 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStack operation of tensor networks
Mar 28, 2022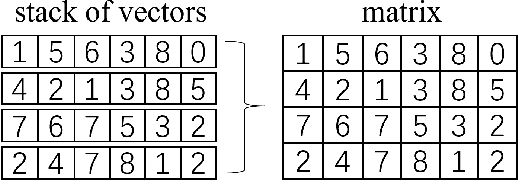
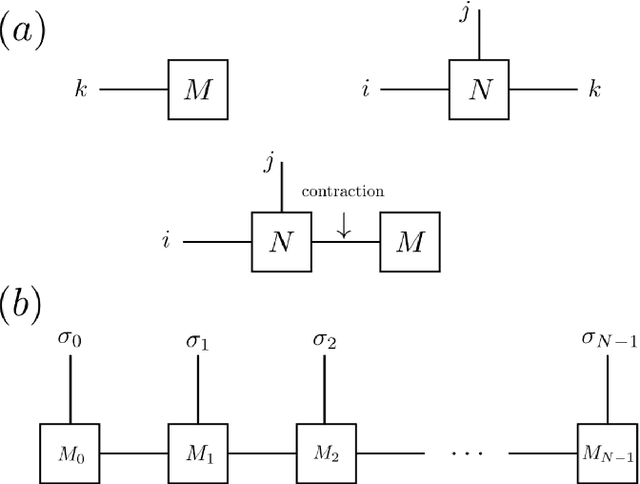
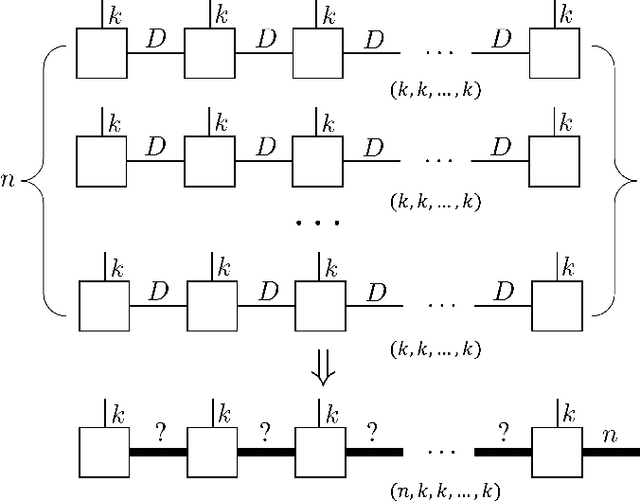
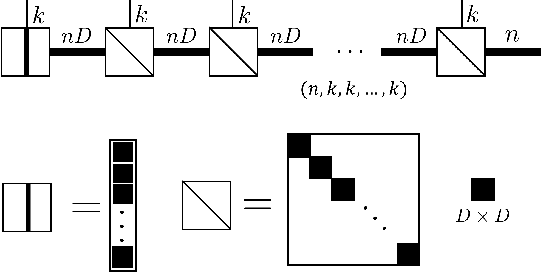
The tensor network, as a facterization of tensors, aims at performing the operations that are common for normal tensors, such as addition, contraction and stacking. However, due to its non-unique network structure, only the tensor network contraction is so far well defined. In this paper, we propose a mathematically rigorous definition for the tensor network stack approach, that compress a large amount of tensor networks into a single one without changing their structures and configurations. We illustrate the main ideas with the matrix product states based machine learning as an example. Our results are compared with the for loop and the efficient coding method on both CPU and GPU.
SUTD-PRCM Dataset and Neural Architecture Search Approach for Complex Metasurface Design
Feb 24, 2022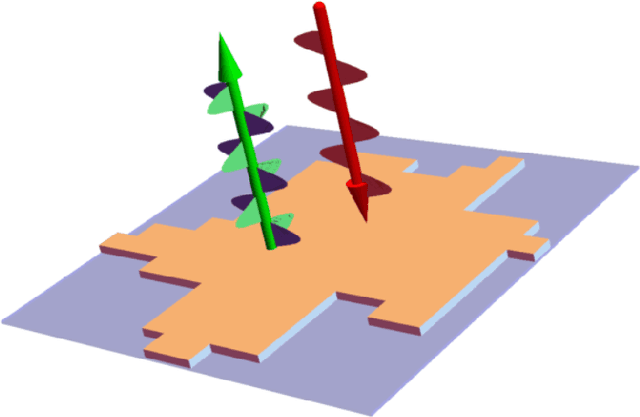


Metasurfaces have received a lot of attentions recently due to their versatile capability in manipulating electromagnetic wave. Advanced designs to satisfy multiple objectives with non-linear constraints have motivated researchers in using machine learning (ML) techniques like deep learning (DL) for accelerated design of metasurfaces. For metasurfaces, it is difficult to make quantitative comparisons between different ML models without having a common and yet complex dataset used in many disciplines like image classification. Many studies were directed to a relatively constrained datasets that are limited to specified patterns or shapes in metasurfaces. In this paper, we present our SUTD polarized reflection of complex metasurfaces (SUTD-PRCM) dataset, which contains approximately 260,000 samples of complex metasurfaces created from electromagnetic simulation, and it has been used to benchmark our DL models. The metasurface patterns are divided into different classes to facilitate different degree of complexity, which involves identifying and exploiting the relationship between the patterns and the electromagnetic responses that can be compared in using different DL models. With the release of this SUTD-PRCM dataset, we hope that it will be useful for benchmarking existing or future DL models developed in the ML community. We also propose a classification problem that is less encountered and apply neural architecture search to have a preliminary understanding of potential modification to the neural architecture that will improve the prediction by DL models. Our finding shows that convolution stacking is not the dominant element of the neural architecture anymore, which implies that low-level features are preferred over the traditional deep hierarchical high-level features thus explains why deep convolutional neural network based models are not performing well in our dataset.