algorithms on a set of challenging task and motion planning problems involving picking, placing, and pushing.
Look before you sweep: Visibility-aware motion planning
Jan 18, 2019
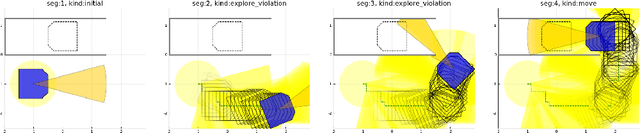

This paper addresses the problem of planning for a robot with a directional obstacle-detection sensor that must move through a cluttered environment. The planning objective is to remain safe by finding a path for the complete robot, including sensor, that guarantees that the robot will not move into any part of the workspace before it has been seen by the sensor. Although a great deal of work has addressed a version of this problem in which the "field of view" of the sensor is a sphere around the robot, there is very little work addressing robots with a narrow or occluded field of view. We give a formal definition of the problem, several solution methods with different computational trade-offs, and experimental results in illustrative domains.
Elimination of All Bad Local Minima in Deep Learning
Jan 02, 2019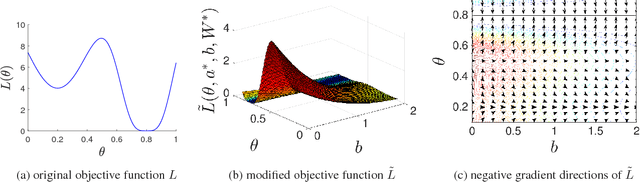
In this paper, we theoretically prove that we can eliminate all suboptimal local minima by adding one neuron per output unit to any deep neural network, for multi-class classification, binary classification, and regression with an arbitrary loss function. At every local minimum of any deep neural network with added neurons, the set of parameters of the original neural network (without added neurons) is guaranteed to be a global minimum of the original neural network. The effects of the added neurons are proven to automatically vanish at every local minimum. Unlike many related results in the literature, our theoretical results are directly applicable to common deep learning tasks because the results only rely on the assumptions that automatically hold in the common tasks. Moreover, we discuss several limitations in eliminating the suboptimal local minima in this manner by providing additional theoretical results and several examples.
Regret bounds for meta Bayesian optimization with an unknown Gaussian process prior
Nov 23, 2018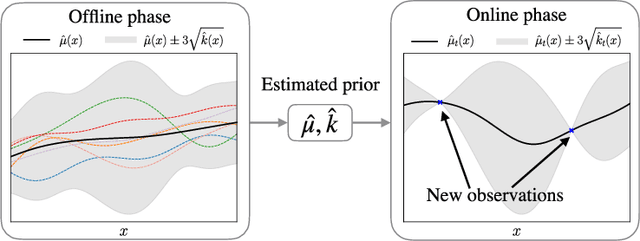
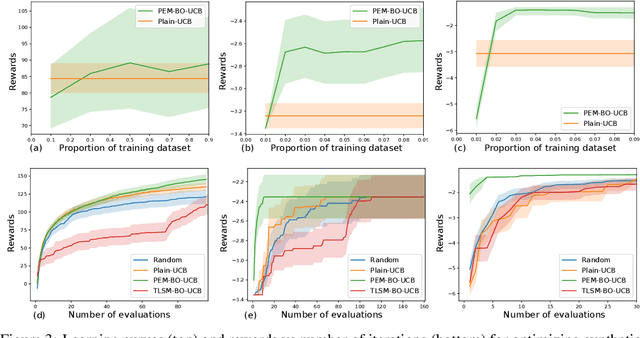
Bayesian optimization usually assumes that a Bayesian prior is given. However, the strong theoretical guarantees in Bayesian optimization are often regrettably compromised in practice because of unknown parameters in the prior. In this paper, we adopt a variant of empirical Bayes and show that, by estimating the Gaussian process prior from offline data sampled from the same prior and constructing unbiased estimators of the posterior, variants of both GP-UCB and probability of improvement achieve a near-zero regret bound, which decreases to a constant proportional to the observational noise as the number of offline data and the number of online evaluations increase. Empirically, we have verified our approach on challenging simulated robotic problems featuring task and motion planning.
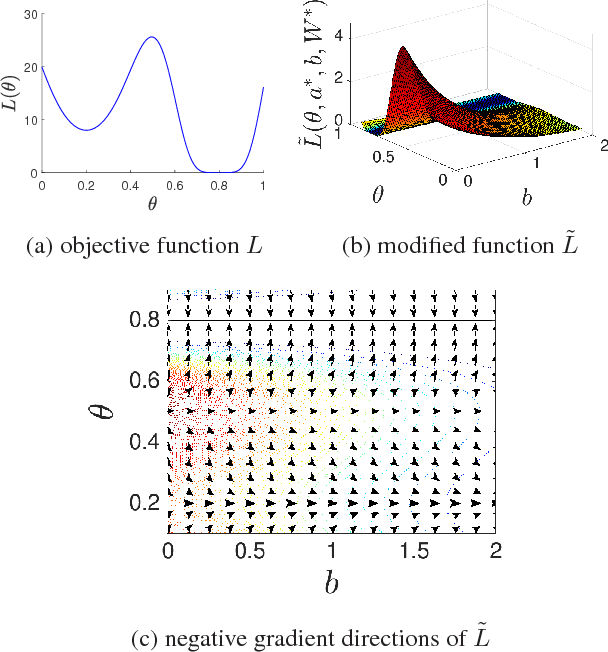
Effect of Depth and Width on Local Minima in Deep Learning
Nov 20, 2018In this paper, we analyze the effects of depth and width on the quality of local minima, without strong over-parameterization and simplification assumptions in the literature. Without any simplification assumption, for deep nonlinear neural networks with the squared loss, we theoretically show that the quality of local minima tends to improve towards the global minimum value as depth and width increase. Furthermore, with a locally-induced structure on deep nonlinear neural networks, the values of local minima of neural networks are theoretically proven to be no worse than the globally optimal values of corresponding classical machine learning models. We empirically support our theoretical observation with a synthetic dataset as well as MNIST, CIFAR-10 and SVHN datasets. When compared to previous studies with strong over-parameterization assumptions, the results in this paper do not require over-parameterization, and instead show the gradual effects of over-parameterization as consequences of general results.
Learning sparse relational transition models
Oct 26, 2018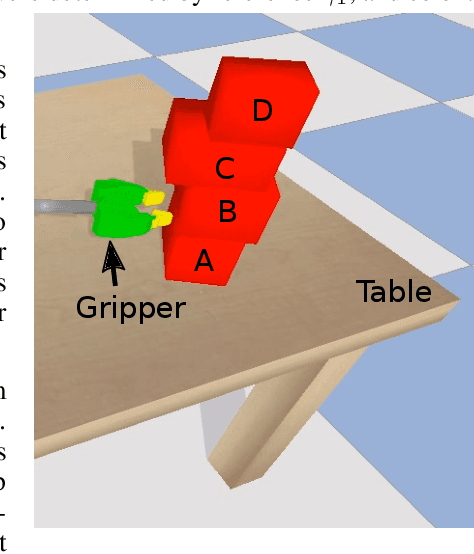

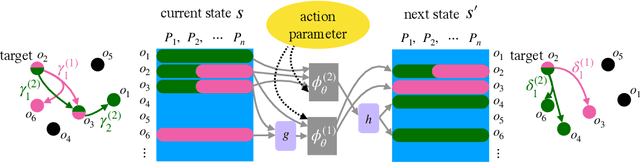

We present a representation for describing transition models in complex uncertain domains using relational rules. For any action, a rule selects a set of relevant objects and computes a distribution over properties of just those objects in the resulting state given their properties in the previous state. An iterative greedy algorithm is used to construct a set of deictic references that determine which objects are relevant in any given state. Feed-forward neural networks are used to learn the transition distribution on the relevant objects' properties. This strategy is demonstrated to be both more versatile and more sample efficient than learning a monolithic transition model in a simulated domain in which a robot pushes stacks of objects on a cluttered table.