 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrafting Vision Transformers
Oct 28, 2022



Vision Transformers (ViTs) have recently become the state-of-the-art across many computer vision tasks. In contrast to convolutional networks (CNNs), ViTs enable global information sharing even within shallow layers of a network, i.e., among high-resolution features. However, this perk was later overlooked with the success of pyramid architectures such as Swin Transformer, which show better performance-complexity trade-offs. In this paper, we present a simple and efficient add-on component (termed GrafT) that considers global dependencies and multi-scale information throughout the network, in both high- and low-resolution features alike. GrafT can be easily adopted in both homogeneous and pyramid Transformers while showing consistent gains. It has the flexibility of branching-out at arbitrary depths, widening a network with multiple scales. This grafting operation enables us to share most of the parameters and computations of the backbone, adding only minimal complexity, but with a higher yield. In fact, the process of progressively compounding multi-scale receptive fields in GrafT enables communications between local regions. We show the benefits of the proposed method on multiple benchmarks, including image classification (ImageNet-1K), semantic segmentation (ADE20K), object detection and instance segmentation (COCO2017). Our code and models will be made available.
MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection
Dec 07, 2021
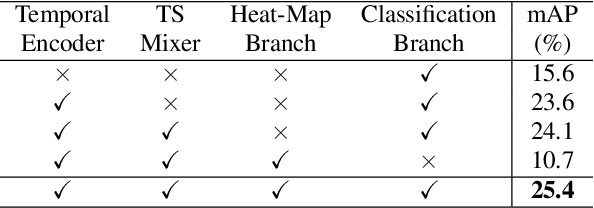
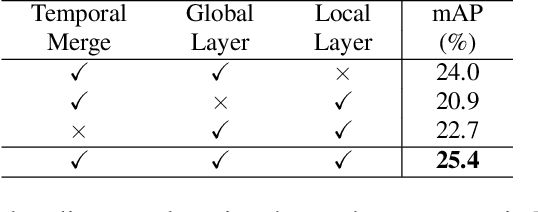
Action detection is an essential and challenging task, especially for densely labelled datasets of untrimmed videos. The temporal relation is complex in those datasets, including challenges like composite action, and co-occurring action. For detecting actions in those complex videos, efficiently capturing both short-term and long-term temporal information in the video is critical. To this end, we propose a novel ConvTransformer network for action detection. This network comprises three main components: (1) Temporal Encoder module extensively explores global and local temporal relations at multiple temporal resolutions. (2) Temporal Scale Mixer module effectively fuses the multi-scale features to have a unified feature representation. (3) Classification module is used to learn the instance center-relative position and predict the frame-level classification scores. The extensive experiments on multiple datasets, including Charades, TSU and MultiTHUMOS, confirm the effectiveness of our proposed method. Our network outperforms the state-of-the-art methods on all three datasets.
SWAT: Spatial Structure Within and Among Tokens
Nov 26, 2021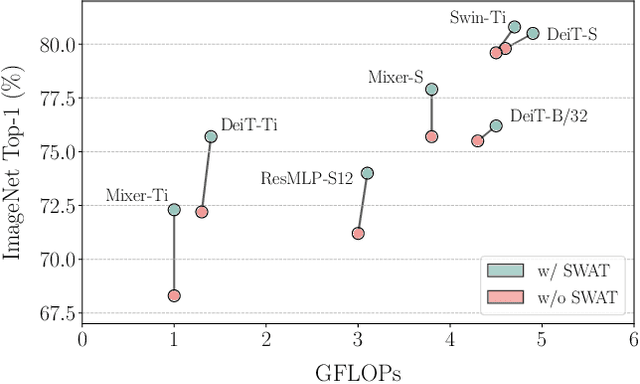
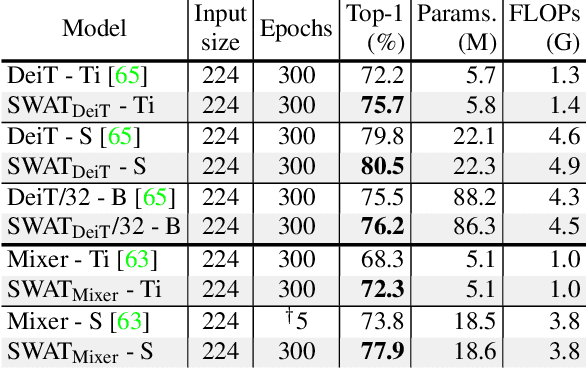
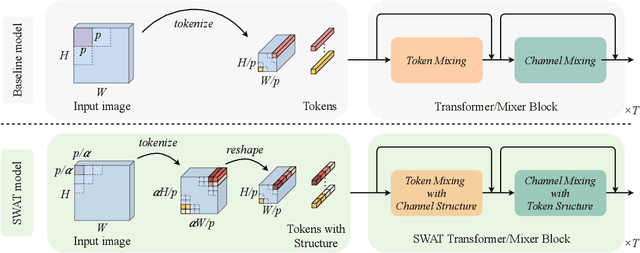
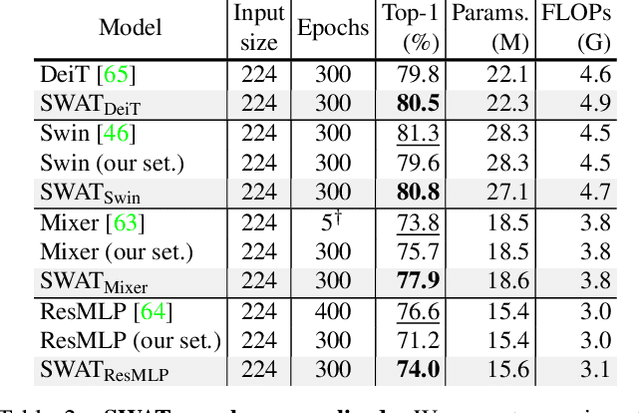
Modeling visual data as tokens (i.e., image patches), and applying attention mechanisms or feed-forward networks on top of them has shown to be highly effective in recent years. The common pipeline in such approaches includes a tokenization method, followed by a set of layers/blocks for information mixing, both within tokens and among tokens. In common practice, image patches are flattened when converted into tokens, discarding the spatial structure within each patch. Next, a module such as multi-head self-attention captures the pairwise relations among the tokens and mixes them. In this paper, we argue that models can have significant gains when spatial structure is preserved in tokenization, and is explicitly used in the mixing stage. We propose two key contributions: (1) Structure-aware Tokenization and, (2) Structure-aware Mixing, both of which can be combined with existing models with minimal effort. We introduce a family of models (SWAT), showing improvements over the likes of DeiT, MLP-Mixer and Swin Transformer, across multiple benchmarks including ImageNet classification and ADE20K segmentation. Our code and models will be released online.
Self-supervised Pretraining with Classification Labels for Temporal Activity Detection
Nov 26, 2021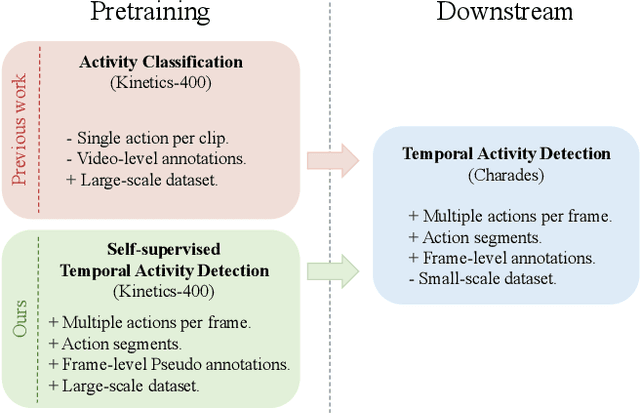
Temporal Activity Detection aims to predict activity classes per frame, in contrast to video-level predictions as done in Activity Classification (i.e., Activity Recognition). Due to the expensive frame-level annotations required for detection, the scale of detection datasets is limited. Thus, commonly, previous work on temporal activity detection resorts to fine-tuning a classification model pretrained on large-scale classification datasets (e.g., Kinetics-400). However, such pretrained models are not ideal for downstream detection performance due to the disparity between the pretraining and the downstream fine-tuning tasks. This work proposes a novel self-supervised pretraining method for detection leveraging classification labels to mitigate such disparity by introducing frame-level pseudo labels, multi-action frames, and action segments. We show that the models pretrained with the proposed self-supervised detection task outperform prior work on multiple challenging activity detection benchmarks, including Charades and MultiTHUMOS. Our extensive ablations further provide insights on when and how to use the proposed models for activity detection. Code and models will be released online.
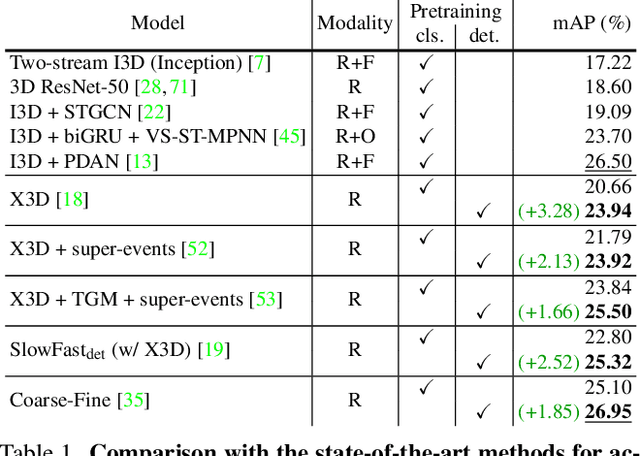
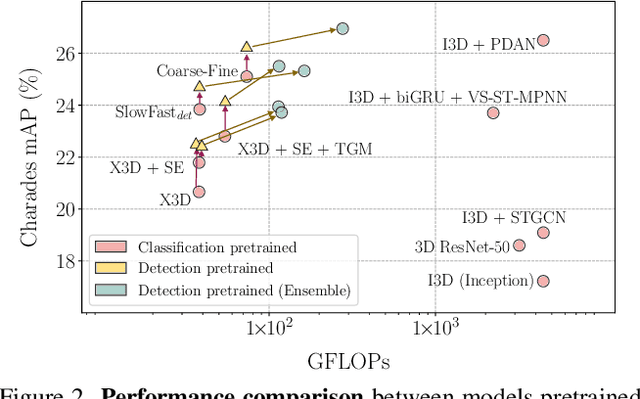
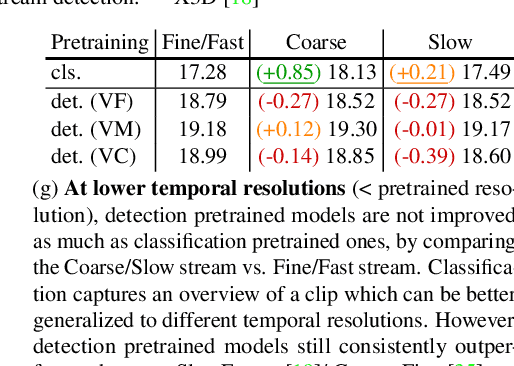
Coarse-Fine Networks for Temporal Activity Detection in Videos
Apr 01, 2021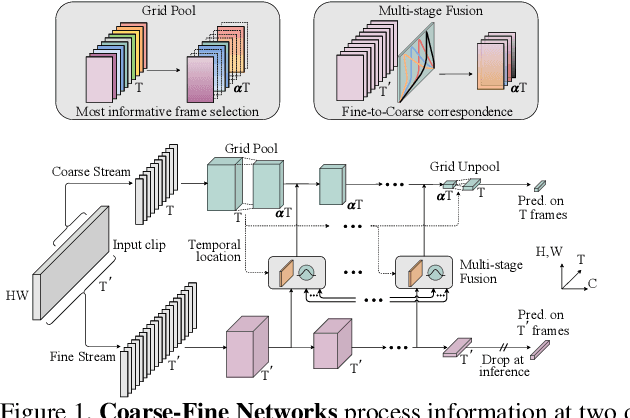
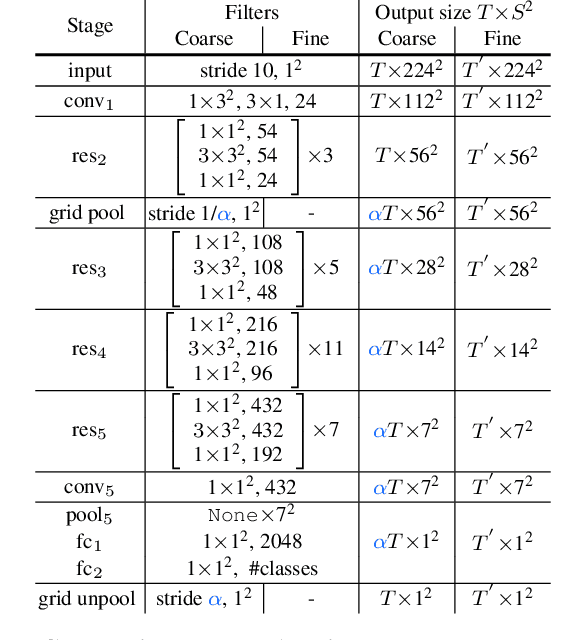
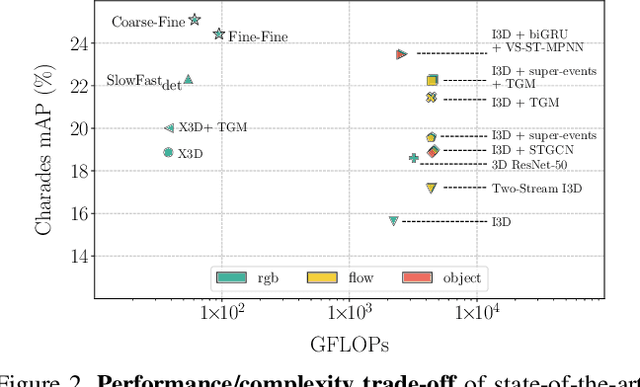
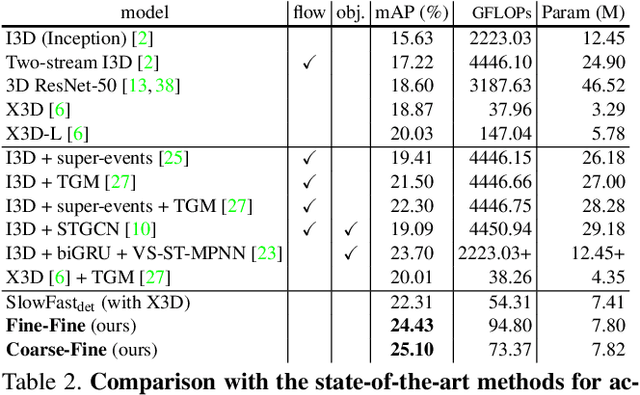
In this paper, we introduce Coarse-Fine Networks, a two-stream architecture which benefits from different abstractions of temporal resolution to learn better video representations for long-term motion. Traditional Video models process inputs at one (or few) fixed temporal resolution without any dynamic frame selection. However, we argue that, processing multiple temporal resolutions of the input and doing so dynamically by learning to estimate the importance of each frame can largely improve video representations, specially in the domain of temporal activity localization. To this end, we propose (1) Grid Pool, a learned temporal downsampling layer to extract coarse features, and, (2) Multi-stage Fusion, a spatio-temporal attention mechanism to fuse a fine-grained context with the coarse features. We show that our method outperforms the state-of-the-arts for action detection in public datasets including Charades with a significantly reduced compute and memory footprint. The code is available at https://github.com/kkahatapitiya/Coarse-Fine-Networks
Feature-dependent Cross-Connections in Multi-Path Neural Networks
Jun 24, 2020
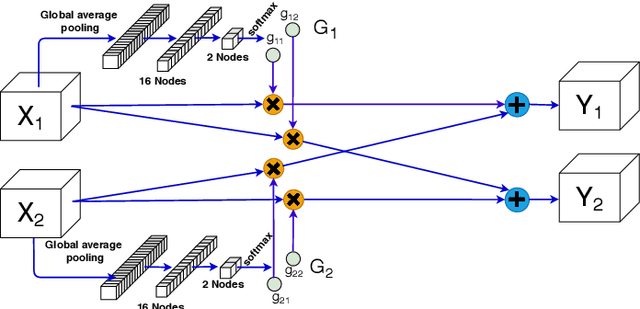

Learning a particular task from a dataset, samples in which originate from diverse contexts, is challenging, and usually addressed by deepening or widening standard neural networks. As opposed to conventional network widening, multi-path architectures restrict the quadratic increment of complexity to a linear scale. However, existing multi-column/path networks or model ensembling methods do not consider any feature-dependent allocation of parallel resources, and therefore, tend to learn redundant features. Given a layer in a multi-path network, if we restrict each path to learn a context-specific set of features and introduce a mechanism to intelligently allocate incoming feature maps to such paths, each path can specialize in a certain context, reducing the redundancy and improving the quality of extracted features. This eventually leads to better-optimized usage of parallel resources. To do this, we propose inserting feature-dependent cross-connections between parallel sets of feature maps in successive layers. The weights of these cross-connections are learned based on the input features of the particular layer. Our multi-path networks show improved image recognition accuracy at a similar complexity compared to conventional and state-of-the-art methods for deepening, widening and adaptive feature extracting, in both small and large scale datasets.
Context-Aware Multipath Networks
Jul 26, 2019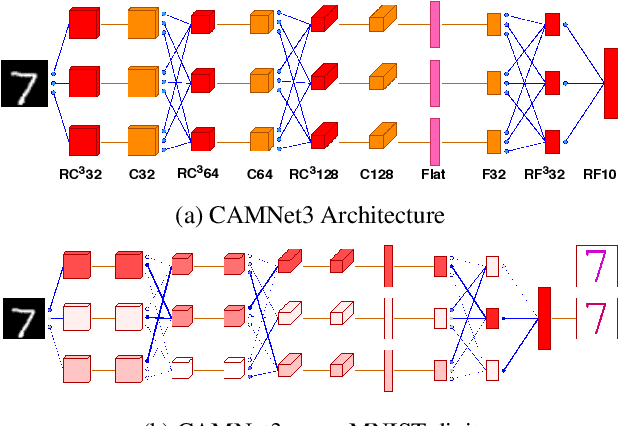

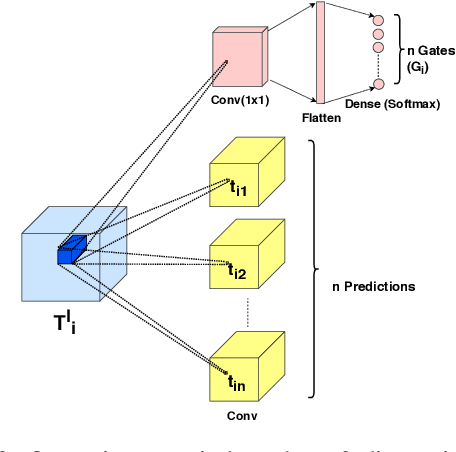
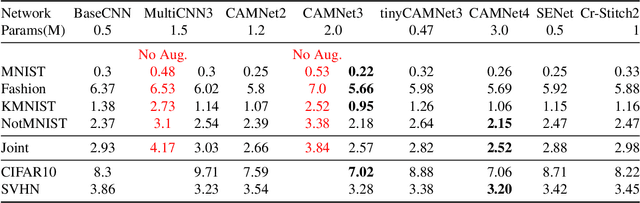
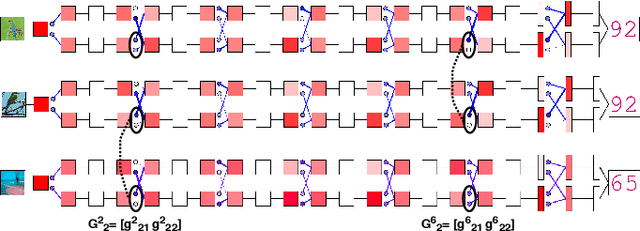
Making a single network effectively address diverse contexts---learning the variations within a dataset or multiple datasets---is an intriguing step towards achieving generalized intelligence. Existing approaches of deepening, widening, and assembling networks are not cost effective in general. In view of this, networks which can allocate resources according to the context of the input and regulate flow of information across the network are effective. In this paper, we present Context-Aware Multipath Network (CAMNet), a multi-path neural network with data-dependant routing between parallel tensors. We show that our model performs as a generalized model capturing variations in individual datasets and multiple different datasets, both simultaneously and sequentially. CAMNet surpasses the performance of classification and pixel-labeling tasks in comparison with the equivalent single-path, multi-path, and deeper single-path networks, considering datasets individually, sequentially, and in combination. The data-dependent routing between tensors in CAMNet enables the model to control the flow of information end-to-end, deciding which resources to be common or domain-specific.
LinearConv: Regenerating Redundancy in Convolution Filters as Linear Combinations for Parameter Reduction
Jul 26, 2019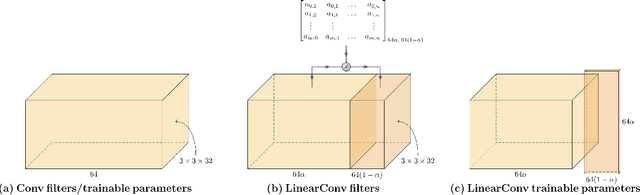

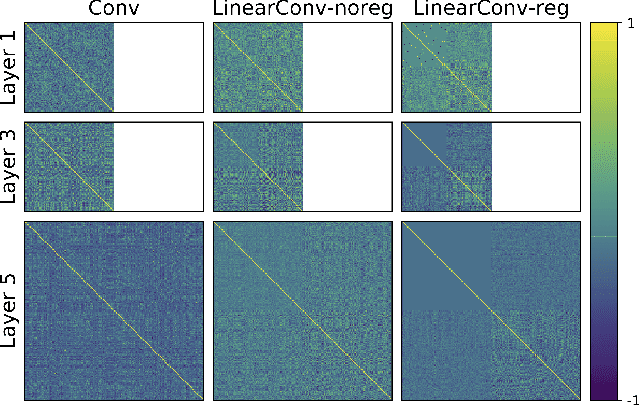
Convolutional Neural Networks (CNNs) show state-of-the-art performance in computer vision tasks. However, convolutional layers of CNNs are known to learn redundant features, still not being efficient in memory requirement. In this work, we explore the redundancy of learned features in the form of correlation between convolutional filters, and propose a novel layer to reproduce it efficiently. The proposed "LinearConv" layer generates a portion of convolutional filters as a learnable linear combination of the rest of the filters and introduces a correlation-based regularization to achieve flexibility and control over the correlation between filters, and the number of parameters, in turn. This is developed as a plug-in layer to conveniently replace a conventional convolutional layer without any modification required in the network architecture. Our experiments verify that the LinearConv-based models are able to achieve a performance on-par with counterparts with up to 50% of parameter reduction, and having same computational requirement in run time.
Context-Aware Automatic Occlusion Removal
May 07, 2019

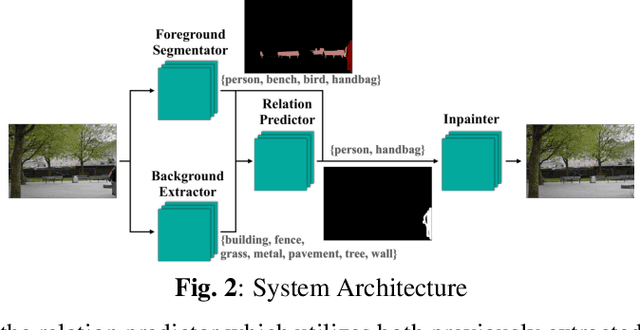

Occlusion removal is an interesting application of image enhancement, for which, existing work suggests manually-annotated or domain-specific occlusion removal. No work tries to address automatic occlusion detection and removal as a context-aware generic problem. In this paper, we present a novel methodology to identify objects that do not relate to the image context as occlusions and remove them, reconstructing the space occupied coherently. The proposed system detects occlusions by considering the relation between foreground and background object classes represented as vector embeddings, and removes them through inpainting. We test our system on COCO-Stuff dataset and conduct a user study to establish a baseline in context-aware automatic occlusion removal.