 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARK: Stochastic Propagation via Affinity-guided Random walK for training-free unsupervised segmentation
Jan 31, 2026We argue that existing training-free segmentation methods rely on an implicit and limiting assumption, that segmentation is a spectral graph partitioning problem over diffusion-derived affinities. Such approaches, based on global graph partitioning and eigenvector-based formulations of affinity matrices, suffer from several fundamental drawbacks, they require pre-selecting the number of clusters, induce boundary oversmoothing due to spectral relaxation, and remain highly sensitive to noisy or multi-modal affinity distributions. Moreover, many prior works neglect the importance of local neighborhood structure, which plays a crucial role in stabilizing affinity propagation and preserving fine-grained contours. To address these limitations, we reformulate training-free segmentation as a stochastic flow equilibrium problem over diffusion-induced affinity graphs, where segmentation emerges from a stochastic propagation process that integrates global diffusion attention with local neighborhoods extracted from stable diffusion, yielding a sparse yet expressive affinity structure. Building on this formulation, we introduce a Markov propagation scheme that performs random-walk-based label diffusion with an adaptive pruning strategy that suppresses unreliable transitions while reinforcing confident affinity paths. Experiments across seven widely used semantic segmentation benchmarks demonstrate that our method achieves state-of-the-art zero-shot performance, producing sharper boundaries, more coherent regions, and significantly more stable masks compared to prior spectral-clustering-based approaches.
OCTOPUS: Enhancing the Spatial-Awareness of Vision SSMs with Multi-Dimensional Scans and Traversal Selection
Jan 31, 2026State space models (SSMs) have recently emerged as an alternative to transformers due to their unique ability of modeling global relationships in text with linear complexity. However, their success in vision tasks has been limited due to their causal formulation, which is suitable for sequential text but detrimental in the spatial domain where causality breaks the inherent spatial relationships among pixels or patches. As a result, standard SSMs fail to capture local spatial coherence, often linking non-adjacent patches while ignoring neighboring ones that are visually correlated. To address these limitations, we introduce OCTOPUS , a novel architecture that preserves both global context and local spatial structure within images, while maintaining the linear complexity of SSMs. OCTOPUS performs discrete reoccurrence along eight principal orientations, going forward or backward in the horizontal, vertical, and diagonal directions, allowing effective information exchange across all spatially connected regions while maintaining independence among unrelated patches. This design enables multi-directional recurrence, capturing both global context and local spatial structure with SSM-level efficiency. In our classification and segmentation benchmarks, OCTOPUS demonstrates notable improvements in boundary preservation and region consistency, as evident from the segmentation results, while maintaining relatively better classification accuracy compared to existing V-SSM based models. These results suggest that OCTOPUS appears as a foundation method for multi-directional recurrence as a scalable and effective mechanism for building spatially aware and computationally efficient vision architectures.
NERVE: Neighbourhood & Entropy-guided Random-walk for training free open-Vocabulary sEgmentation
Nov 11, 2025Despite recent advances in Open-Vocabulary Semantic Segmentation (OVSS), existing training-free methods face several limitations: use of computationally expensive affinity refinement strategies, ineffective fusion of transformer attention maps due to equal weighting or reliance on fixed-size Gaussian kernels to reinforce local spatial smoothness, enforcing isotropic neighborhoods. We propose a strong baseline for training-free OVSS termed as NERVE (Neighbourhood \& Entropy-guided Random-walk for open-Vocabulary sEgmentation), which uniquely integrates global and fine-grained local information, exploiting the neighbourhood structure from the self-attention layer of a stable diffusion model. We also introduce a stochastic random walk for refining the affinity rather than relying on fixed-size Gaussian kernels for local context. This spatial diffusion process encourages propagation across connected and semantically related areas, enabling it to effectively delineate objects with arbitrary shapes. Whereas most existing approaches treat self-attention maps from different transformer heads or layers equally, our method uses entropy-based uncertainty to select the most relevant maps. Notably, our method does not require any conventional post-processing techniques like Conditional Random Fields (CRF) or Pixel-Adaptive Mask Refinement (PAMR). Experiments are performed on 7 popular semantic segmentation benchmarks, yielding an overall state-of-the-art zero-shot segmentation performance, providing an effective approach to open-vocabulary semantic segmentation.
THUNDER: Tile-level Histopathology image UNDERstanding benchmark
Jul 10, 2025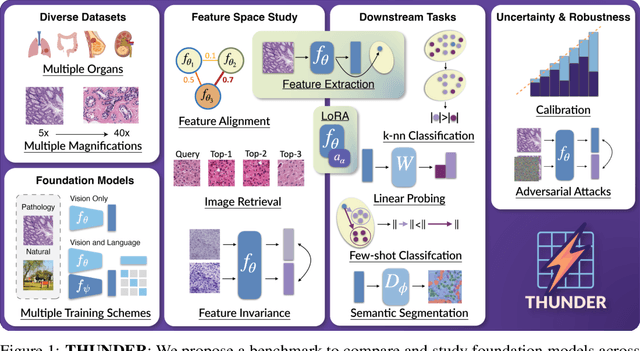
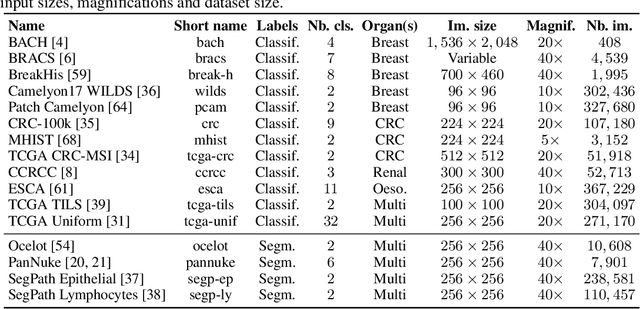
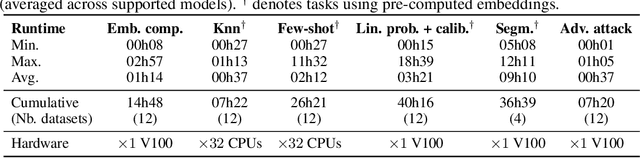
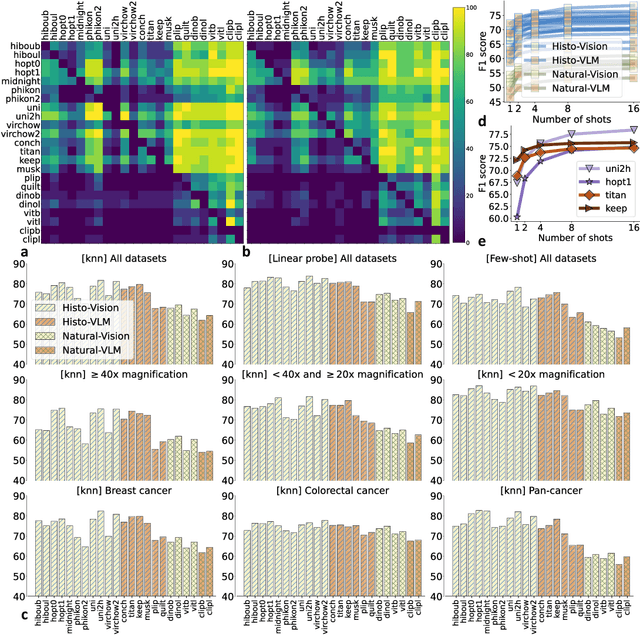
Progress in a research field can be hard to assess, in particular when many concurrent methods are proposed in a short period of time. This is the case in digital pathology, where many foundation models have been released recently to serve as feature extractors for tile-level images, being used in a variety of downstream tasks, both for tile- and slide-level problems. Benchmarking available methods then becomes paramount to get a clearer view of the research landscape. In particular, in critical domains such as healthcare, a benchmark should not only focus on evaluating downstream performance, but also provide insights about the main differences between methods, and importantly, further consider uncertainty and robustness to ensure a reliable usage of proposed models. For these reasons, we introduce THUNDER, a tile-level benchmark for digital pathology foundation models, allowing for efficient comparison of many models on diverse datasets with a series of downstream tasks, studying their feature spaces and assessing the robustness and uncertainty of predictions informed by their embeddings. THUNDER is a fast, easy-to-use, dynamic benchmark that can already support a large variety of state-of-the-art foundation, as well as local user-defined models for direct tile-based comparison. In this paper, we provide a comprehensive comparison of 23 foundation models on 16 different datasets covering diverse tasks, feature analysis, and robustness. The code for THUNDER is publicly available at https://github.com/MICS-Lab/thunder.