 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperposition as Lossy Compression: Measure with Sparse Autoencoders and Connect to Adversarial Vulnerability
Dec 15, 2025Neural networks achieve remarkable performance through superposition: encoding multiple features as overlapping directions in activation space rather than dedicating individual neurons to each feature. This challenges interpretability, yet we lack principled methods to measure superposition. We present an information-theoretic framework measuring a neural representation's effective degrees of freedom. We apply Shannon entropy to sparse autoencoder activations to compute the number of effective features as the minimum neurons needed for interference-free encoding. Equivalently, this measures how many "virtual neurons" the network simulates through superposition. When networks encode more effective features than actual neurons, they must accept interference as the price of compression. Our metric strongly correlates with ground truth in toy models, detects minimal superposition in algorithmic tasks, and reveals systematic reduction under dropout. Layer-wise patterns mirror intrinsic dimensionality studies on Pythia-70M. The metric also captures developmental dynamics, detecting sharp feature consolidation during grokking. Surprisingly, adversarial training can increase effective features while improving robustness, contradicting the hypothesis that superposition causes vulnerability. Instead, the effect depends on task complexity and network capacity: simple tasks with ample capacity allow feature expansion (abundance regime), while complex tasks or limited capacity force reduction (scarcity regime). By defining superposition as lossy compression, this work enables principled measurement of how neural networks organize information under computational constraints, connecting superposition to adversarial robustness.
* Accepted to TMLR, view HTML here: https://leonardbereska.github.io/blog/2025/superposition/
Mechanistic Interpretability for AI Safety -- A Review
Apr 22, 2024



Understanding AI systems' inner workings is critical for ensuring value alignment and safety. This review explores mechanistic interpretability: reverse-engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding. We establish foundational concepts such as features encoding knowledge within neural activations and hypotheses about their representation and computation. We survey methodologies for causally dissecting model behaviors and assess the relevance of mechanistic interpretability to AI safety. We investigate challenges surrounding scalability, automation, and comprehensive interpretation. We advocate for clarifying concepts, setting standards, and scaling techniques to handle complex models and behaviors and expand to domains such as vision and reinforcement learning. Mechanistic interpretability could help prevent catastrophic outcomes as AI systems become more powerful and inscrutable.
Tractable Dendritic RNNs for Reconstructing Nonlinear Dynamical Systems
Jul 06, 2022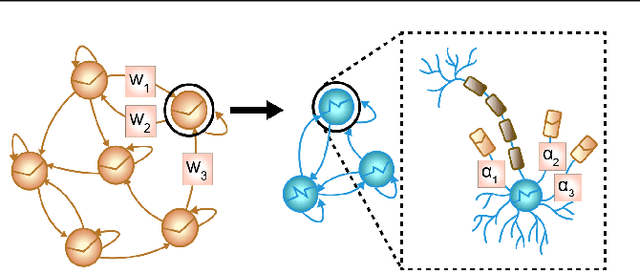
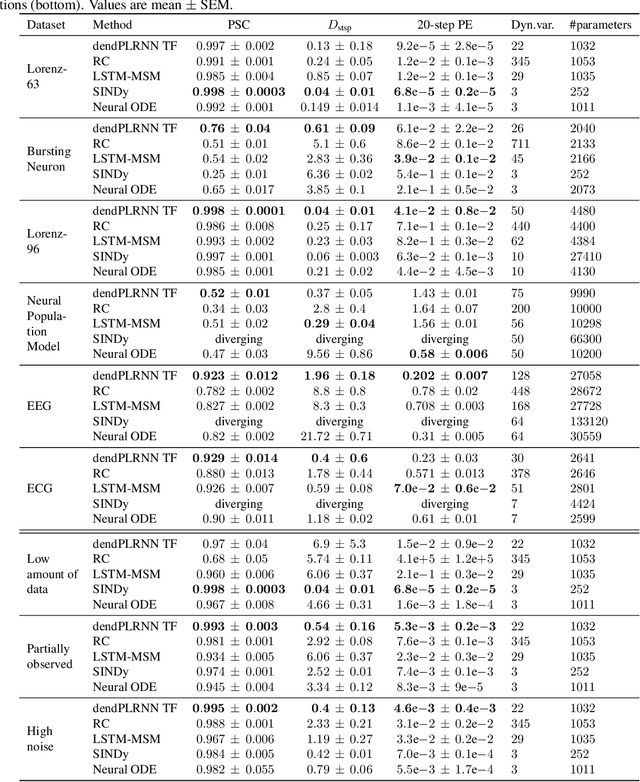
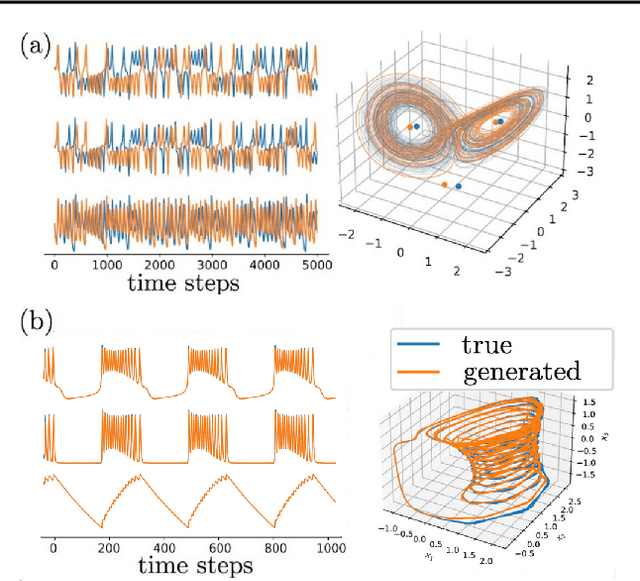
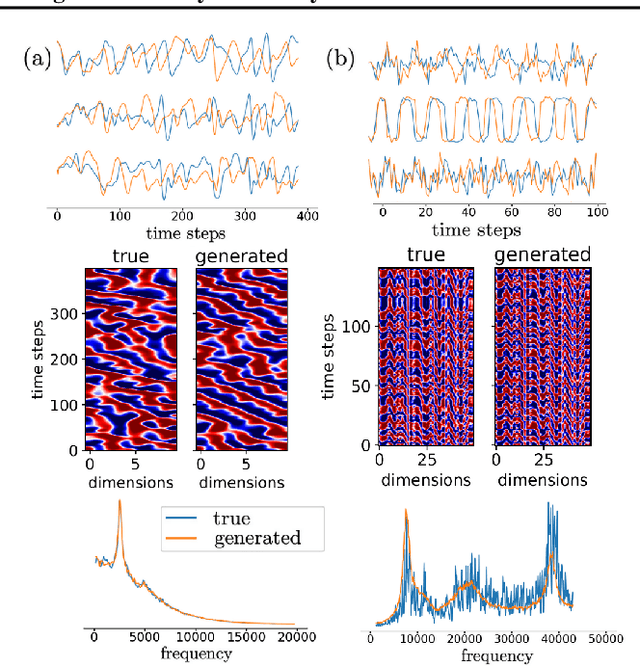
In many scientific disciplines, we are interested in inferring the nonlinear dynamical system underlying a set of observed time series, a challenging task in the face of chaotic behavior and noise. Previous deep learning approaches toward this goal often suffered from a lack of interpretability and tractability. In particular, the high-dimensional latent spaces often required for a faithful embedding, even when the underlying dynamics lives on a lower-dimensional manifold, can hamper theoretical analysis. Motivated by the emerging principles of dendritic computation, we augment a dynamically interpretable and mathematically tractable piecewise-linear (PL) recurrent neural network (RNN) by a linear spline basis expansion. We show that this approach retains all the theoretically appealing properties of the simple PLRNN, yet boosts its capacity for approximating arbitrary nonlinear dynamical systems in comparatively low dimensions. We employ two frameworks for training the system, one combining back-propagation-through-time (BPTT) with teacher forcing, and another based on fast and scalable variational inference. We show that the dendritically expanded PLRNN achieves better reconstructions with fewer parameters and dimensions on various dynamical systems benchmarks and compares favorably to other methods, while retaining a tractable and interpretable structure.
Continual Learning of Dynamical Systems with Competitive Federated Reservoir Computing
Jun 27, 2022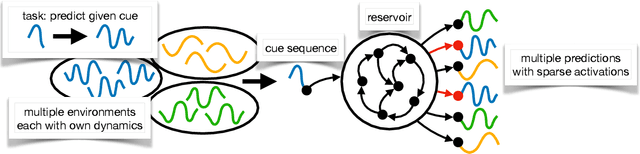
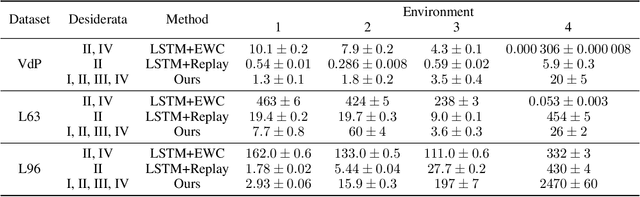
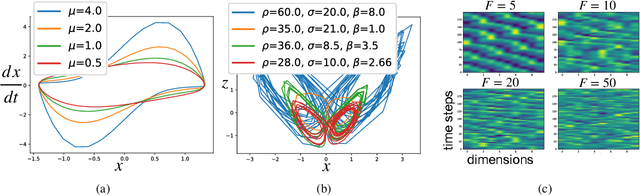
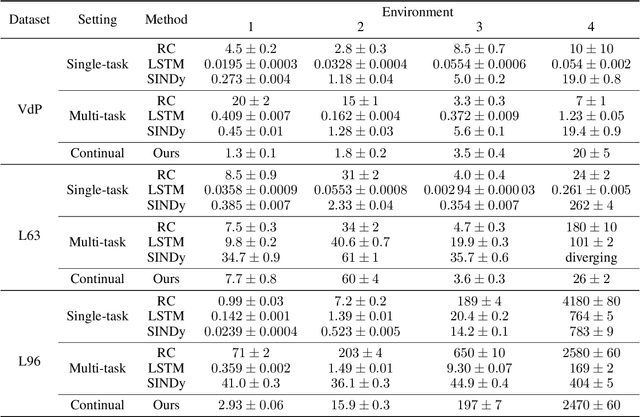
Machine learning recently proved efficient in learning differential equations and dynamical systems from data. However, the data is commonly assumed to originate from a single never-changing system. In contrast, when modeling real-world dynamical processes, the data distribution often shifts due to changes in the underlying system dynamics. Continual learning of these processes aims to rapidly adapt to abrupt system changes without forgetting previous dynamical regimes. This work proposes an approach to continual learning based on reservoir computing, a state-of-the-art method for training recurrent neural networks on complex spatiotemporal dynamical systems. Reservoir computing fixes the recurrent network weights - hence these cannot be forgotten - and only updates linear projection heads to the output. We propose to train multiple competitive prediction heads concurrently. Inspired by neuroscience's predictive coding, only the most predictive heads activate, laterally inhibiting and thus protecting the inactive heads from forgetting induced by interfering parameter updates. We show that this multi-head reservoir minimizes interference and catastrophic forgetting on several dynamical systems, including the Van-der-Pol oscillator, the chaotic Lorenz attractor, and the high-dimensional Lorenz-96 weather model. Our results suggest that reservoir computing is a promising candidate framework for the continual learning of dynamical systems. We provide our code for data generation, method, and comparisons at \url{https://github.com/leonardbereska/multiheadreservoir}.
Unsupervised Part-Based Disentangling of Object Shape and Appearance
Mar 16, 2019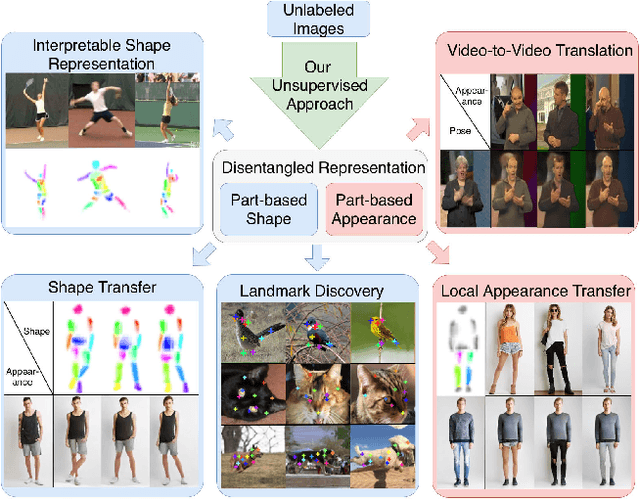

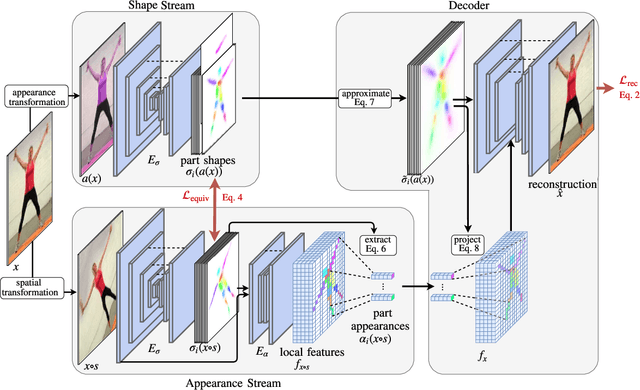

Large intra-class variation is the result of changes in multiple object characteristics. Images, however, only show the superposition of different variable factors such as appearance or shape. Therefore, learning to disentangle and represent these different characteristics poses a great challenge, especially in the unsupervised case. Moreover, large object articulation calls for a flexible part-based model. We present an unsupervised approach for disentangling appearance and shape by learning parts consistently over all instances of a category. Our model for learning an object representation is trained by simultaneously exploiting invariance and equivariance constraints between synthetically transformed images. Since no part annotation or prior information on an object class is required, the approach is applicable to arbitrary classes. We evaluate our approach on a wide range of object categories and diverse tasks including pose prediction, disentangled image synthesis, and video-to-video translation. The approach outperforms the state-of-the-art on unsupervised keypoint prediction and compares favorably even against supervised approaches on the task of shape and appearance transfer.