 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpDetect: Interpretable Signals for Detecting Hallucinations in Retrieval-Augmented Generation
Oct 24, 2025Retrieval-Augmented Generation (RAG) integrates external knowledge to mitigate hallucinations, yet models often generate outputs inconsistent with retrieved content. Accurate hallucination detection requires disentangling the contributions of external context and parametric knowledge, which prior methods typically conflate. We investigate the mechanisms underlying RAG hallucinations and find they arise when later-layer FFN modules disproportionately inject parametric knowledge into the residual stream. To address this, we explore a mechanistic detection approach based on external context scores and parametric knowledge scores. Using Qwen3-0.6b, we compute these scores across layers and attention heads and train regression-based classifiers to predict hallucinations. Our method is evaluated against state-of-the-art LLMs (GPT-5, GPT-4.1) and detection baselines (RAGAS, TruLens, RefChecker). Furthermore, classifiers trained on Qwen3-0.6b signals generalize to GPT-4.1-mini responses, demonstrating the potential of proxy-model evaluation. Our results highlight mechanistic signals as efficient, generalizable predictors for hallucination detection in RAG systems.
FRED: Financial Retrieval-Enhanced Detection and Editing of Hallucinations in Language Models
Jul 28, 2025Hallucinations in large language models pose a critical challenge for applications requiring factual reliability, particularly in high-stakes domains such as finance. This work presents an effective approach for detecting and editing factually incorrect content in model-generated responses based on the provided context. Given a user-defined domain-specific error taxonomy, we construct a synthetic dataset by inserting tagged errors into financial question-answering corpora and then fine-tune four language models, Phi-4, Phi-4-mini, Qwen3-4B, and Qwen3-14B, to detect and edit these factual inaccuracies. Our best-performing model, fine-tuned Phi-4, achieves an 8% improvement in binary F1 score and a 30% gain in overall detection performance compared to OpenAI-o3. Notably, our fine-tuned Phi-4-mini model, despite having only 4 billion parameters, maintains competitive performance with just a 2% drop in binary detection and a 0.1% decline in overall detection compared to OpenAI-o3. Our work provides a practical solution for detecting and editing factual inconsistencies in financial text generation while introducing a generalizable framework that can enhance the trustworthiness and alignment of large language models across diverse applications beyond finance. Our code and data are available at https://github.com/pegasi-ai/fine-grained-editting.
Strong Gravitational Lensing Parameter Estimation with Vision Transformer
Oct 09, 2022
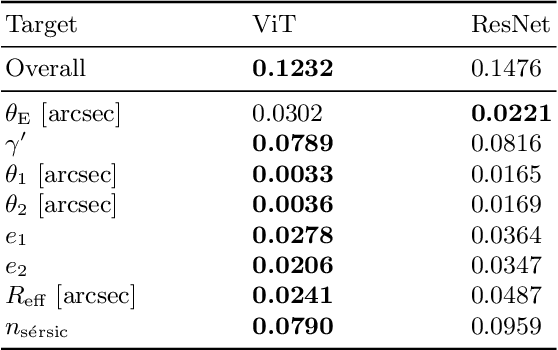
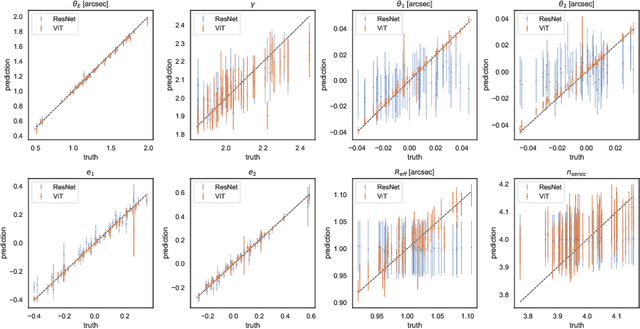
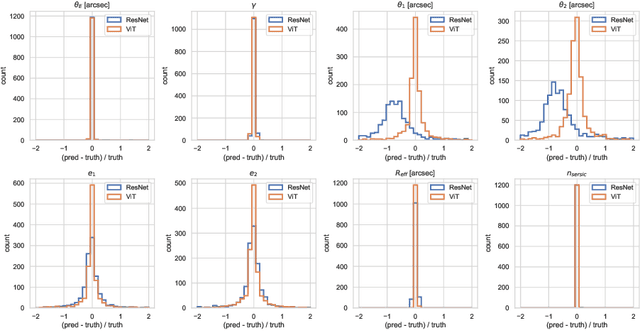
Quantifying the parameters and corresponding uncertainties of hundreds of strongly lensed quasar systems holds the key to resolving one of the most important scientific questions: the Hubble constant ($H_{0}$) tension. The commonly used Markov chain Monte Carlo (MCMC) method has been too time-consuming to achieve this goal, yet recent work has shown that convolution neural networks (CNNs) can be an alternative with seven orders of magnitude improvement in speed. With 31,200 simulated strongly lensed quasar images, we explore the usage of Vision Transformer (ViT) for simulated strong gravitational lensing for the first time. We show that ViT could reach competitive results compared with CNNs, and is specifically good at some lensing parameters, including the most important mass-related parameters such as the center of lens $\theta_{1}$ and $\theta_{2}$, the ellipticities $e_1$ and $e_2$, and the radial power-law slope $\gamma'$. With this promising preliminary result, we believe the ViT (or attention-based) network architecture can be an important tool for strong lensing science for the next generation of surveys. The open source of our code and data is in \url{https://github.com/kuanweih/strong_lensing_vit_resnet}.