 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment-aware Diffusion Probabilistic Model for Longitudinal MRI Generation and Diffuse Glioma Growth Prediction
Sep 14, 2023



Diffuse gliomas are malignant brain tumors that grow widespread through the brain. The complex interactions between neoplastic cells and normal tissue, as well as the treatment-induced changes often encountered, make glioma tumor growth modeling challenging. In this paper, we present a novel end-to-end network capable of generating future tumor masks and realistic MRIs of how the tumor will look at any future time points for different treatment plans. Our approach is based on cutting-edge diffusion probabilistic models and deep-segmentation neural networks. We included sequential multi-parametric magnetic resonance images (MRI) and treatment information as conditioning inputs to guide the generative diffusion process. This allows for tumor growth estimates at any given time point. We trained the model using real-world postoperative longitudinal MRI data with glioma tumor growth trajectories represented as tumor segmentation maps over time. The model has demonstrated promising performance across a range of tasks, including the generation of high-quality synthetic MRIs with tumor masks, time-series tumor segmentations, and uncertainty estimates. Combined with the treatment-aware generated MRIs, the tumor growth predictions with uncertainty estimates can provide useful information for clinical decision-making.
Handling Missing MRI Input Data in Deep Learning Segmentation of Brain Metastases: A Multi-Center Study
Dec 27, 2019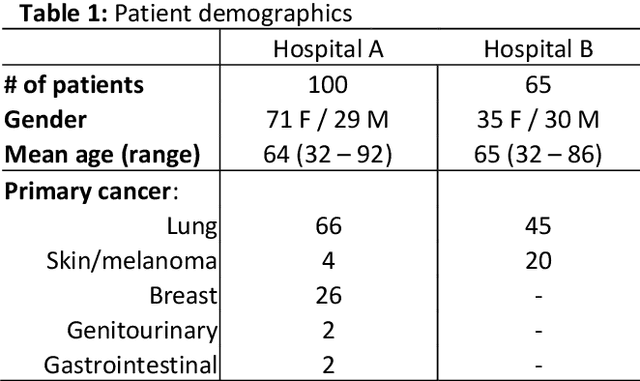
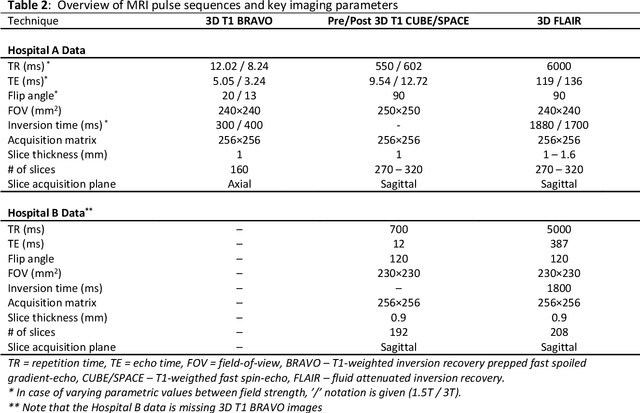
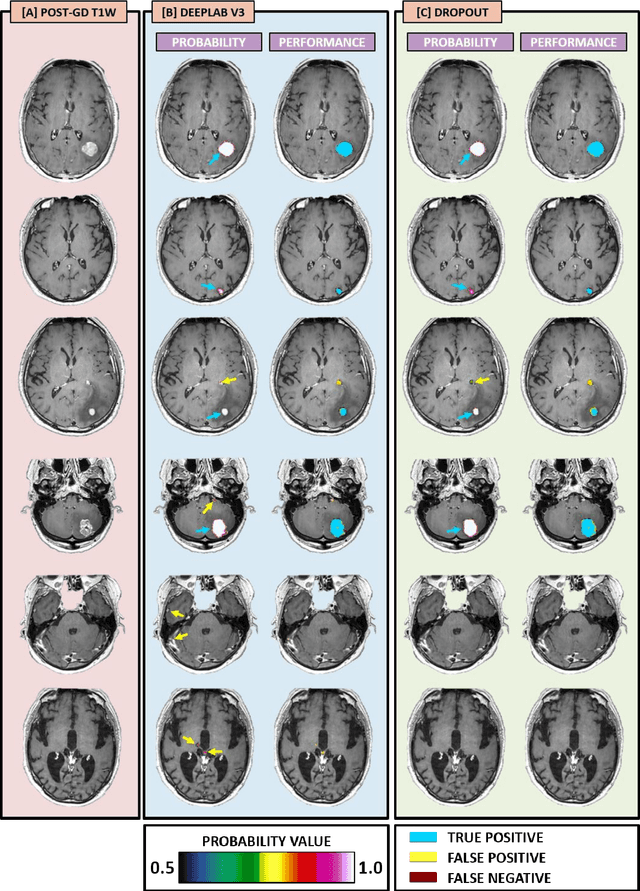
The purpose was to assess the clinical value of a novel DropOut model for detecting and segmenting brain metastases, in which a neural network is trained on four distinct MRI sequences using an input dropout layer, thus simulating the scenario of missing MRI data by training on the full set and all possible subsets of the input data. This retrospective, multi-center study, evaluated 165 patients with brain metastases. A deep learning based segmentation model for automatic segmentation of brain metastases, named DropOut, was trained on multi-sequence MRI from 100 patients, and validated/tested on 10/55 patients. The segmentation results were compared with the performance of a state-of-the-art DeepLabV3 model. The MR sequences in the training set included pre- and post-gadolinium (Gd) T1-weighted 3D fast spin echo, post-Gd T1-weighted inversion recovery (IR) prepped fast spoiled gradient echo, and 3D fluid attenuated inversion recovery (FLAIR), whereas the test set did not include the IR prepped image-series. The ground truth were established by experienced neuroradiologists. The results were evaluated using precision, recall, Dice score, and receiver operating characteristics (ROC) curve statistics, while the Wilcoxon rank sum test was used to compare the performance of the two neural networks. The area under the ROC curve (AUC), averaged across all test cases, was 0.989+-0.029 for the DropOut model and 0.989+-0.023 for the DeepLabV3 model (p=0.62). The DropOut model showed a significantly higher Dice score compared to the DeepLabV3 model (0.795+-0.105 vs. 0.774+-0.104, p=0.017), and a significantly lower average false positive rate of 3.6/patient vs. 7.0/patient (p<0.001) using a 10mm3 lesion-size limit. The DropOut model may facilitate accurate detection and segmentation of brain metastases on a multi-center basis, even when the test cohort is missing MRI input data.
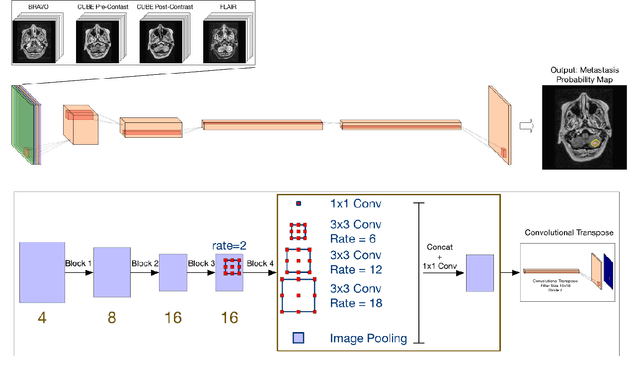
MRI Pulse Sequence Integration for Deep-Learning Based Brain Metastasis Segmentation
Dec 18, 2019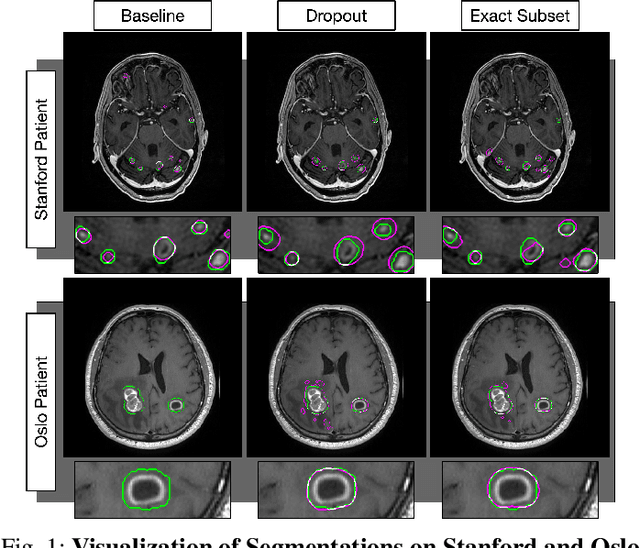
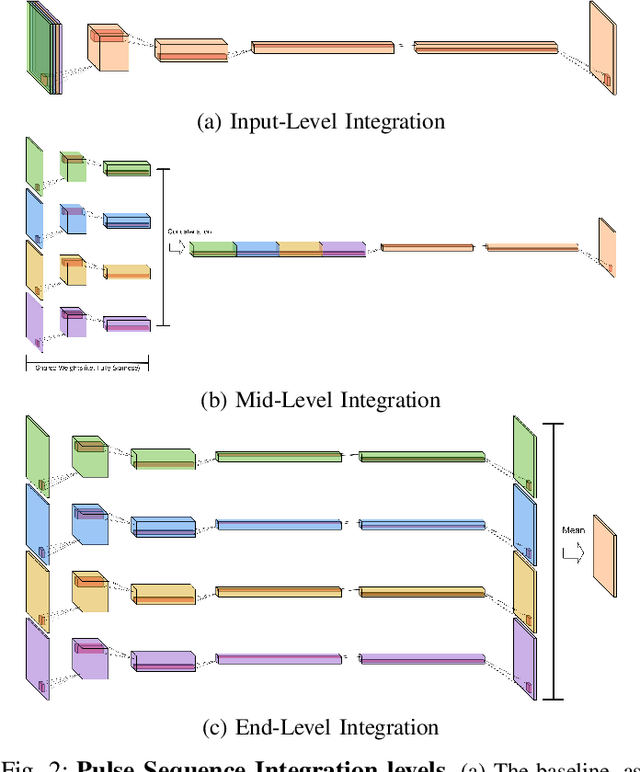
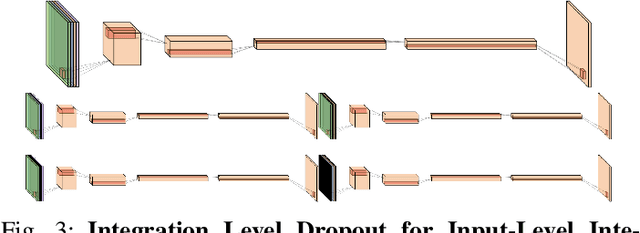
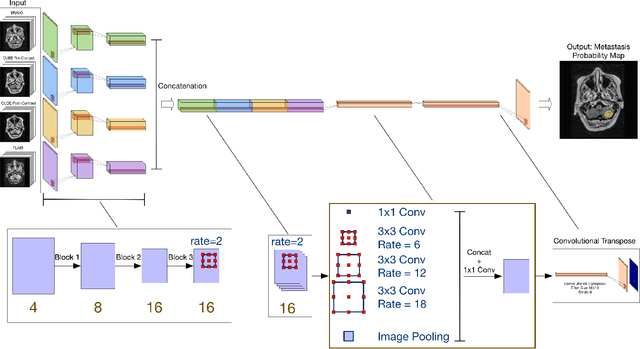
Magnetic resonance (MR) imaging is an essential diagnostic tool in clinical medicine. Recently, a variety of deep learning methods have been applied to segmentation tasks in medical images, with promising results for computer-aided diagnosis. For MR images, effectively integrating different pulse sequences is important to optimize performance. However, the best way to integrate different pulse sequences remains unclear. In this study, we evaluate multiple architectural features and characterize their effects in the task of metastasis segmentation. Specifically, we consider (1) different pulse sequence integration schemas, (2) different modes of weight sharing for parallel network branches, and (3) a new approach for enabling robustness to missing pulse sequences. We find that levels of integration and modes of weight sharing that favor low variance work best in our regime of small data (n = 100). By adding an input-level dropout layer, we could preserve the overall performance of these networks while allowing for inference on inputs with missing pulse sequence. We illustrate not only the generalizability of the network but also the utility of this robustness when applying the trained model to data from a different center, which does not use the same pulse sequences. Finally, we apply network visualization methods to better understand which input features are most important for network performance. Together, these results provide a framework for building networks with enhanced robustness to missing data while maintaining comparable performance in medical imaging applications.