 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Fair Selection in the Presence of Implicit Variance
Jun 24, 2020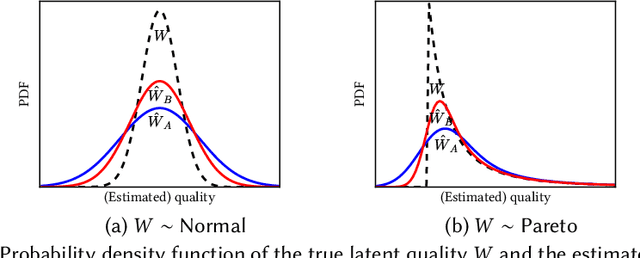

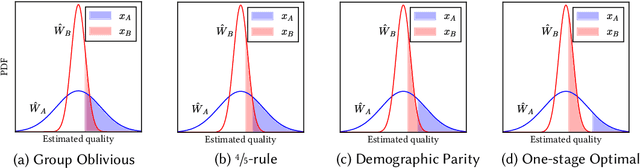
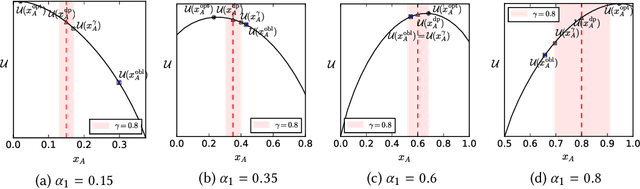
Quota-based fairness mechanisms like the so-called Rooney rule or four-fifths rule are used in selection problems such as hiring or college admission to reduce inequalities based on sensitive demographic attributes. These mechanisms are often viewed as introducing a trade-off between selection fairness and utility. In recent work, however, Kleinberg and Raghavan showed that, in the presence of implicit bias in estimating candidates' quality, the Rooney rule can increase the utility of the selection process. We argue that even in the absence of implicit bias, the estimates of candidates' quality from different groups may differ in another fundamental way, namely, in their variance. We term this phenomenon implicit variance and we ask: can fairness mechanisms be beneficial to the utility of a selection process in the presence of implicit variance (even in the absence of implicit bias)? To answer this question, we propose a simple model in which candidates have a true latent quality that is drawn from a group-independent normal distribution. To make the selection, a decision maker receives an unbiased estimate of the quality of each candidate, with normal noise, but whose variance depends on the candidate's group. We then compare the utility obtained by imposing a fairness mechanism that we term $\gamma$-rule (it includes demographic parity and the four-fifths rule as special cases), to that of a group-oblivious selection algorithm that picks the candidates with the highest estimated quality independently of their group. Our main result shows that the demographic parity mechanism always increases the selection utility, while any $\gamma$-rule weakly increases it. We extend our model to a two-stage selection process where the true quality is observed at the second stage. We discuss multiple extensions of our results, in particular to different distributions of the true latent quality.
Fair Inputs and Fair Outputs: The Incompatibility of Fairness in Privacy and Accuracy
May 24, 2020

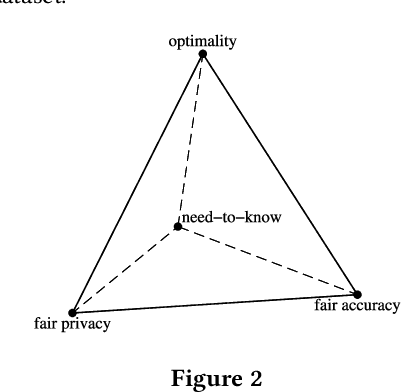
Fairness concerns about algorithmic decision-making systems have been mainly focused on the outputs (e.g., the accuracy of a classifier across individuals or groups). However, one may additionally be concerned with fairness in the inputs. In this paper, we propose and formulate two properties regarding the inputs of (features used by) a classifier. In particular, we claim that fair privacy (whether individuals are all asked to reveal the same information) and need-to-know (whether users are only asked for the minimal information required for the task at hand) are desirable properties of a decision system. We explore the interaction between these properties and fairness in the outputs (fair prediction accuracy). We show that for an optimal classifier these three properties are in general incompatible, and we explain what common properties of data make them incompatible. Finally we provide an algorithm to verify if the trade-off between the three properties exists in a given dataset, and use the algorithm to show that this trade-off is common in real data.
FairRec: Two-Sided Fairness for Personalized Recommendations in Two-Sided Platforms
Feb 25, 2020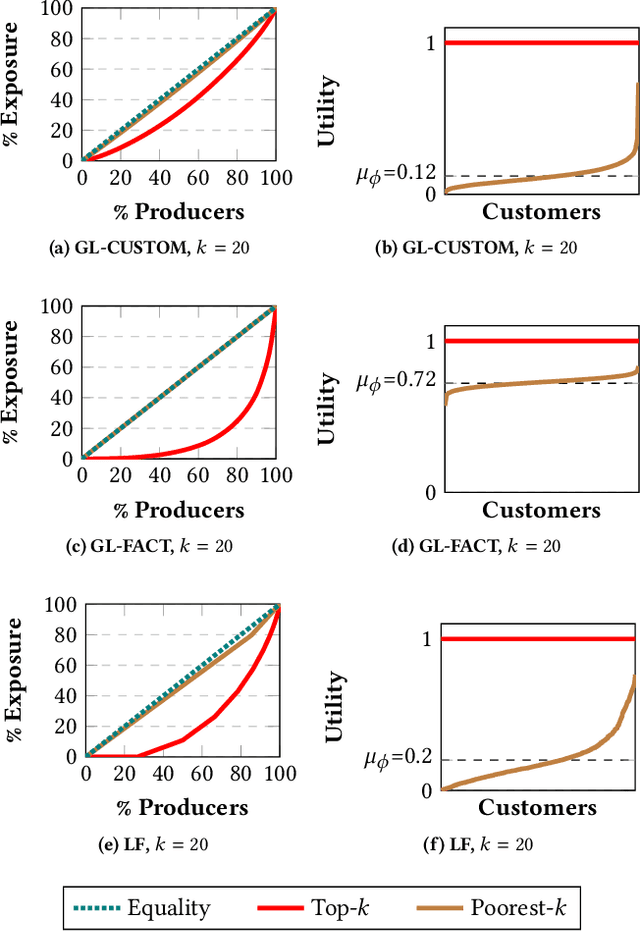
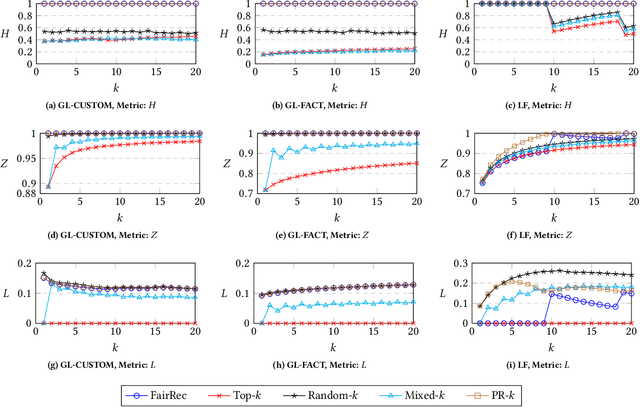
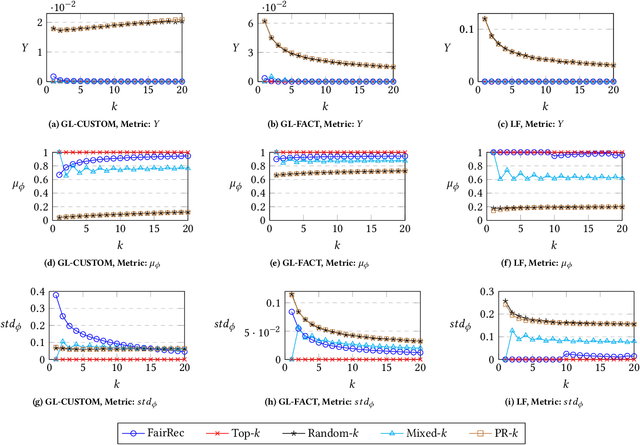
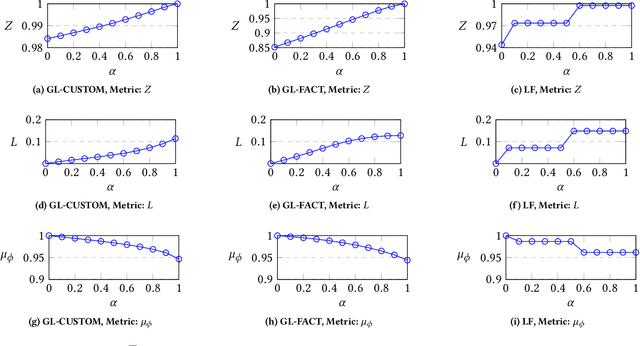
We investigate the problem of fair recommendation in the context of two-sided online platforms, comprising customers on one side and producers on the other. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reveals that such customer-centric design may lead to unfair distribution of exposure among the producers, which may adversely impact their well-being. On the other hand, a producer-centric design might become unfair to the customers. Thus, we consider fairness issues that span both customers and producers. Our approach involves a novel mapping of the fair recommendation problem to a constrained version of the problem of fairly allocating indivisible goods. Our proposed FairRec algorithm guarantees at least Maximin Share (MMS) of exposure for most of the producers and Envy-Free up to One item (EF1) fairness for every customer. Extensive evaluations over multiple real-world datasets show the effectiveness of FairRec in ensuring two-sided fairness while incurring a marginal loss in the overall recommendation quality.
An Empirical Study on Learning Fairness Metrics for COMPAS Data with Human Supervision
Oct 31, 2019
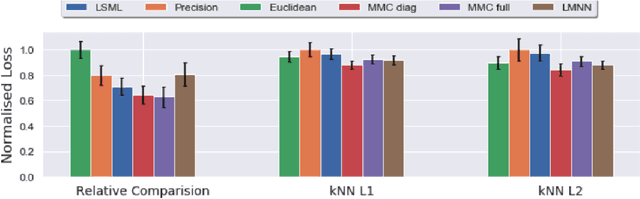
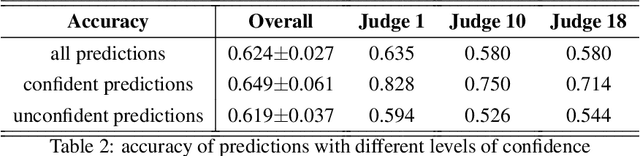
The notion of individual fairness requires that similar people receive similar treatment. However, this is hard to achieve in practice since it is difficult to specify the appropriate similarity metric. In this work, we attempt to learn such similarity metric from human annotated data. We gather a new dataset of human judgments on a criminal recidivism prediction (COMPAS) task. By assuming the human supervision obeys the principle of individual fairness, we leverage prior work on metric learning, evaluate the performance of several metric learning methods on our dataset, and show that the learned metrics outperform the Euclidean and Precision metric under various criteria. We do not provide a way to directly learn a similarity metric satisfying the individual fairness, but to provide an empirical study on how to derive the similarity metric from human supervisors, then future work can use this as a tool to understand human supervision.
DADI: Dynamic Discovery of Fair Information with Adversarial Reinforcement Learning
Oct 30, 2019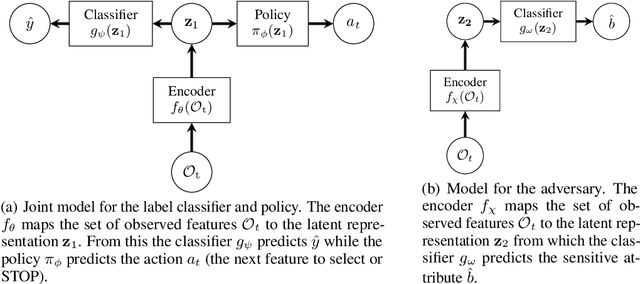
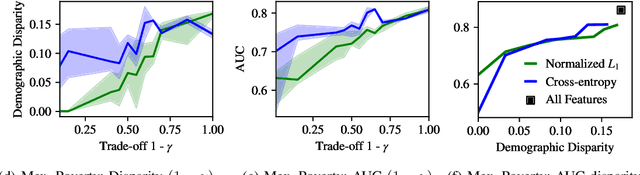
We introduce a framework for dynamic adversarial discovery of information (DADI), motivated by a scenario where information (a feature set) is used by third parties with unknown objectives. We train a reinforcement learning agent to sequentially acquire a subset of the information while balancing accuracy and fairness of predictors downstream. Based on the set of already acquired features, the agent decides dynamically to either collect more information from the set of available features or to stop and predict using the information that is currently available. Building on previous work exploring adversarial representation learning, we attain group fairness (demographic parity) by rewarding the agent with the adversary's loss, computed over the final feature set. Importantly, however, the framework provides a more general starting point for fair or private dynamic information discovery. Finally, we demonstrate empirically, using two real-world datasets, that we can trade-off fairness and predictive performance
Operationalizing Individual Fairness with Pairwise Fair Representations
Jul 02, 2019
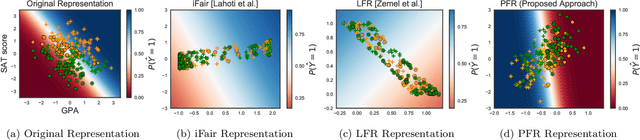
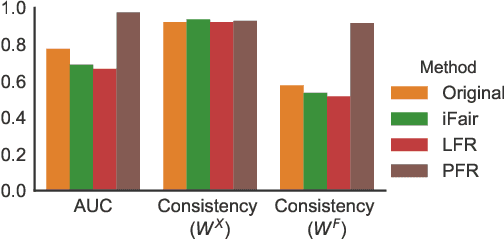
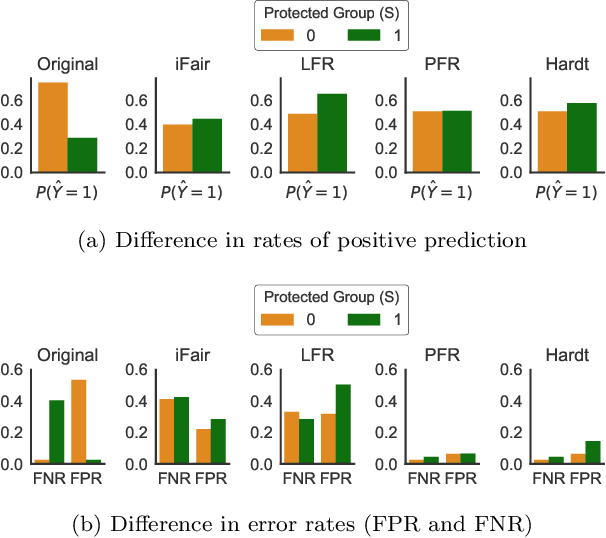
We revisit the notion of individual fairness proposed by Dwork et al. A central challenge in operationalizing their approach is the difficulty in eliciting a human specification of a similarity metric. In this paper, we propose an operationalization of individual fairness that does not rely on a human specification of a distance metric. Instead, we propose novel approaches to elicit and leverage side-information on equally deserving individuals to counter subordination between social groups. We model this knowledge as a fairness graph, and learn a unified Pairwise Fair Representation(PFR) of the data that captures both data-driven similarity between individuals and the pairwise side-information in fairness graph. We elicit fairness judgments from a variety of sources, including humans judgments for two real-world datasets on recidivism prediction (COMPAS) and violent neighborhood prediction (Crime & Communities). Our experiments show that the PFR model for operationalizing individual fairness is practically viable.
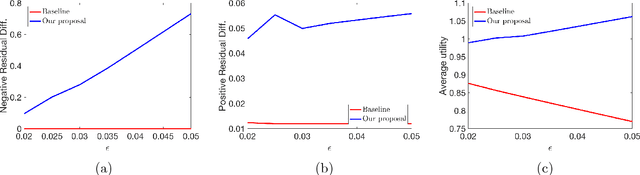
On the Long-term Impact of Algorithmic Decision Policies: Effort Unfairness and Feature Segregation through Social Learning
Mar 04, 2019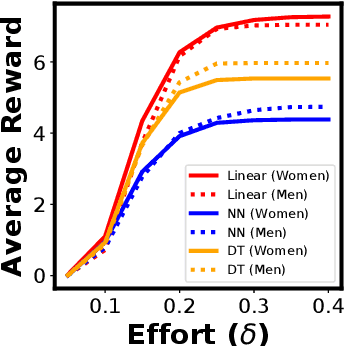
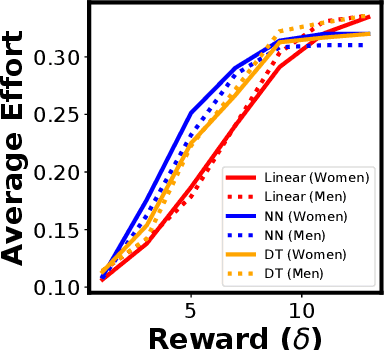
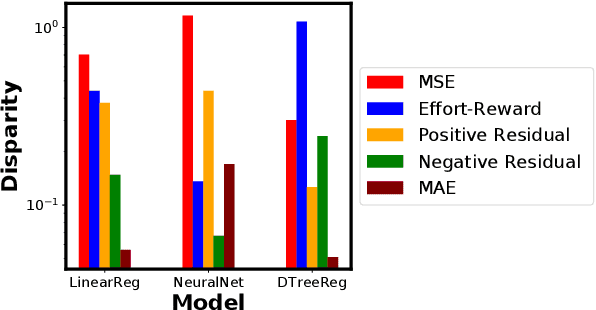
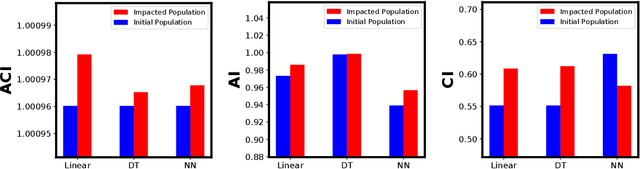
Most existing notions of algorithmic fairness are one-shot: they ensure some form of allocative equality at the time of decision making, but do not account for the adverse impact of the algorithmic decisions today on the long-term welfare and prosperity of certain segments of the population. We take a broader perspective on algorithmic fairness. We propose an effort-based measure of fairness and present a data-driven framework for characterizing the long-term impact of algorithmic policies on reshaping the underlying population. Motivated by the psychological literature on social learning and the economic literature on equality of opportunity, we propose a micro-scale model of how individuals respond to decision making algorithms. We employ existing measures of segregation from sociology and economics to quantify the resulting macro-scale population-level change. Importantly, we observe that different models may shift the group-conditional distribution of qualifications in different directions. Our findings raise a number of important questions regarding the formalization of fairness for decision-making models.
Fighting Fire with Fire: Using Antidote Data to Improve Polarization and Fairness of Recommender Systems
Jan 14, 2019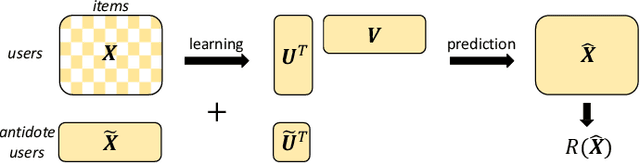
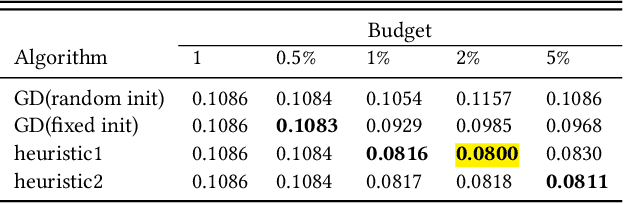
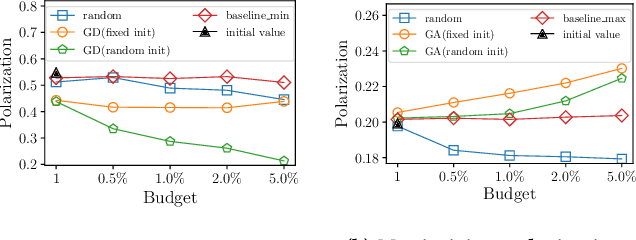
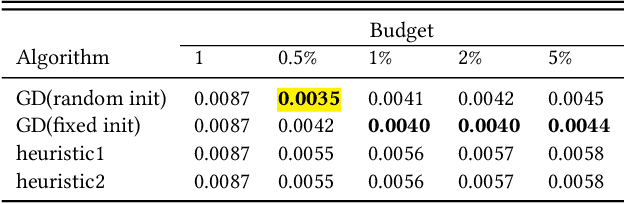
The increasing role of recommender systems in many aspects of society makes it essential to consider how such systems may impact social good. Various modifications to recommendation algorithms have been proposed to improve their performance for specific socially relevant measures. However, previous proposals are often not easily adapted to different measures, and they generally require the ability to modify either existing system inputs, the system's algorithm, or the system's outputs. As an alternative, in this paper we introduce the idea of improving the social desirability of recommender system outputs by adding more data to the input, an approach we view as as providing `antidote' data to the system. We formalize the antidote data problem, and develop optimization-based solutions. We take as our model system the matrix factorization approach to recommendation, and we propose a set of measures to capture the polarization or fairness of recommendations. We then show how to generate antidote data for each measure, pointing out a number of computational efficiencies, and discuss the impact on overall system accuracy. Our experiments show that a modest budget for antidote data can lead to significant improvements in the polarization or fairness of recommendations.
Fairness Behind a Veil of Ignorance: A Welfare Analysis for Automated Decision Making
Oct 29, 2018
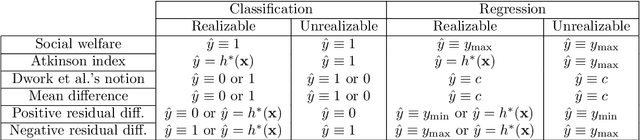
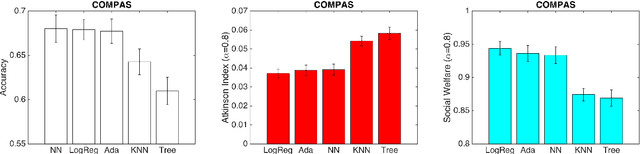
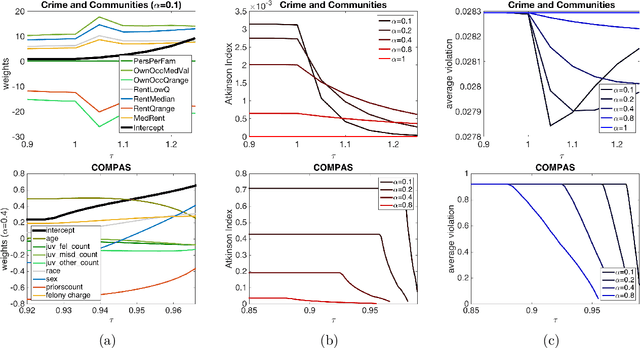
We draw attention to an important, yet largely overlooked aspect of evaluating fairness for automated decision making systems---namely risk and welfare considerations. Our proposed family of measures corresponds to the long-established formulations of cardinal social welfare in economics, and is justified by the Rawlsian conception of fairness behind a veil of ignorance. The convex formulation of our welfare-based measures of fairness allows us to integrate them as a constraint into any convex loss minimization pipeline. Our empirical analysis reveals interesting trade-offs between our proposal and (a) prediction accuracy, (b) group discrimination, and (c) Dwork et al.'s notion of individual fairness. Furthermore and perhaps most importantly, our work provides both heuristic justification and empirical evidence suggesting that a lower-bound on our measures often leads to bounded inequality in algorithmic outcomes; hence presenting the first computationally feasible mechanism for bounding individual-level inequality.
A Moral Framework for Understanding of Fair ML through Economic Models of Equality of Opportunity
Sep 10, 2018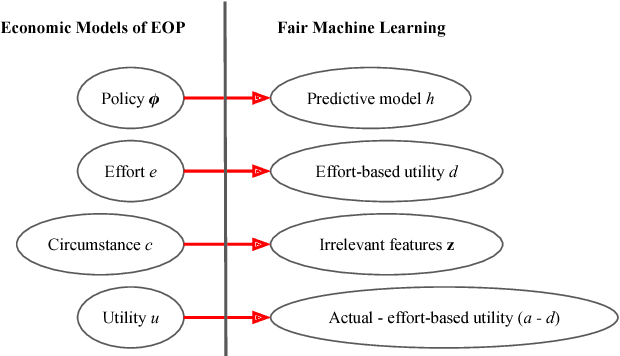

Equality of opportunity (EOP) is an extensively studied conception of fairness in political philosophy. In this work, we map recently proposed notions of algorithmic fairness to economic models of EOP. We formally show that through our proposed mapping, many existing definition of algorithmic fairness, such as predictive value parity and equality of odds, can be interpreted as special cases of EOP. In this respect, our work serves as a unifying moral framework for understanding existing notions of algorithmic fairness. Most importantly, this framework allows us to explicitly spell out the moral assumptions underlying each notion of fairness, and also interpret recent fairness impossibility results in a new light. Last but not least and inspired by luck egalitarian models of EOP, we propose a new, more general family of measures for algorithmic fairness. We empirically show that employing a measure of algorithmic (un)fairness when its underlying moral assumptions are not satisfied, can have devastating consequences on the subjects' welfare.