 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Offline Reinforcement Learning for Structured Cyclic MDPs
Feb 12, 2026We introduce a novel cyclic Markov decision process (MDP) framework for multi-step decision problems with heterogeneous stage-specific dynamics, transitions, and discount factors across the cycle. In this setting, offline learning is challenging: optimizing a policy at any stage shifts the state distributions of subsequent stages, propagating mismatch across the cycle. To address this, we propose a modular structural framework that decomposes the cyclic process into stage-wise sub-problems. While generally applicable, we instantiate this principle as CycleFQI, an extension of fitted Q-iteration enabling theoretical analysis and interpretation. It uses a vector of stage-specific Q-functions, tailored to each stage, to capture within-stage sequences and transitions between stages. This modular design enables partial control, allowing some stages to be optimized while others follow predefined policies. We establish finite-sample suboptimality error bounds and derive global convergence rates under Besov regularity, demonstrating that CycleFQI mitigates the curse of dimensionality compared to monolithic baselines. Additionally, we propose a sieve-based method for asymptotic inference of optimal policy values under a margin condition. Experiments on simulated and real-world Type 1 Diabetes data sets demonstrate CycleFQI's effectiveness.
Audio Visual Segmentation Through Text Embeddings
Feb 22, 2025The goal of Audio-Visual Segmentation (AVS) is to localize and segment the sounding source objects from the video frames. Researchers working on AVS suffer from limited datasets because hand-crafted annotation is expensive. Recent works attempt to overcome the challenge of limited data by leveraging the segmentation foundation model, SAM, prompting it with audio to enhance its ability to segment sounding source objects. While this approach alleviates the model's burden on understanding visual modality by utilizing pre-trained knowledge of SAM, it does not address the fundamental challenge of the limited dataset for learning audio-visual relationships. To address these limitations, we propose \textbf{AV2T-SAM}, a novel framework that bridges audio features with the text embedding space of pre-trained text-prompted SAM. Our method leverages multimodal correspondence learned from rich text-image paired datasets to enhance audio-visual alignment. Furthermore, we introduce a novel feature, $\mathbf{\textit{\textbf{f}}_{CLIP} \odot \textit{\textbf{f}}_{CLAP}}$, which emphasizes shared semantics of audio and visual modalities while filtering irrelevant noise. Experiments on the AVSBench dataset demonstrate state-of-the-art performance on both datasets of AVSBench. Our approach outperforms existing methods by effectively utilizing pretrained segmentation models and cross-modal semantic alignment.
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Jun 20, 2024



This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake video(Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and unsynchronized video). The experimental results show that our approach improves the model's detection of unseen attacks by an average of 7.31% across four test sets, compared to the baseline model. Additionally, our proposed framework offers interpretability, indicating which modality the model identifies as fake.
What Variables Affect Out-Of-Distribution Generalization in Pretrained Models?
May 23, 2024



Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which suggests deeper DNN layers compress representations and hinder OOD performance. Contrary to earlier work, we find the tunnel effect is not universal. Based on 10,584 linear probes, we study the conditions that mitigate the tunnel effect by varying DNN architecture, training dataset, image resolution, and augmentations. We quantify each variable's impact using a novel SHAP analysis. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
Doubly-Robust Off-Policy Evaluation with Estimated Logging Policy
Apr 02, 2024



We introduce a novel doubly-robust (DR) off-policy evaluation (OPE) estimator for Markov decision processes, DRUnknown, designed for situations where both the logging policy and the value function are unknown. The proposed estimator initially estimates the logging policy and then estimates the value function model by minimizing the asymptotic variance of the estimator while considering the estimating effect of the logging policy. When the logging policy model is correctly specified, DRUnknown achieves the smallest asymptotic variance within the class containing existing OPE estimators. When the value function model is also correctly specified, DRUnknown is optimal as its asymptotic variance reaches the semiparametric lower bound. We present experimental results conducted in contextual bandits and reinforcement learning to compare the performance of DRUnknown with that of existing methods.
Wasserstein Geodesic Generator for Conditional Distributions
Aug 28, 2023



Generating samples given a specific label requires estimating conditional distributions. We derive a tractable upper bound of the Wasserstein distance between conditional distributions to lay the theoretical groundwork to learn conditional distributions. Based on this result, we propose a novel conditional generation algorithm where conditional distributions are fully characterized by a metric space defined by a statistical distance. We employ optimal transport theory to propose the Wasserstein geodesic generator, a new conditional generator that learns the Wasserstein geodesic. The proposed method learns both conditional distributions for observed domains and optimal transport maps between them. The conditional distributions given unobserved intermediate domains are on the Wasserstein geodesic between conditional distributions given two observed domain labels. Experiments on face images with light conditions as domain labels demonstrate the efficacy of the proposed method.
Double Doubly Robust Thompson Sampling for Generalized Linear Contextual Bandits
Sep 15, 2022
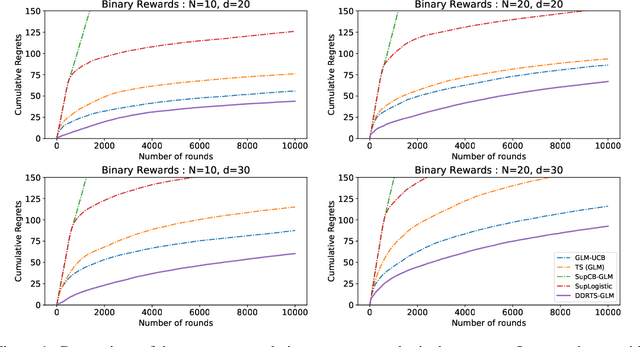
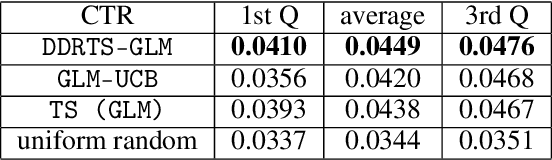
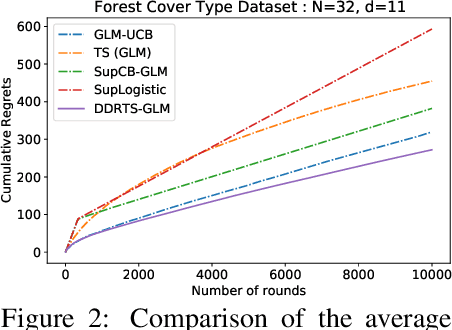
We propose a novel contextual bandit algorithm for generalized linear rewards with an $\tilde{O}(\sqrt{\kappa^{-1} \phi T})$ regret over $T$ rounds where $\phi$ is the minimum eigenvalue of the covariance of contexts and $\kappa$ is a lower bound of the variance of rewards. In several practical cases where $\phi=O(d)$, our result is the first regret bound for generalized linear model (GLM) bandits with the order $\sqrt{d}$ without relying on the approach of Auer [2002]. We achieve this bound using a novel estimator called double doubly-robust (DDR) estimator, a subclass of doubly-robust (DR) estimator but with a tighter error bound. The approach of Auer [2002] achieves independence by discarding the observed rewards, whereas our algorithm achieves independence considering all contexts using our DDR estimator. We also provide an $O(\kappa^{-1} \phi \log (NT) \log T)$ regret bound for $N$ arms under a probabilistic margin condition. Regret bounds under the margin condition are given by Bastani and Bayati [2020] and Bastani et al. [2021] under the setting that contexts are common to all arms but coefficients are arm-specific. When contexts are different for all arms but coefficients are common, ours is the first regret bound under the margin condition for linear models or GLMs. We conduct empirical studies using synthetic data and real examples, demonstrating the effectiveness of our algorithm.