 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration Structure in LLM Agents for Multi-File Change Localization
Jun 10, 2026Software engineering tools increasingly rely on LLM based agents to localize files to change to resolve a software issue. Most AI agents explore repositories linearly, that is, visiting one directory or file per step. We postulate that this is a structural mismatch for changes that span several subsystems. We compare linear sequential exploration against non-linear, domain-scoped parallel agentic exploration. Using SWE Bench Pro as initial benchmark, we focus on ansible as an exemplar. We construct an approach for persistent-session evaluation of GitHub issues anchored at a single base commit. We compare our non-linear domain-agent file traversal system against a base LLM without direct repository access, a single agent Recursive Language Model (RLM) baseline with a persistent Python REPL and an external CLI baseline using Codex 5.5 High. Domain scoped parallel agent spawning with a small Haiku-class model achieves the highest micro F1 among Haiku class models by a large margin. Domain-agents is the second highest behind only the much larger Codex 5.5 High on our own expanded benchmark including over more recent PRs from 2025 and 2026. On the original, curated, 2020 SWE-bench Pro benchmark, a larger Sonnet plain LLM baseline attains higher micro F1 by predicting few files, leading to higher precision, but at significantly lower all gold recall. We also present three additional findings. First, documentation evolution is a latent dependency unresolved by any approach. Second, naive file system access can degrade localization driven by test-file over prediction. Lastly, forced multi-agent consultation does not measurably help and raises token cost substantially.
Declarative Skills for AI Agents in Knowledge-Grounded Tool-Use Workflows
Jun 05, 2026We study orchestration mechanisms for tool-using AI agents in realistic customer-service workflows over an unstructured knowledge base. We argue that declarative agents -- AI agents equipped with natural-language skill files appended to the system prompt -- are an effective orchestration paradigm. Concretely, we compare (i) a DeclarativeAgent that reads three domain-specific skill files at inference time and decides its own control flow, (ii) an ImperativeAgent based on a programmatic state machine with explicit phases, and (iii) an unscaffolded baseline agent modeled after the $τ$-Knowledge benchmark agent. Our ImperativeAgent is motivated by externalised-control inference as in Recursive Language Models and graph-based orchestration frameworks. We formalise the three agents as policy classes within a decentralised partially-observable Markov decision process and analyse their information-theoretic and structural properties; we then test the predicted differences empirically on five language models and two retrieval regimes. Our results show that retrieval quality is a dominant bottleneck for AI agents: when evidence is incomplete or skewed, all agents degrade substantially, and skill files cannot recover lost performance. Under high-quality retrieval, however, declarative skills consistently improve accuracy on procedural tasks and reduce orchestration errors, while the imperative state machine's brittleness does not reliably improve task success or compliance.
Quantum-Inspired Trace-Augmented Evidence Selection for Reasoning over Structured Hypothesis Spaces
Jun 05, 2026Large language models (LLMs) now solve a wide range of expert-level exams at or above human level, yet remain brittle on specialised, evidence-intensive domains such as law. On these tasks, errors arise not only from gaps in world knowledge but also from subtle distinctions between pieces of evidence and inconsistent use of supporting evidence. The most common aggregator over sampled chain-of-thought (CoT) traces, majority vote, returns the most popular answer regardless of whether its evidence is actually strongest. We propose to treat the selection of CoT reasoning fragments into a set of evidence as an explicit combinatorial optimisation problem, allowing well-supported but minority hypotheses to override noisy majorities, and to evaluate the approach on legal-reasoning benchmarks that are particularly sensitive to evidence quality. We introduce EP-HUBO (Evidence Pool Higher-Order Binary Optimisation), which generates multiple CoT traces with a small local model, parses fragments into per-hypothesis evidence pools, solves a higher-order unconstrained binary optimisation per pool with quality-derived weights (relevance, specificity, distinctiveness), and delegates a single adjudication call per question to a frontier model. We evaluate EP-HUBO on two evidence-intensive legal benchmarks using both simulated annealing on classical hardware and the Dirac-3 photonic entropy-quantum machine from Quantum Computing Inc. HUBO-style optimisation gives a principled way to aggregate reasoning fragments while preserving minority-but-correct hypotheses, and is most valuable in low-contamination domains where frontier models have not already absorbed the benchmark material.
Collaboratively adding new knowledge to an LLM
Oct 18, 2024



We address the question of how to successively add new knowledge to an LLM whilst retaining previously-added knowledge. We consider two settings, semi-cooperative and fully-cooperative. Overall, LoRA performs better in most cases than full-fine tuning of all parameters when both new knowledge acquisition and retention of old, including recent, knowledge are taken into account. In the semi-cooperative setting, where datasets are not available after training, MOE mixing, model merging, and LoRA-based orthogonal subspace sequential learning, using a small weight on the orthogonality term, perform well. In the fully-cooperative setting where datasets remain available, joint training and sequential training with replay are both effective approaches with LoRA training generally preferable to full fine-tuning. The codes needed to reproduce the results are provided in an open source repository.
Flexible and Effective Mixing of Large Language Models into a Mixture of Domain Experts
Aug 30, 2024



We present a toolkit for creating low-cost Mixture-of-Domain-Experts (MOE) from trained models. The toolkit can be used for creating a mixture from models or from adapters. We perform extensive tests and offer guidance on defining the architecture of the resulting MOE using the toolkit. A public repository is available.
Enhancing Training Efficiency Using Packing with Flash Attention
Jul 12, 2024



Padding is often used in tuning LLM models by adding special tokens to shorter training examples to match the length of the longest sequence in each batch. While this ensures uniformity for batch processing, it introduces inefficiencies by including irrelevant padding tokens in the computation and wastes GPU resources. On the other hand, the Hugging Face SFT trainer offers the option to use packing to combine multiple training examples up to the maximum sequence length. This allows for maximal utilization of GPU resources. However, without proper masking of each packed training example, attention will not be computed correctly when using SFT trainer. We enable and then analyse packing and Flash Attention with proper attention masking of each example and show the benefits of this training paradigm.
Efficiently Distilling LLMs for Edge Applications
Apr 01, 2024



Supernet training of LLMs is of great interest in industrial applications as it confers the ability to produce a palette of smaller models at constant cost, regardless of the number of models (of different size / latency) produced. We propose a new method called Multistage Low-rank Fine-tuning of Super-transformers (MLFS) for parameter-efficient supernet training. We show that it is possible to obtain high-quality encoder models that are suitable for commercial edge applications, and that while decoder-only models are resistant to a comparable degree of compression, decoders can be effectively sliced for a significant reduction in training time.
TOFA: Transfer-Once-for-All
Mar 27, 2023



Weight-sharing neural architecture search aims to optimize a configurable neural network model (supernet) for a variety of deployment scenarios across many devices with different resource constraints. Existing approaches use evolutionary search to extract a number of models from a supernet trained on a very large data set, and then fine-tune the extracted models on the typically small, real-world data set of interest. The computational cost of training thus grows linearly with the number of different model deployment scenarios. Hence, we propose Transfer-Once-For-All (TOFA) for supernet-style training on small data sets with constant computational training cost over any number of edge deployment scenarios. Given a task, TOFA obtains custom neural networks, both the topology and the weights, optimized for any number of edge deployment scenarios. To overcome the challenges arising from small data, TOFA utilizes a unified semi-supervised training loss to simultaneously train all subnets within the supernet, coupled with on-the-fly architecture selection at deployment time.
Neural-Progressive Hedging: Enforcing Constraints in Reinforcement Learning with Stochastic Programming
Feb 27, 2022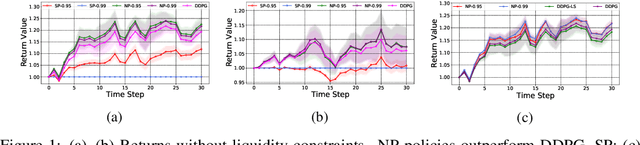
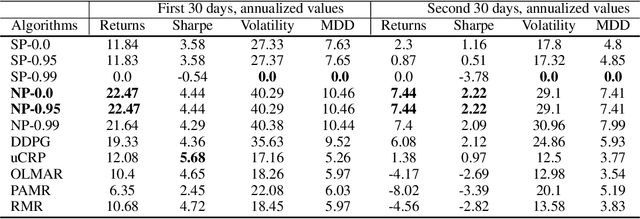
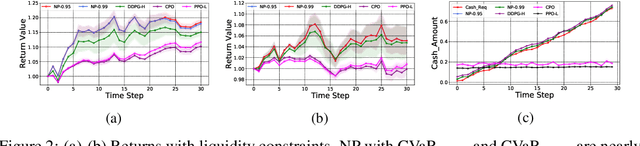
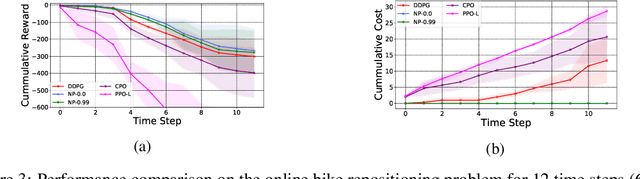
We propose a framework, called neural-progressive hedging (NP), that leverages stochastic programming during the online phase of executing a reinforcement learning (RL) policy. The goal is to ensure feasibility with respect to constraints and risk-based objectives such as conditional value-at-risk (CVaR) during the execution of the policy, using probabilistic models of the state transitions to guide policy adjustments. The framework is particularly amenable to the class of sequential resource allocation problems since feasibility with respect to typical resource constraints cannot be enforced in a scalable manner. The NP framework provides an alternative that adds modest overhead during the online phase. Experimental results demonstrate the efficacy of the NP framework on two continuous real-world tasks: (i) the portfolio optimization problem with liquidity constraints for financial planning, characterized by non-stationary state distributions; and (ii) the dynamic repositioning problem in bike sharing systems, that embodies the class of supply-demand matching problems. We show that the NP framework produces policies that are better than deep RL and other baseline approaches, adapting to non-stationarity, whilst satisfying structural constraints and accommodating risk measures in the resulting policies. Additional benefits of the NP framework are ease of implementation and better explainability of the policies.
Order Constraints in Optimal Transport
Oct 14, 2021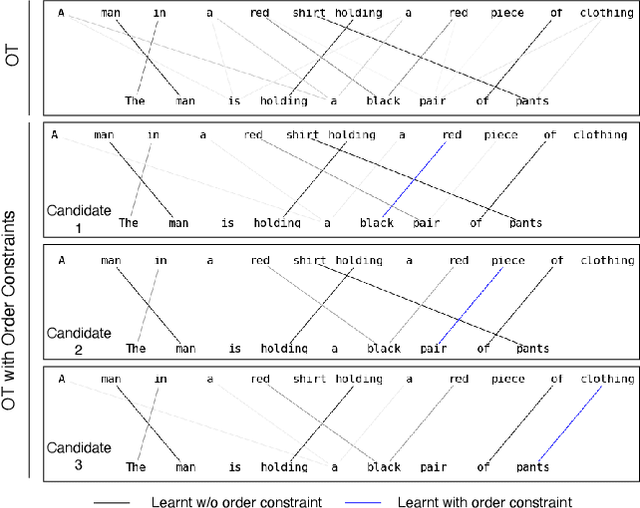

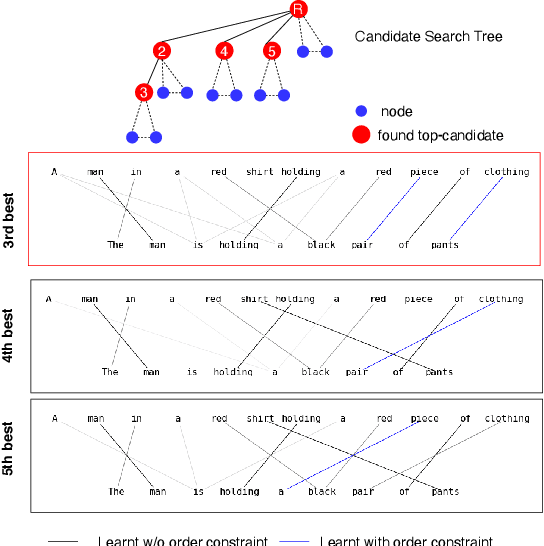
Optimal transport is a framework for comparing measures whereby a cost is incurred for transporting one measure to another. Recent works have aimed to improve optimal transport plans through the introduction of various forms of structure. We introduce novel order constraints into the optimal transport formulation to allow for the incorporation of structure. While there will are now quadratically many constraints as before, we prove a $\delta-$approximate solution to the order-constrained optimal transport problem can be obtained in $\mathcal{O}(L^2\delta^{-2} \kappa(\delta(2cL_\infty (1+(mn)^{1/2}))^{-1}) \cdot mn\log mn)$ time. We derive computationally efficient lower bounds that allow for an explainable approach to adding structure to the optimal transport plan through order constraints. We demonstrate experimentally that order constraints improve explainability using the e-SNLI (Stanford Natural Language Inference) dataset that includes human-annotated rationales for each assignment.