 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos
Jul 13, 2020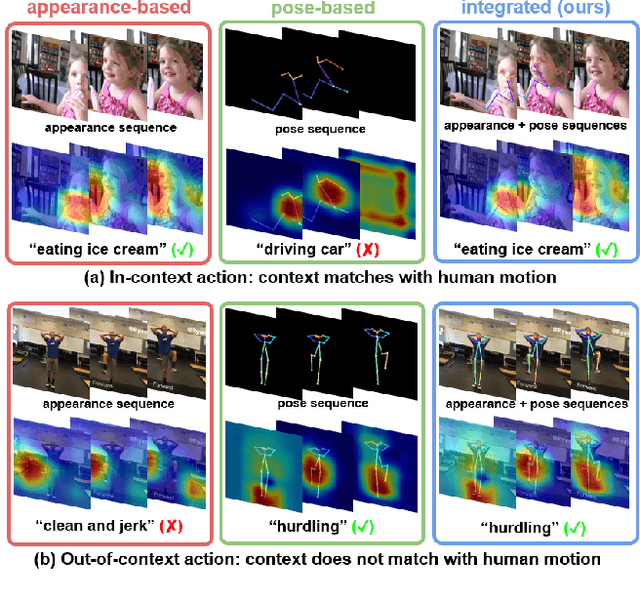
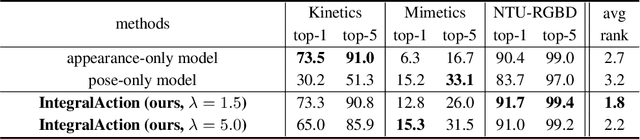
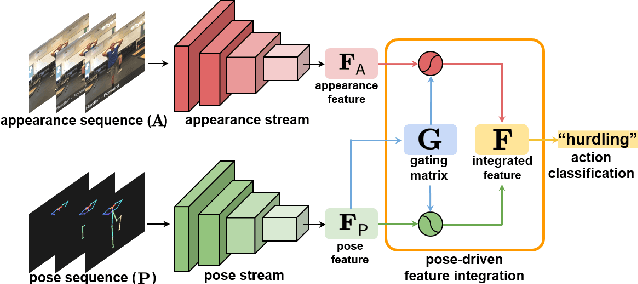
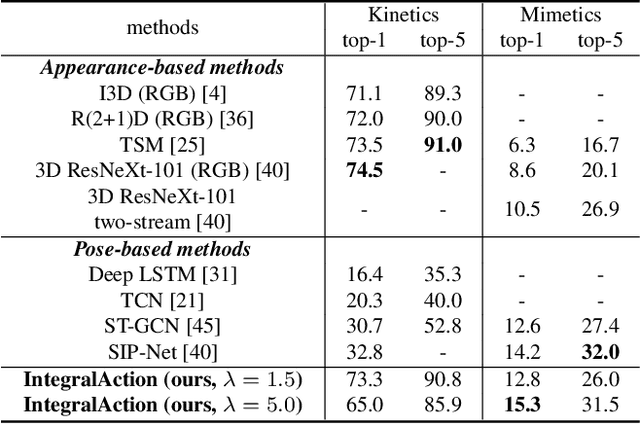
Most current action recognition methods heavily rely on appearance information by taking an RGB sequence of entire image regions as input. While being effective in exploiting contextual information around humans, e.g., human appearance and scene category, they are easily fooled by out-of-context action videos where the contexts do not exactly match with target actions. In contrast, pose-based methods, which takes a sequence of human skeletons only as input, suffer from inaccurate pose estimation or ambiguity of human pose per se. Integrating these two approaches has turned out to be non-trivial; training a model with both appearance and pose ends up with a strong bias towards appearance and does not generalize well to unseen videos. To address this problem, we propose to learn pose-driven feature integration that dynamically combines appearance and pose streams by observing pose features on the fly. The main idea is to let the pose stream decide how much and which appearance information is used in integration based on whether the given pose information is reliable or not. We show that the proposed IntegralAction achieves highly robust performance across in-context and out-of-context action video datasets.
NTIRE 2020 Challenge on Image and Video Deblurring
May 10, 2020
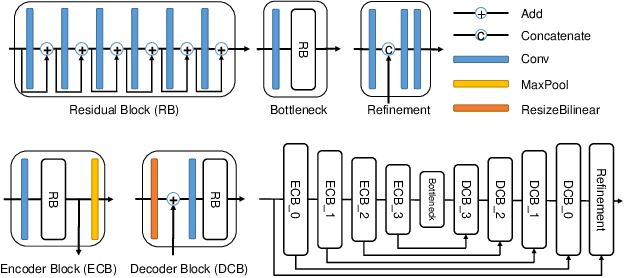
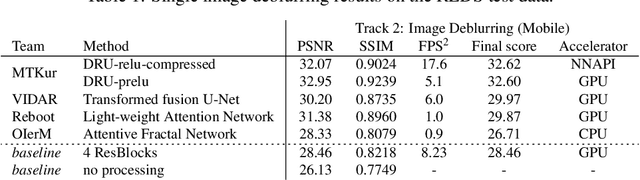
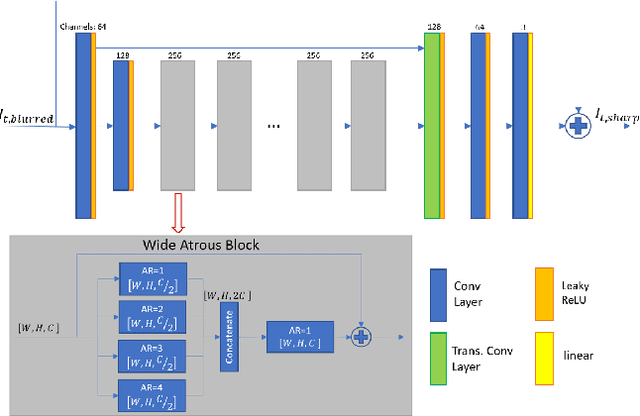
Motion blur is one of the most common degradation artifacts in dynamic scene photography. This paper reviews the NTIRE 2020 Challenge on Image and Video Deblurring. In this challenge, we present the evaluation results from 3 competition tracks as well as the proposed solutions. Track 1 aims to develop single-image deblurring methods focusing on restoration quality. On Track 2, the image deblurring methods are executed on a mobile platform to find the balance of the running speed and the restoration accuracy. Track 3 targets developing video deblurring methods that exploit the temporal relation between input frames. In each competition, there were 163, 135, and 102 registered participants and in the final testing phase, 9, 4, and 7 teams competed. The winning methods demonstrate the state-ofthe-art performance on image and video deblurring tasks.
AIM 2019 Challenge on Video Temporal Super-Resolution: Methods and Results
May 04, 2020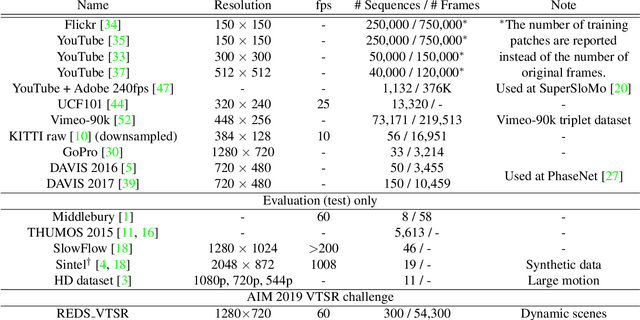

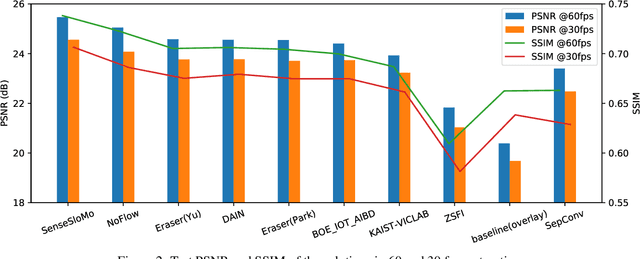
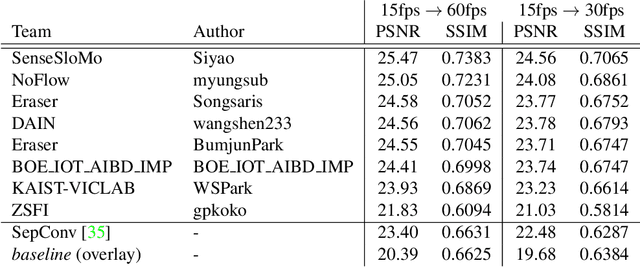
Videos contain various types and strengths of motions that may look unnaturally discontinuous in time when the recorded frame rate is low. This paper reviews the first AIM challenge on video temporal super-resolution (frame interpolation) with a focus on the proposed solutions and results. From low-frame-rate (15 fps) video sequences, the challenge participants are asked to submit higher-framerate (60 fps) video sequences by estimating temporally intermediate frames. We employ the REDS VTSR dataset derived from diverse videos captured in a hand-held camera for training and evaluation purposes. The competition had 62 registered participants, and a total of 8 teams competed in the final testing phase. The challenge winning methods achieve the state-of-the-art in video temporal superresolution.
* Published in ICCV 2019 Workshop (Advances in Image Manipulation)
Scene-Adaptive Video Frame Interpolation via Meta-Learning
Apr 02, 2020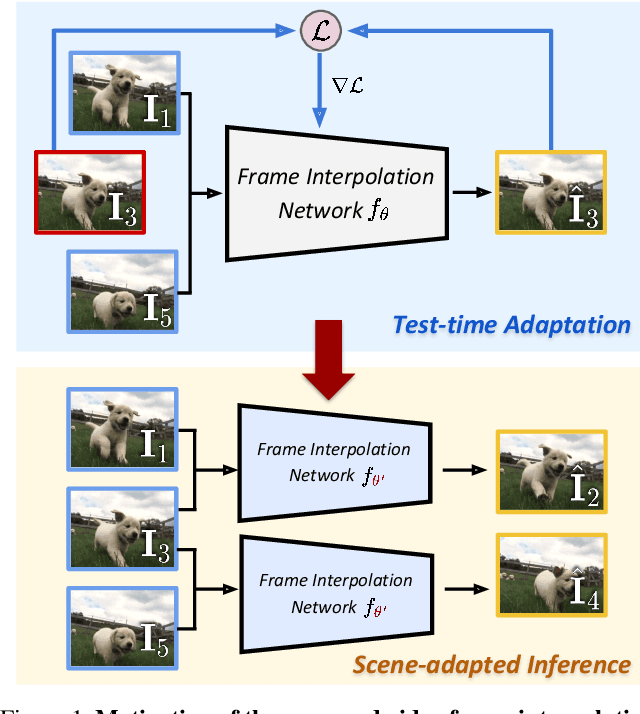

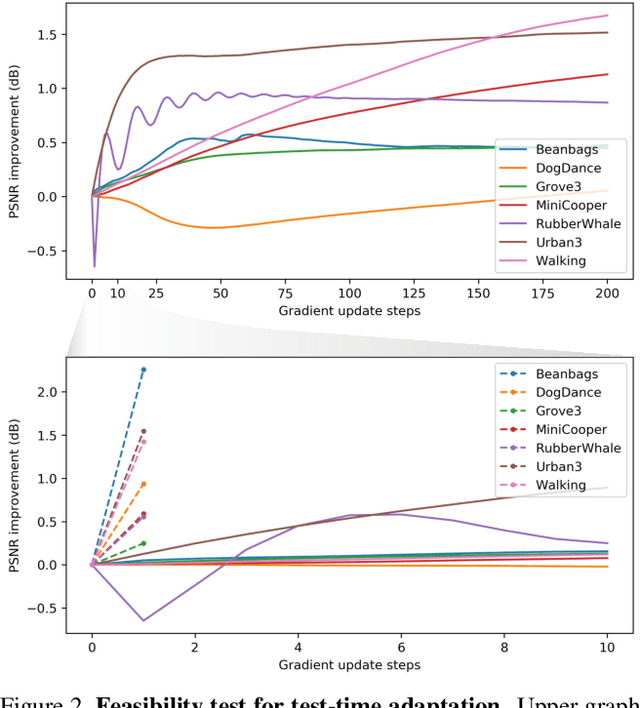

Video frame interpolation is a challenging problem because there are different scenarios for each video depending on the variety of foreground and background motion, frame rate, and occlusion. It is therefore difficult for a single network with fixed parameters to generalize across different videos. Ideally, one could have a different network for each scenario, but this is computationally infeasible for practical applications. In this work, we propose to adapt the model to each video by making use of additional information that is readily available at test time and yet has not been exploited in previous works. We first show the benefits of `test-time adaptation' through simple fine-tuning of a network, then we greatly improve its efficiency by incorporating meta-learning. We obtain significant performance gains with only a single gradient update without any additional parameters. Finally, we show that our meta-learning framework can be easily employed to any video frame interpolation network and can consistently improve its performance on multiple benchmark datasets.
Fine-Grained Neural Architecture Search
Nov 18, 2019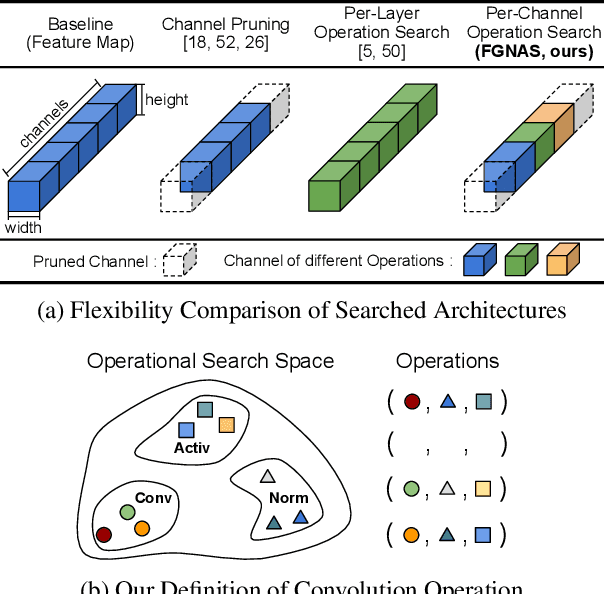

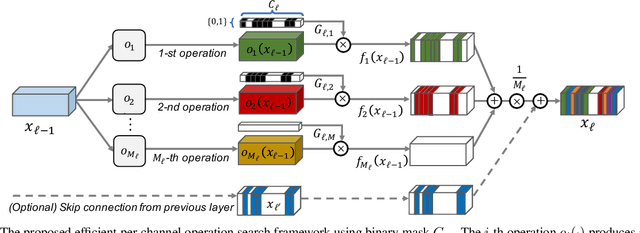

We present an elegant framework of fine-grained neural architecture search (FGNAS), which allows to employ multiple heterogeneous operations within a single layer and can even generate compositional feature maps using several different base operations. FGNAS runs efficiently in spite of significantly large search space compared to other methods because it trains networks end-to-end by a stochastic gradient descent method. Moreover, the proposed framework allows to optimize the network under predefined resource constraints in terms of number of parameters, FLOPs and latency. FGNAS has been applied to two crucial applications in resource demanding computer vision tasks---large-scale image classification and image super-resolution---and demonstrates the state-of-the-art performance through flexible operation search and channel pruning.
AbsPoseLifter: Absolute 3D Human Pose Lifting Network from a Single Noisy 2D Human Pose
Oct 26, 2019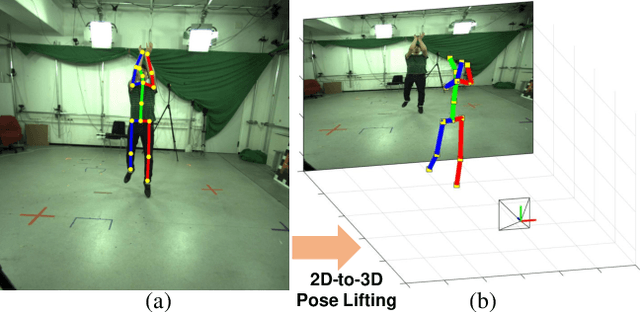
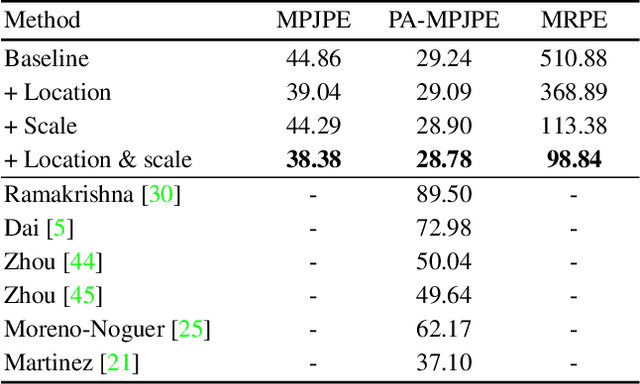
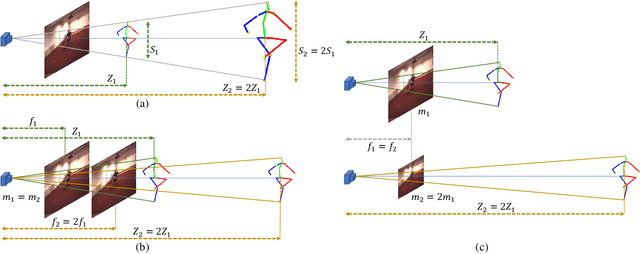
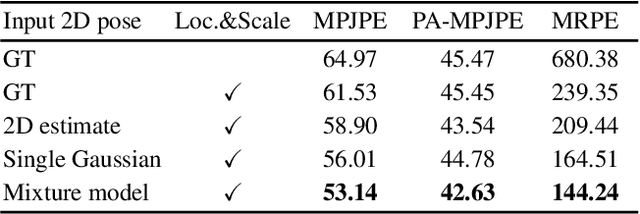
This study presents a new network (i.e., AbsPoseLifter) that lifts a 2D human pose to an absolute 3D pose in a camera coordinate system. The proposed network estimates the absolute 3D location of a target subject and also outputs a considerably improved 3D relative pose estimation compared with those of existing pose lifting methods. We also propose using our AbsPoseLifter with a 2D pose estimator in a cascade fashion to estimate 3D human pose from a single RGB image. In this case, we empirically prove that using realistic 2D poses synthesized with the real error distribution of 2D body joints considerably improves the performance of our AbsPoseLifter. The proposed method is applied to public datasets to achieve state-of-the-art 2D-to-3D pose lifting and 3D human pose estimation.
Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
Aug 17, 2019
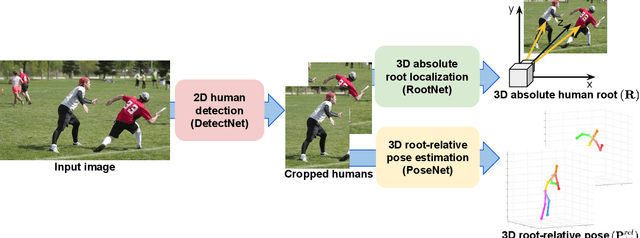
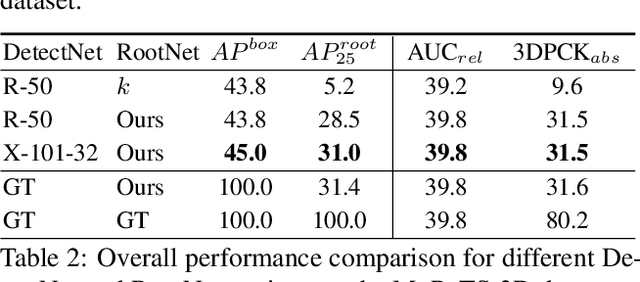
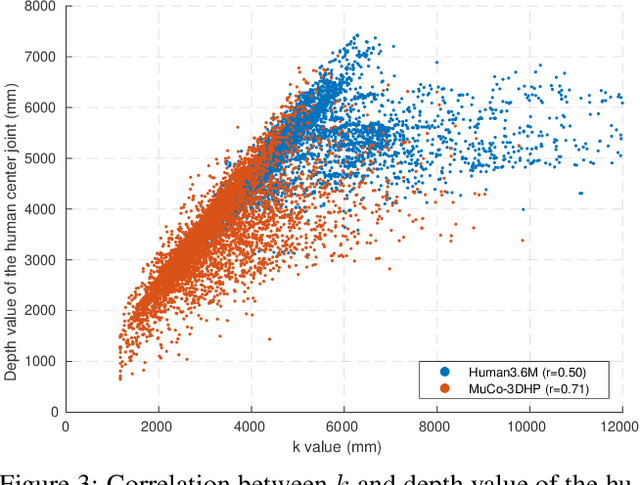
Although significant improvement has been achieved recently in 3D human pose estimation, most of the previous methods only treat a single-person case. In this work, we firstly propose a fully learning-based, camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. The pipeline of the proposed system consists of human detection, absolute 3D human root localization, and root-relative 3D single-person pose estimation modules. Our system achieves comparable results with the state-of-the-art 3D single-person pose estimation models without any groundtruth information and significantly outperforms previous 3D multi-person pose estimation methods on publicly available datasets. The code is available in https://github.com/mks0601/3DMPPE_ROOTNET_RELEASE , https://github.com/mks0601/3DMPPE_POSENET_RELEASE.
Continual Learning by Asymmetric Loss Approximation with Single-Side Overestimation
Aug 08, 2019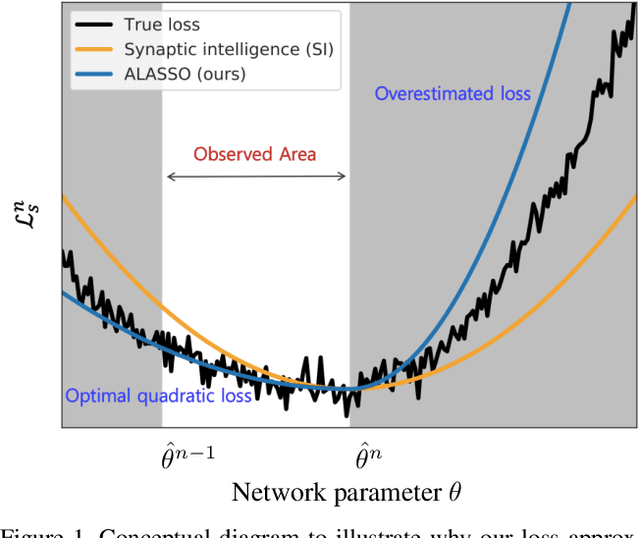

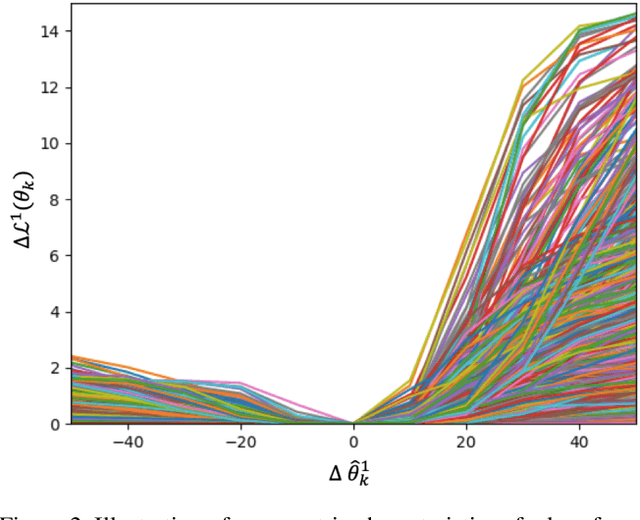
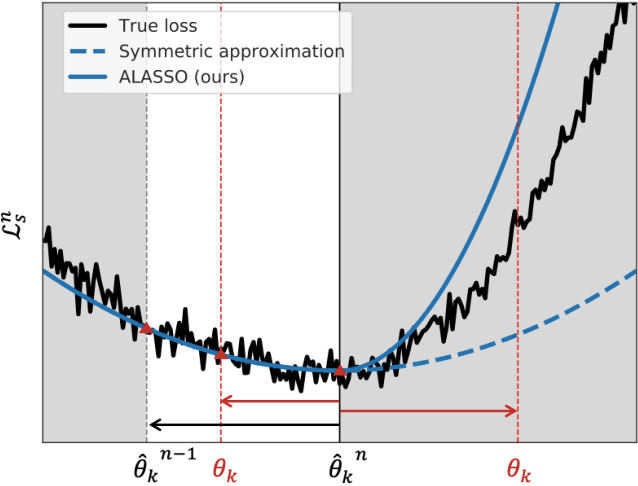
Catastrophic forgetting is a critical challenge in training deep neural networks. Although continual learning has been investigated as a countermeasure to the problem, it often suffers from requirements of additional network components and weak scalability to a large number of tasks. We propose a novel approach to continual learning by approximating a true loss function based on an asymmetric quadratic function with one of its sides overestimated. Our algorithm is motivated by the empirical observation that updates of network parameters affect target loss functions asymmetrically. In the proposed continual learning framework, we estimate an asymmetric loss function for the tasks considered in the past through a proper overestimation of its unobserved side in training new tasks, while deriving the accurate model parameter for the observed side. In contrast to existing approaches, our method is free from side effects and achieves the state-of-the-art results that are even close to the upper-bound performance on several challenging benchmark datasets.
Learning to Forget for Meta-Learning
Jun 13, 2019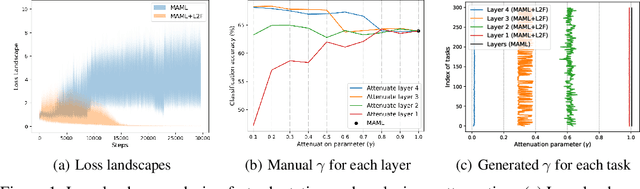
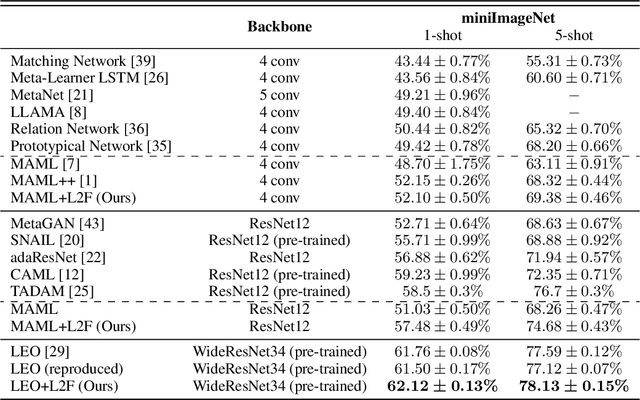
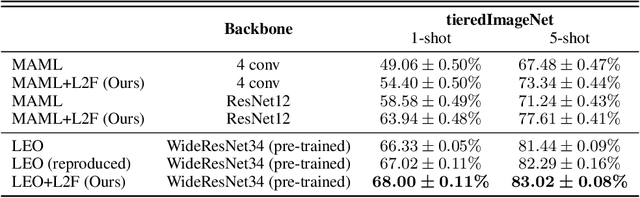
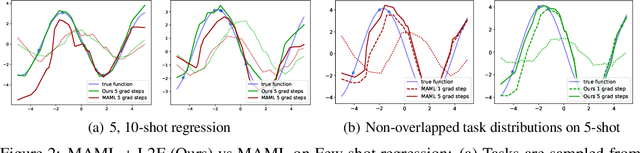
Few-shot learning is a challenging problem where the system is required to achieve generalization from only few examples. Meta-learning tackles the problem by learning prior knowledge shared across a distribution of tasks, which is then used to quickly adapt to unseen tasks. Model-agnostic meta-learning (MAML) algorithm formulates prior knowledge as a common initialization across tasks. However, forcibly sharing an initialization brings about conflicts between tasks and thus compromises the quality of the initialization. In this work, by observing that the extent of compromise differs among tasks and between layers of a neural network, we propose a new initialization idea that employs task-dependent layer-wise attenuation, which we call selective forgetting. The proposed attenuation scheme dynamically controls how much of prior knowledge each layer will exploit for a given task. The experimental results demonstrate that the proposed method mitigates the conflicts and provides outstanding performance as a result. We further show that the proposed method, named L2F, can be applied and improve other state-of-the-art MAML-based frameworks, illustrating its generalizability.
Multi-scale Aggregation R-CNN for 2D Multi-person Pose Estimation
May 10, 2019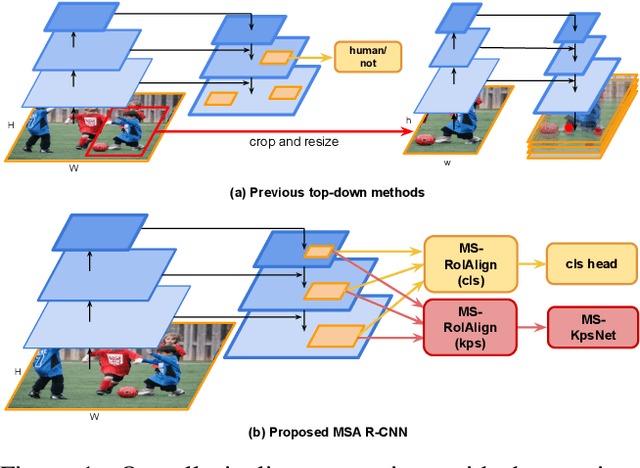
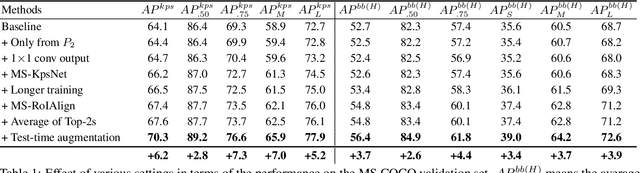
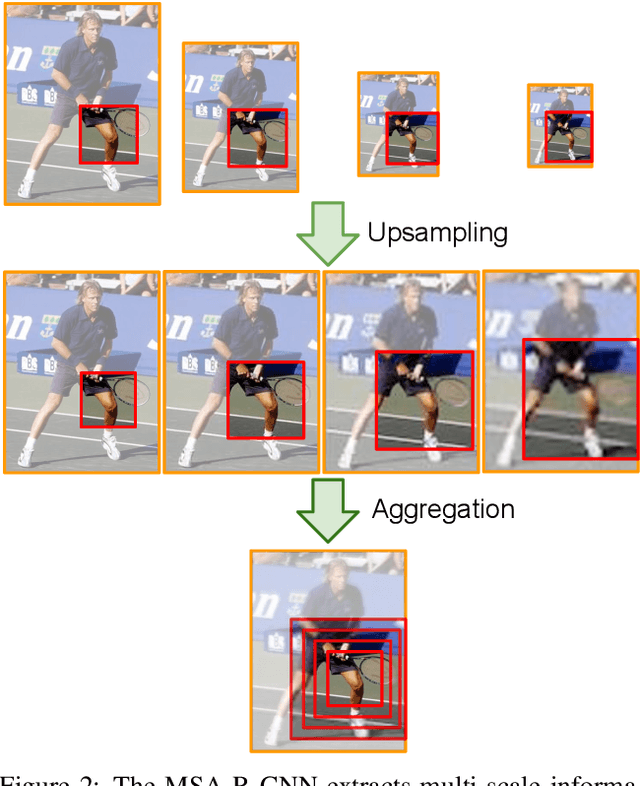
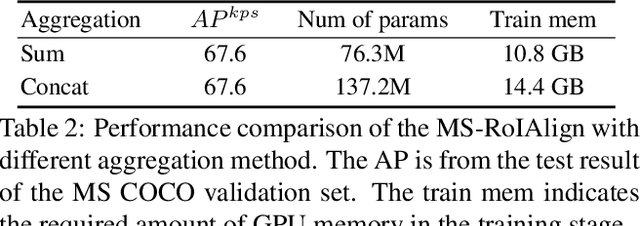
Multi-person pose estimation from a 2D image is challenging because it requires not only keypoint localization but also human detection. In state-of-the-art top-down methods, multi-scale information is a crucial factor for the accurate pose estimation because it contains both of local information around the keypoints and global information of the entire person. Although multi-scale information allows these methods to achieve the state-of-the-art performance, the top-down methods still require a huge amount of computation because they need to use an additional human detector to feed the cropped human image to their pose estimation model. To effectively utilize multi-scale information with the smaller computation, we propose a multi-scale aggregation R-CNN (MSA R-CNN). It consists of multi-scale RoIAlign block (MS-RoIAlign) and multi-scale keypoint head network (MS-KpsNet) which are designed to effectively utilize multi-scale information. Also, in contrast to previous top-down methods, the MSA R-CNN performs human detection and keypoint localization in a single model, which results in reduced computation. The proposed model achieved the best performance among single model-based methods and its results are comparable to those of separated model-based methods with a smaller amount of computation on the publicly available 2D multi-person keypoint localization dataset.