 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Extraction from Job Postings using Weak Supervision
Sep 16, 2022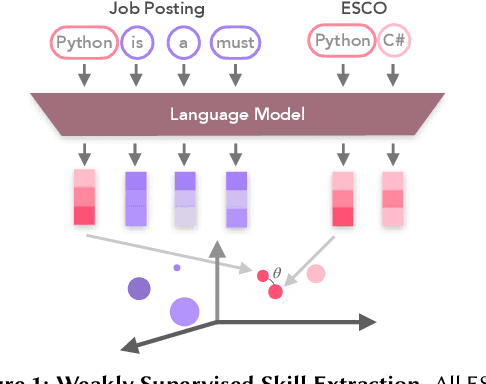
Aggregated data obtained from job postings provide powerful insights into labor market demands, and emerging skills, and aid job matching. However, most extraction approaches are supervised and thus need costly and time-consuming annotation. To overcome this, we propose Skill Extraction with Weak Supervision. We leverage the European Skills, Competences, Qualifications and Occupations taxonomy to find similar skills in job ads via latent representations. The method shows a strong positive signal, outperforming baselines based on token-level and syntactic patterns.
Kompetencer: Fine-grained Skill Classification in Danish Job Postings via Distant Supervision and Transfer Learning
May 03, 2022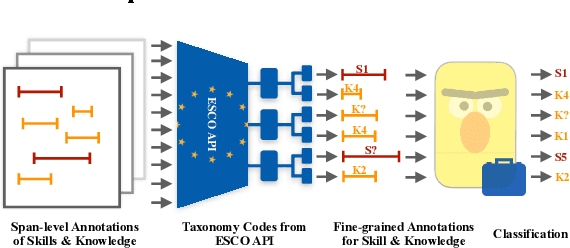
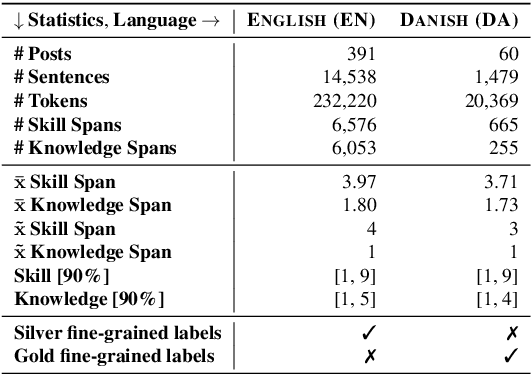
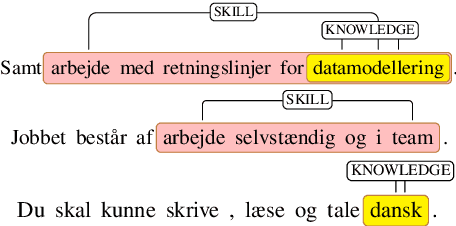
Skill Classification (SC) is the task of classifying job competences from job postings. This work is the first in SC applied to Danish job vacancy data. We release the first Danish job posting dataset: Kompetencer (en: competences), annotated for nested spans of competences. To improve upon coarse-grained annotations, we make use of The European Skills, Competences, Qualifications and Occupations (ESCO; le Vrang et al., 2014) taxonomy API to obtain fine-grained labels via distant supervision. We study two setups: The zero-shot and few-shot classification setting. We fine-tune English-based models and RemBERT (Chung et al., 2020) and compare them to in-language Danish models. Our results show RemBERT significantly outperforms all other models in both the zero-shot and the few-shot setting.
SkillSpan: Hard and Soft Skill Extraction from English Job Postings
Apr 27, 2022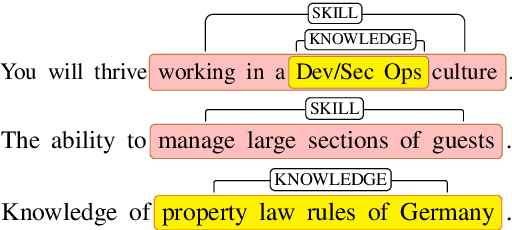
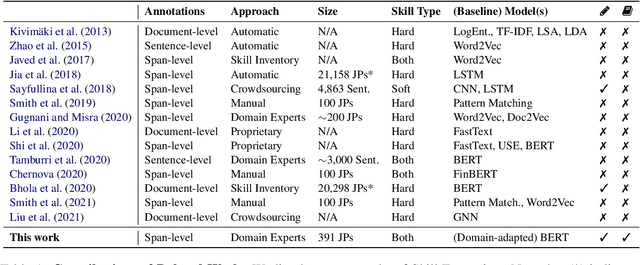
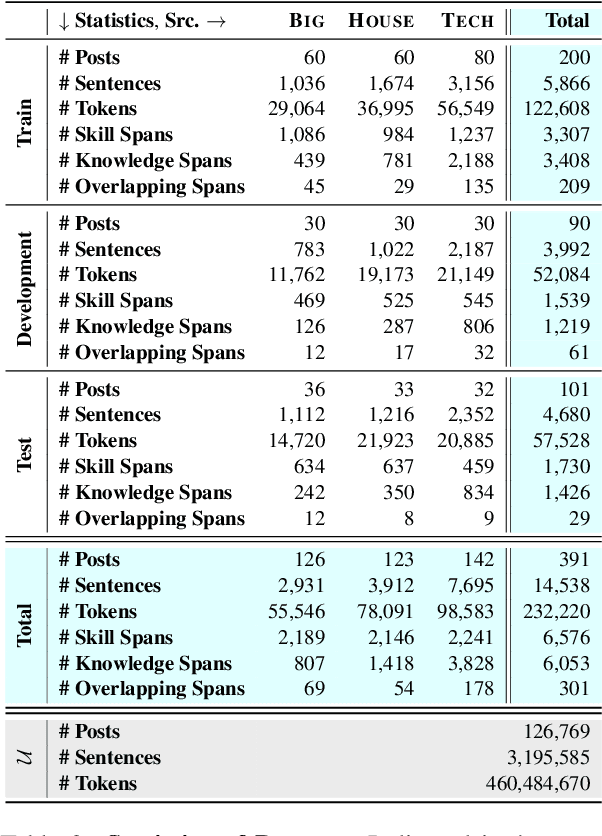
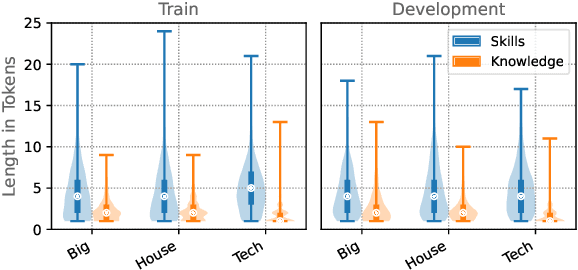
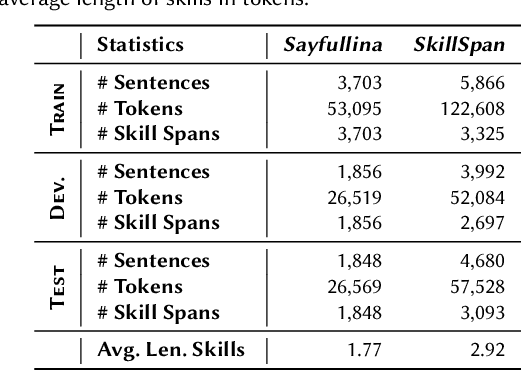
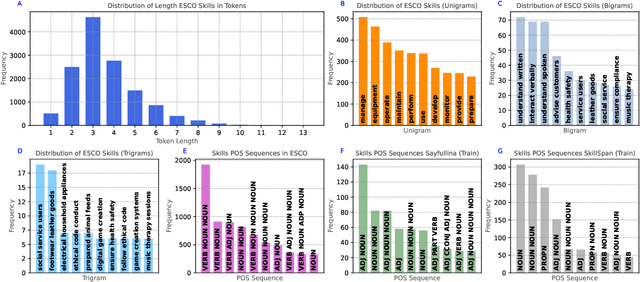
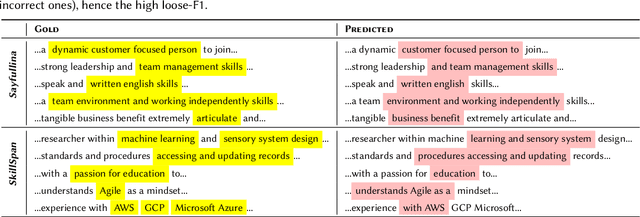
Skill Extraction (SE) is an important and widely-studied task useful to gain insights into labor market dynamics. However, there is a lacuna of datasets and annotation guidelines; available datasets are few and contain crowd-sourced labels on the span-level or labels from a predefined skill inventory. To address this gap, we introduce SKILLSPAN, a novel SE dataset consisting of 14.5K sentences and over 12.5K annotated spans. We release its respective guidelines created over three different sources annotated for hard and soft skills by domain experts. We introduce a BERT baseline (Devlin et al., 2019). To improve upon this baseline, we experiment with language models that are optimized for long spans (Joshi et al., 2020; Beltagy et al., 2020), continuous pre-training on the job posting domain (Han and Eisenstein, 2019; Gururangan et al., 2020), and multi-task learning (Caruana, 1997). Our results show that the domain-adapted models significantly outperform their non-adapted counterparts, and single-task outperforms multi-task learning.
DaN+: Danish Nested Named Entities and Lexical Normalization
May 24, 2021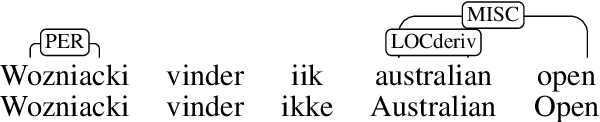
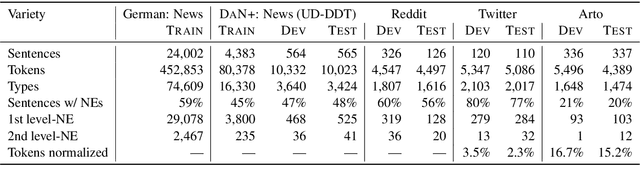
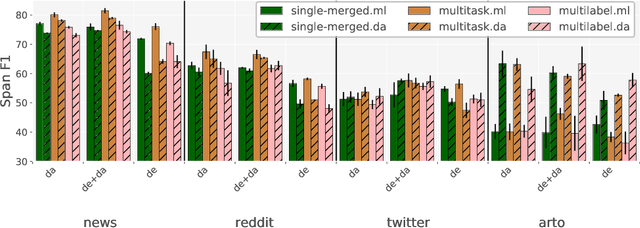
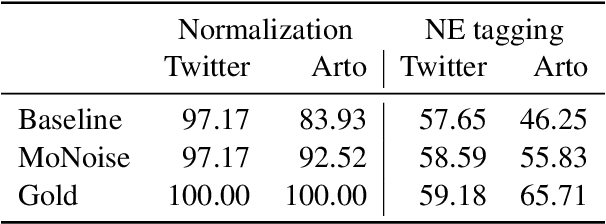
This paper introduces DaN+, a new multi-domain corpus and annotation guidelines for Danish nested named entities (NEs) and lexical normalization to support research on cross-lingual cross-domain learning for a less-resourced language. We empirically assess three strategies to model the two-layer Named Entity Recognition (NER) task. We compare transfer capabilities from German versus in-language annotation from scratch. We examine language-specific versus multilingual BERT, and study the effect of lexical normalization on NER. Our results show that 1) the most robust strategy is multi-task learning which is rivaled by multi-label decoding, 2) BERT-based NER models are sensitive to domain shifts, and 3) in-language BERT and lexical normalization are the most beneficial on the least canonical data. Our results also show that an out-of-domain setup remains challenging, while performance on news plateaus quickly. This highlights the importance of cross-domain evaluation of cross-lingual transfer.
De-identification of Privacy-related Entities in Job Postings
May 24, 2021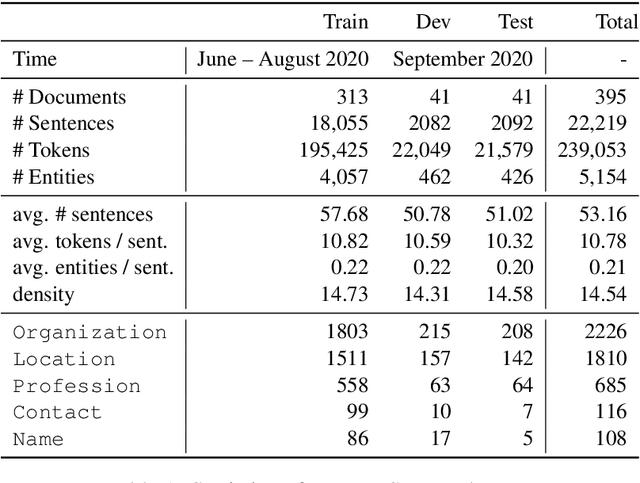

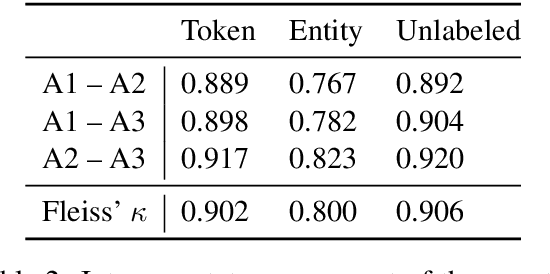
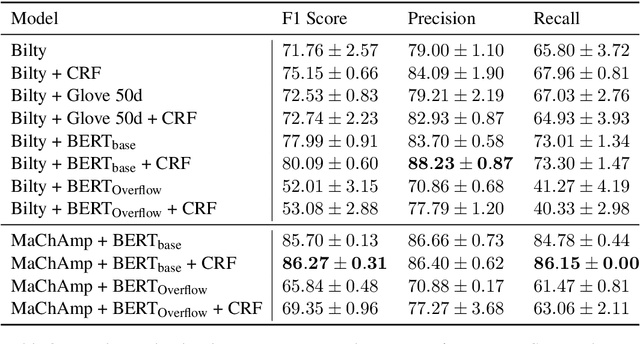
De-identification is the task of detecting privacy-related entities in text, such as person names, emails and contact data. It has been well-studied within the medical domain. The need for de-identification technology is increasing, as privacy-preserving data handling is in high demand in many domains. In this paper, we focus on job postings. We present JobStack, a new corpus for de-identification of personal data in job vacancies on Stackoverflow. We introduce baselines, comparing Long-Short Term Memory (LSTM) and Transformer models. To improve upon these baselines, we experiment with contextualized embeddings and distantly related auxiliary data via multi-task learning. Our results show that auxiliary data improves de-identification performance. Surprisingly, vanilla BERT turned out to be more effective than a BERT model trained on other portions of Stackoverflow.