 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Instabilities in Algorithmic Feedback Loops
Jan 18, 2022Algorithms that aid human tasks, such as recommendation systems, are ubiquitous. They appear in everything from social media to streaming videos to online shopping. However, the feedback loop between people and algorithms is poorly understood and can amplify cognitive and social biases (algorithmic confounding), leading to unexpected outcomes. In this work, we explore algorithmic confounding in collaborative filtering-based recommendation algorithms through teacher-student learning simulations. Namely, a student collaborative filtering-based model, trained on simulated choices, is used by the recommendation algorithm to recommend items to agents. Agents might choose some of these items, according to an underlying teacher model, with new choices then fed back into the student model as new training data (approximating online machine learning). These simulations demonstrate how algorithmic confounding produces erroneous recommendations which in turn lead to instability, i.e., wide variations in an item's popularity between each simulation realization. We use the simulations to demonstrate a novel approach to training collaborative filtering models that can create more stable and accurate recommendations. Our methodology is general enough that it can be extended to other socio-technical systems in order to better quantify and improve the stability of algorithms. These results highlight the need to account for emergent behaviors from interactions between people and algorithms.
Heterogeneous Effects of Software Patches in a Multiplayer Online Battle Arena Game
Oct 27, 2021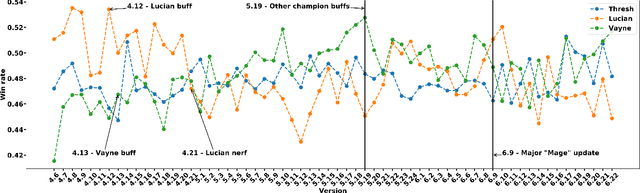
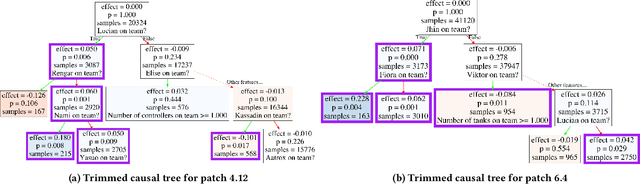

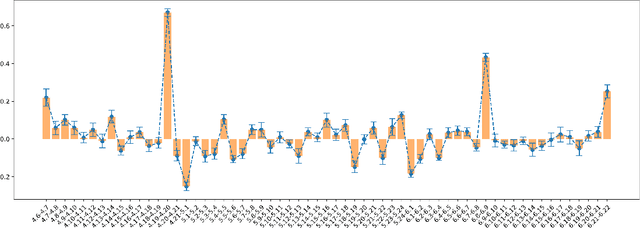
The popularity of online gaming has grown dramatically, driven in part by streaming and the billion-dollar e-sports industry. Online games regularly update their software to fix bugs, add functionality that improve the game's look and feel, and change the game mechanics to keep the games fun and challenging. An open question, however, is the impact of these changes on player performance and game balance, as well as how players adapt to these sudden changes. To address these questions, we use causal inference to measure the impact of software patches to League of Legends, a popular team-based multiplayer online game. We show that game patches have substantially different impacts on players depending on their skill level and whether they take breaks between games. We find that the gap between good and bad players increases after a patch, despite efforts to make gameplay more equal. Moreover, longer between-game breaks tend to improve player performance after patches. Overall, our results highlight the utility of causal inference, and specifically heterogeneous treatment effect estimation, as a tool to quantify the complex mechanisms of game balance and its interplay with players' performance.
* 9 pages, 11 figures
Speaker Turn Modeling for Dialogue Act Classification
Sep 10, 2021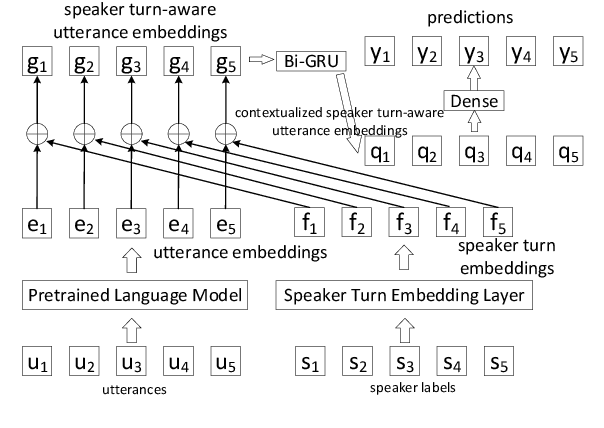

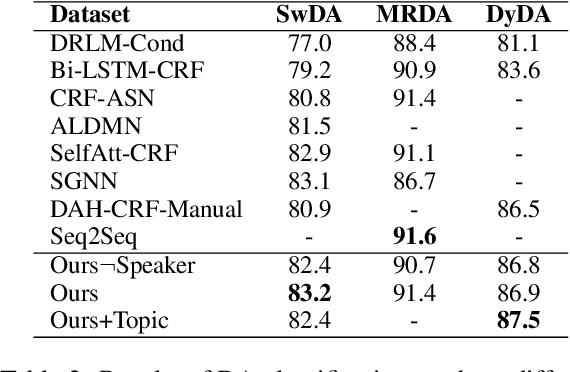
Dialogue Act (DA) classification is the task of classifying utterances with respect to the function they serve in a dialogue. Existing approaches to DA classification model utterances without incorporating the turn changes among speakers throughout the dialogue, therefore treating it no different than non-interactive written text. In this paper, we propose to integrate the turn changes in conversations among speakers when modeling DAs. Specifically, we learn conversation-invariant speaker turn embeddings to represent the speaker turns in a conversation; the learned speaker turn embeddings are then merged with the utterance embeddings for the downstream task of DA classification. With this simple yet effective mechanism, our model is able to capture the semantics from the dialogue content while accounting for different speaker turns in a conversation. Validation on three benchmark public datasets demonstrates superior performance of our model.
DoGR: Disaggregated Gaussian Regression for Reproducible Analysis of Heterogeneous Data
Aug 31, 2021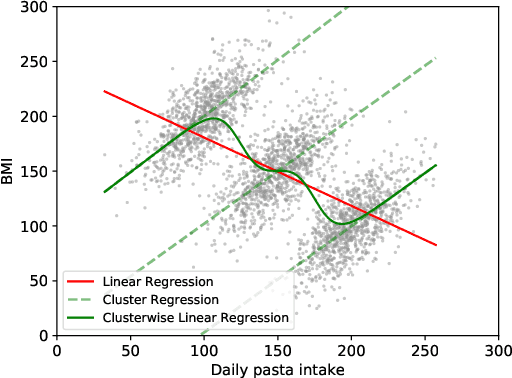
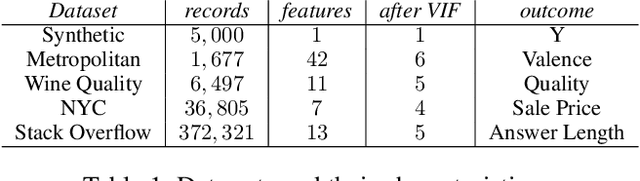
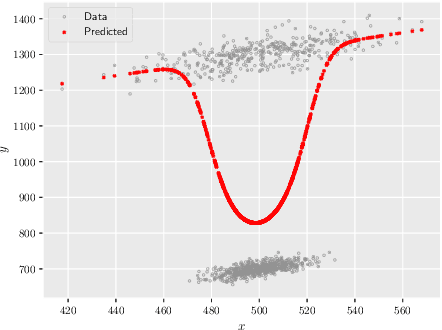
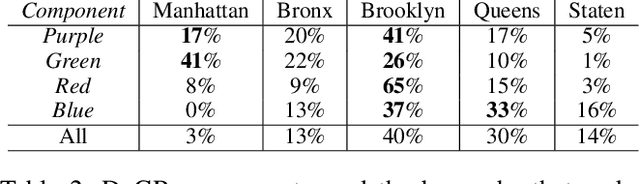
Quantitative analysis of large-scale data is often complicated by the presence of diverse subgroups, which reduce the accuracy of inferences they make on held-out data. To address the challenge of heterogeneous data analysis, we introduce DoGR, a method that discovers latent confounders by simultaneously partitioning the data into overlapping clusters (disaggregation) and modeling the behavior within them (regression). When applied to real-world data, our method discovers meaningful clusters and their characteristic behaviors, thus giving insight into group differences and their impact on the outcome of interest. By accounting for latent confounders, our framework facilitates exploratory analysis of noisy, heterogeneous data and can be used to learn predictive models that better generalize to new data. We provide the code to enable others to use DoGR within their data analytic workflows.
Pattern Discovery in Time Series with Byte Pair Encoding
May 30, 2021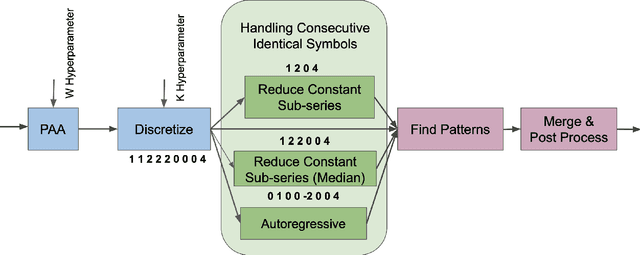
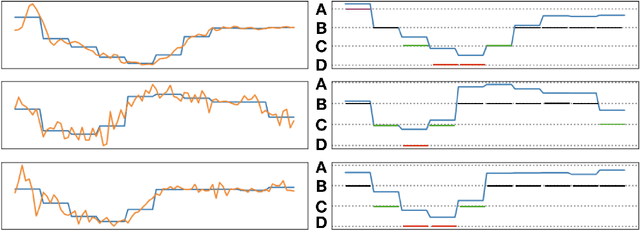
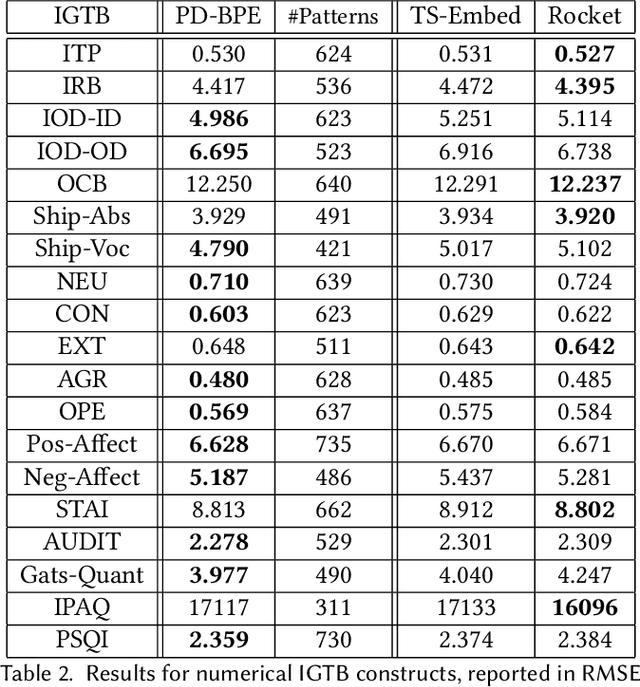
The growing popularity of wearable sensors has generated large quantities of temporal physiological and activity data. Ability to analyze this data offers new opportunities for real-time health monitoring and forecasting. However, temporal physiological data presents many analytic challenges: the data is noisy, contains many missing values, and each series has a different length. Most methods proposed for time series analysis and classification do not handle datasets with these characteristics nor do they offer interpretability and explainability, a critical requirement in the health domain. We propose an unsupervised method for learning representations of time series based on common patterns identified within them. The patterns are, interpretable, variable in length, and extracted using Byte Pair Encoding compression technique. In this way the method can capture both long-term and short-term dependencies present in the data. We show that this method applies to both univariate and multivariate time series and beats state-of-the-art approaches on a real world dataset collected from wearable sensors.
Detecting Polarized Topics in COVID-19 News Using Partisanship-aware Contextualized Topic Embeddings
Apr 15, 2021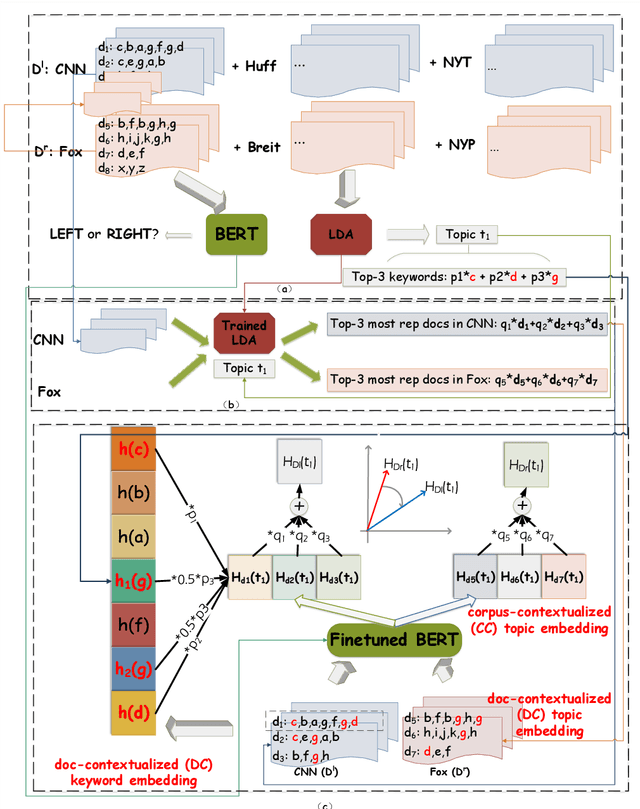

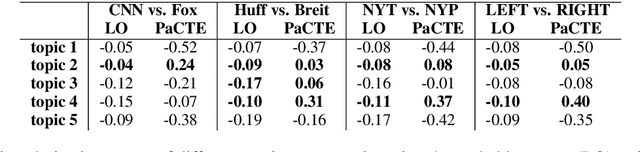
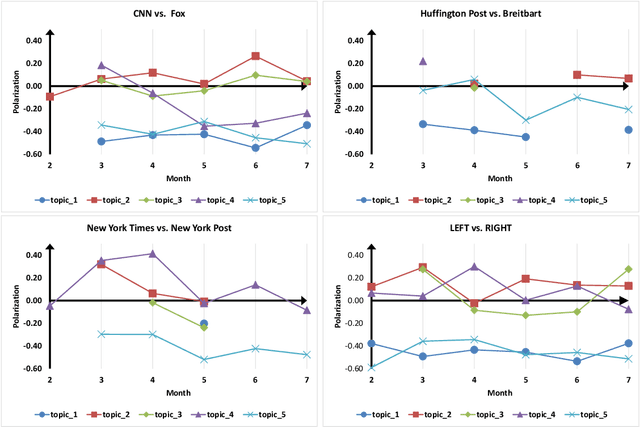
Growing polarization of the news media has been blamed for fanning disagreement, controversy and even violence. Early identification of polarized topics is thus an urgent matter that can help mitigate conflict. However, accurate measurement of polarization is still an open research challenge. To address this gap, we propose Partisanship-aware Contextualized Topic Embeddings (PaCTE), a method to automatically detect polarized topics from partisan news sources. Specifically, we represent the ideology of a news source on a topic by corpus-contextualized topic embedding utilizing a language model that has been finetuned on recognizing partisanship of the news articles, and measure the polarization between sources using cosine similarity. We apply our method to a corpus of news about COVID-19 pandemic. Extensive experiments on different news sources and topics demonstrate the effectiveness of our method to precisely capture the topical polarization and alignment between different news sources. To help clarify and validate results, we explain the polarization using the Moral Foundation Theory.
Individualized Context-Aware Tensor Factorization for Online Games Predictions
Feb 22, 2021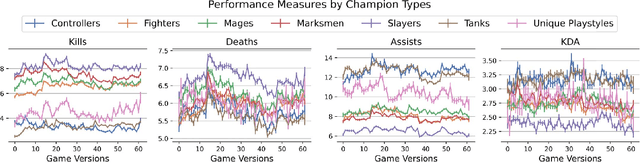
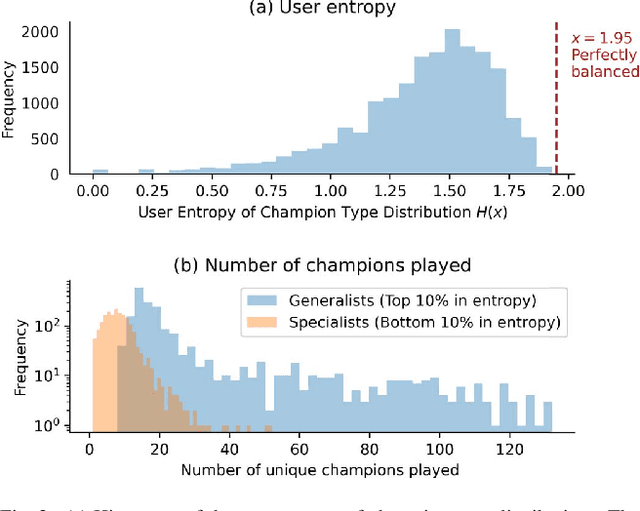
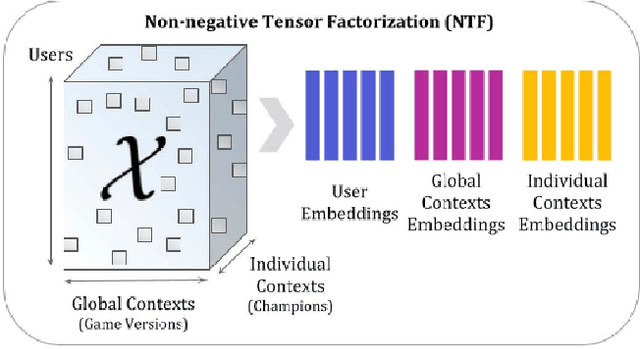
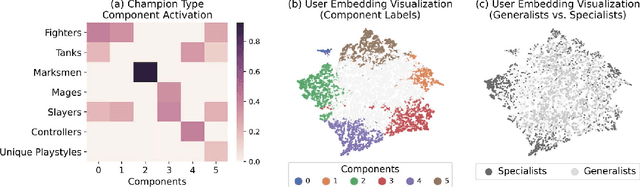
Individual behavior and decisions are substantially influenced by their contexts, such as location, environment, and time. Changes along these dimensions can be readily observed in Multiplayer Online Battle Arena games (MOBA), where players face different in-game settings for each match and are subject to frequent game patches. Existing methods utilizing contextual information generalize the effect of a context over the entire population, but contextual information tailored to each individual can be more effective. To achieve this, we present the Neural Individualized Context-aware Embeddings (NICE) model for predicting user performance and game outcomes. Our proposed method identifies individual behavioral differences in different contexts by learning latent representations of users and contexts through non-negative tensor factorization. Using a dataset from the MOBA game League of Legends, we demonstrate that our model substantially improves the prediction of winning outcome, individual user performance, and user engagement.
Inherent Trade-offs in the Fair Allocation of Treatments
Oct 30, 2020
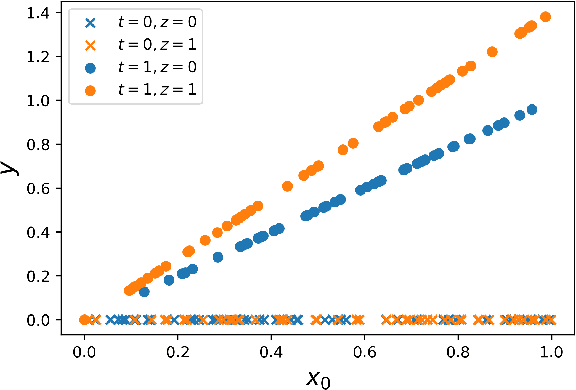
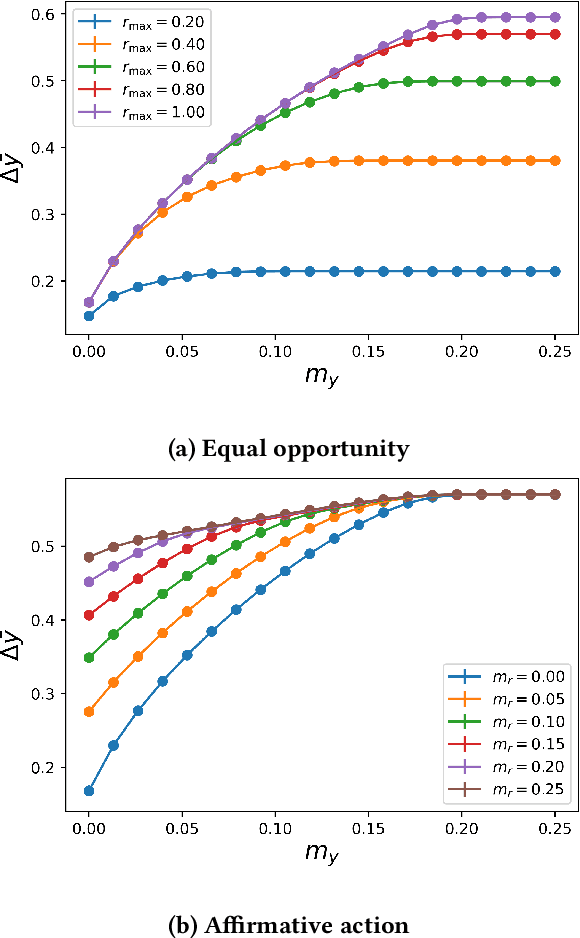
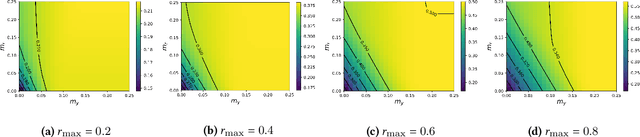
Explicit and implicit bias clouds human judgement, leading to discriminatory treatment of minority groups. A fundamental goal of algorithmic fairness is to avoid the pitfalls in human judgement by learning policies that improve the overall outcomes while providing fair treatment to protected classes. In this paper, we propose a causal framework that learns optimal intervention policies from data subject to fairness constraints. We define two measures of treatment bias and infer best treatment assignment that minimizes the bias while optimizing overall outcome. We demonstrate that there is a dilemma of balancing fairness and overall benefit; however, allowing preferential treatment to protected classes in certain circumstances (affirmative action) can dramatically improve the overall benefit while also preserving fairness. We apply our framework to data containing student outcomes on standardized tests and show how it can be used to design real-world policies that fairly improve student test scores. Our framework provides a principled way to learn fair treatment policies in real-world settings.
Challenges in Forecasting Malicious Events from Incomplete Data
Apr 06, 2020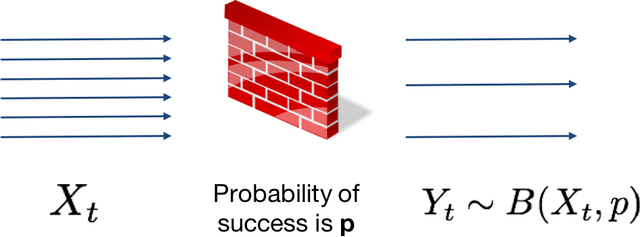
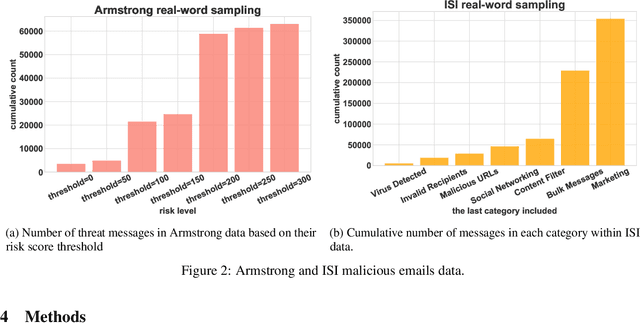
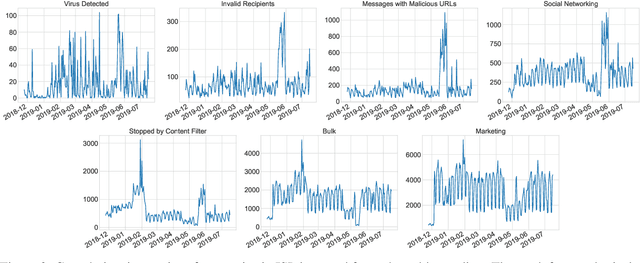
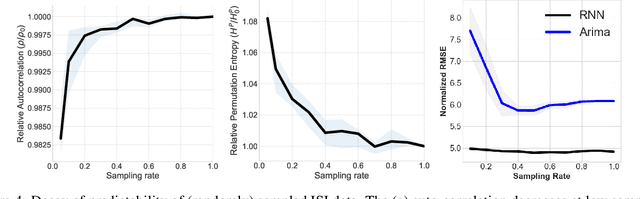
The ability to accurately predict cyber-attacks would enable organizations to mitigate their growing threat and avert the financial losses and disruptions they cause. But how predictable are cyber-attacks? Researchers have attempted to combine external data -- ranging from vulnerability disclosures to discussions on Twitter and the darkweb -- with machine learning algorithms to learn indicators of impending cyber-attacks. However, successful cyber-attacks represent a tiny fraction of all attempted attacks: the vast majority are stopped, or filtered by the security appliances deployed at the target. As we show in this paper, the process of filtering reduces the predictability of cyber-attacks. The small number of attacks that do penetrate the target's defenses follow a different generative process compared to the whole data which is much harder to learn for predictive models. This could be caused by the fact that the resulting time series also depends on the filtering process in addition to all the different factors that the original time series depended on. We empirically quantify the loss of predictability due to filtering using real-world data from two organizations. Our work identifies the limits to forecasting cyber-attacks from highly filtered data.
Learning Behavioral Representations from Wearable Sensors
Nov 16, 2019
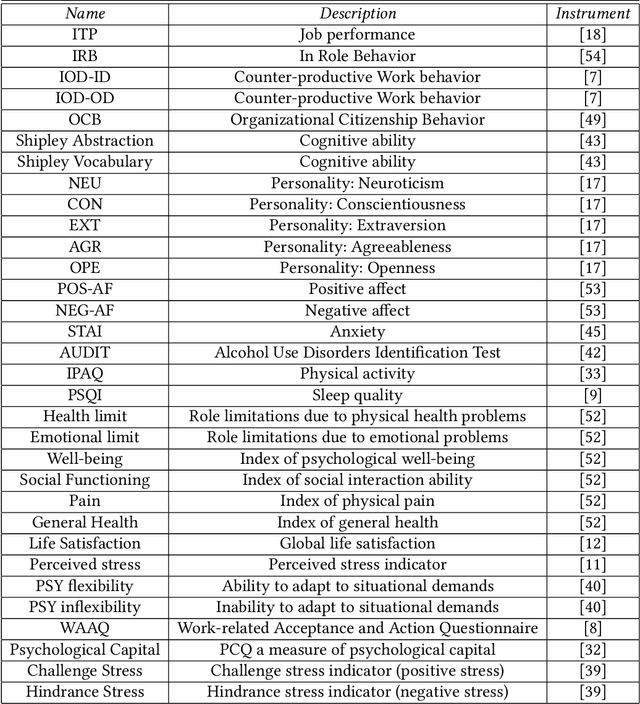
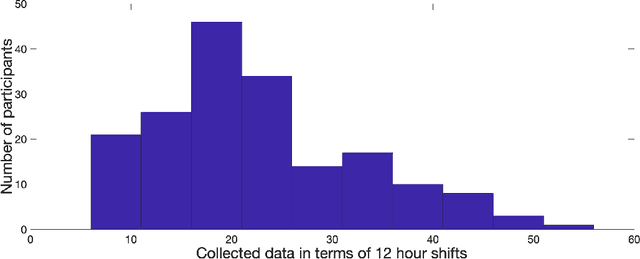
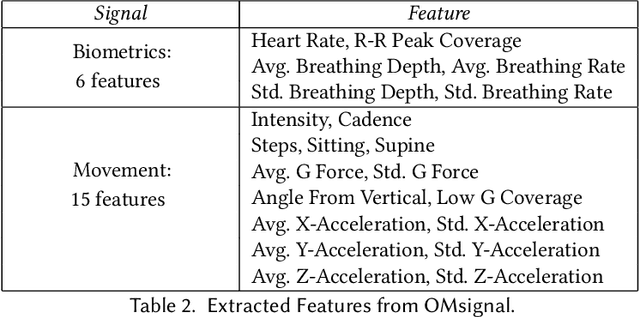
The ubiquity of mobile devices and wearable sensors offers unprecedented opportunities for continuous collection of multimodal physiological data. Such data enables temporal characterization of an individual's behaviors, which can provide unique insights into her physical and psychological health. Understanding the relation between different behaviors/activities and personality traits such as stress or work performance can help build strategies to improve the work environment. Especially in workplaces like hospitals where many employees are overworked, having such policies improves the quality of patient care by prioritizing mental and physical health of their caregivers. One challenge in analyzing physiological data is extracting the underlying behavioral states from the temporal sensor signals and interpreting them. Here, we use a non-parametric Bayesian approach, to model multivariate sensor data from multiple people and discover dynamic behaviors they share. We apply this method to data collected from sensors worn by a population of workers in a large urban hospital, capturing their physiological signals, such as breathing and heart rate, and activity patterns. We show that the learned states capture behavioral differences within the population that can help cluster participants into meaningful groups and better predict their cognitive and affective states. This method offers a practical way to learn compact behavioral representations from dynamic multivariate sensor signals and provide insights into the data.