 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability for Fault Detection System in Chemical Processes
Feb 18, 2026In this work, we apply and compare two state-of-the-art eXplainability Artificial Intelligence (XAI) methods, the Integrated Gradients (IG) and the SHapley Additive exPlanations (SHAP), that explain the fault diagnosis decisions of a highly accurate Long Short-Time Memory (LSTM) classifier. The classifier is trained to detect faults in a benchmark non-linear chemical process, the Tennessee Eastman Process (TEP). It is highlighted how XAI methods can help identify the subsystem of the process where the fault occurred. Using our knowledge of the process, we note that in most cases the same features are indicated as the most important for the decision, while insome cases the SHAP method seems to be more informative and closer to the root cause of the fault. Finally, since the used XAI methods are model-agnostic, the proposed approach is not limited to the specific process and can also be used in similar problems.
Learning local discrete features in explainable-by-design convolutional neural networks
Oct 31, 2024



Our proposed framework attempts to break the trade-off between performance and explainability by introducing an explainable-by-design convolutional neural network (CNN) based on the lateral inhibition mechanism. The ExplaiNet model consists of the predictor, that is a high-accuracy CNN with residual or dense skip connections, and the explainer probabilistic graph that expresses the spatial interactions of the network neurons. The value on each graph node is a local discrete feature (LDF) vector, a patch descriptor that represents the indices of antagonistic neurons ordered by the strength of their activations, which are learned with gradient descent. Using LDFs as sequences we can increase the conciseness of explanations by repurposing EXTREME, an EM-based sequence motif discovery method that is typically used in molecular biology. Having a discrete feature motif matrix for each one of intermediate image representations, instead of a continuous activation tensor, allows us to leverage the inherent explainability of Bayesian networks. By collecting observations and directly calculating probabilities, we can explain causal relationships between motifs of adjacent levels and attribute the model's output to global motifs. Moreover, experiments on various tiny image benchmark datasets confirm that our predictor ensures the same level of performance as the baseline architecture for a given count of parameters and/or layers. Our novel method shows promise to exceed this performance while providing an additional stream of explanations. In the solved MNIST classification task, it reaches a comparable to the state-of-the-art performance for single models, using standard training setup and 0.75 million parameters.
Enhanced Deep Learning Methodologies and MRI Selection Techniques for Dementia Diagnosis in the Elderly Population
Jul 25, 2024



Dementia, a debilitating neurological condition affecting millions worldwide, presents significant diagnostic challenges. In this work, we introduce a novel methodology for the classification of demented and non-demented elderly patients using 3D brain Magnetic Resonance Imaging (MRI) scans. Our approach features a unique technique for selectively processing MRI slices, focusing on the most relevant brain regions and excluding less informative sections. This methodology is complemented by a confidence-based classification committee composed of three custom deep learning models: Dem3D ResNet, Dem3D CNN, and Dem3D EfficientNet. These models work synergistically to enhance decision-making accuracy, leveraging their collective strengths. Tested on the Open Access Series of Imaging Studies(OASIS) dataset, our method achieved an impressive accuracy of 94.12%, surpassing existing methodologies. Furthermore, validation on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset confirmed the robustness and generalizability of our approach. The use of explainable AI (XAI) techniques and comprehensive ablation studies further substantiate the effectiveness of our techniques, providing insights into the decision-making process and the importance of our methodology. This research offers a significant advancement in dementia diagnosis, providing a highly accurate and efficient tool for clinical applications.
Automated Single-Label Patent Classification using Ensemble Classifiers
Mar 03, 2022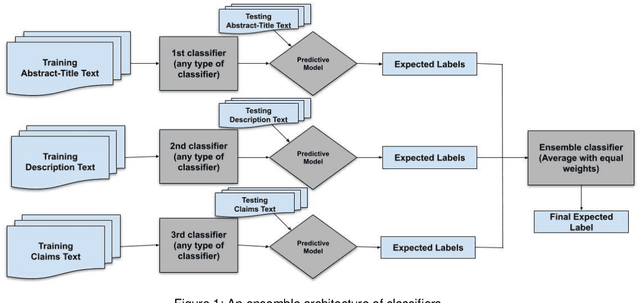

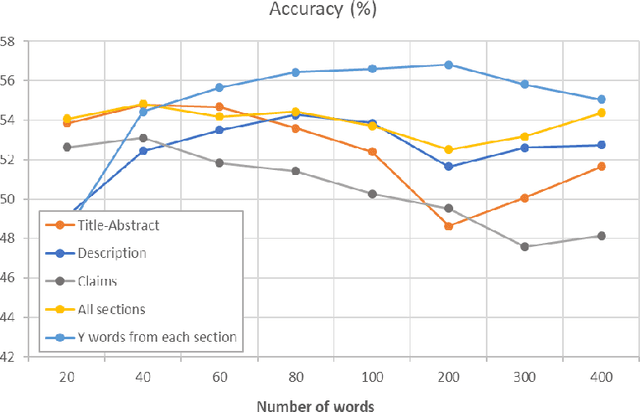
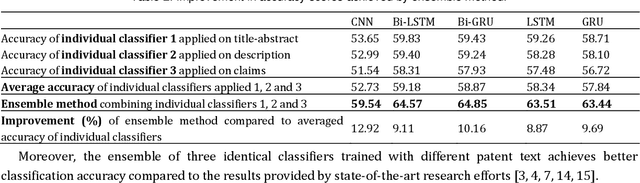
Many thousands of patent applications arrive at patent offices around the world every day. One important subtask when a patent application is submitted is to assign one or more classification codes from the complex and hierarchical patent classification schemes that will enable routing of the patent application to a patent examiner who is knowledgeable about the specific technical field. This task is typically undertaken by patent professionals, however due to the large number of applications and the potential complexity of an invention, they are usually overwhelmed. Therefore, there is a need for this code assignment manual task to be supported or even fully automated by classification systems that will classify patent applications, hopefully with an accuracy close to patent professionals. Like in many other text analysis problems, in the last years, this intellectually demanding task has been studied using word embeddings and deep learning techniques. In this paper we shortly review these research efforts and experiment with similar deep learning techniques using different feature representations on automatic patent classification in the level of sub-classes. On top of that, we present an innovative method of ensemble classifiers trained with different parts of the patent document. To the best of our knowledge, this is the first time that an ensemble method was proposed for the patent classification problem. Our first results are quite promising showing that an ensemble architecture of classifiers significantly outperforms current state-of-the-art techniques using the same classifiers as standalone solutions.
A Graph-based Method for Session-based Recommendations
Jun 22, 2021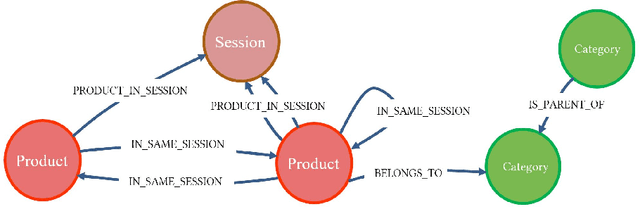

We present a graph-based approach for the data management tasks and the efficient operation of a system for session-based next-item recommendations. The proposed method can collect data continuously and incrementally from an ecommerce web site, thus seemingly prepare the necessary data infrastructure for the recommendation algorithm to operate without any excessive training phase. Our work aims at developing a recommender method that represents a balance between data processing and management efficiency requirements and the effectiveness of the recommendations produced. We use the Neo4j graph database to implement a prototype of such a system. Furthermore, we use an industry dataset corresponding to a typical e-commerce session-based scenario, and we report on experiments using our graph-based approach and other state-of-the-art machine learning and deep learning methods.
Student Performance Prediction Using Dynamic Neural Models
Jun 01, 2021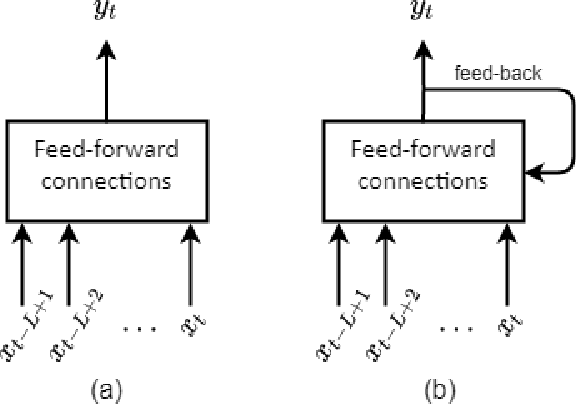
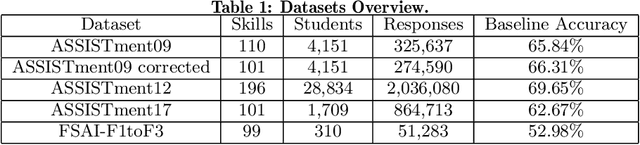
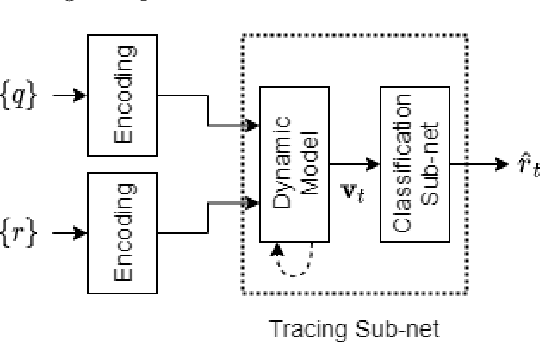
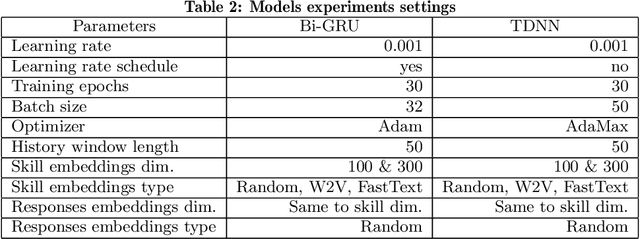
We address the problem of predicting the correctness of the student's response on the next exam question based on their previous interactions in the course of their learning and evaluation process. We model the student performance as a dynamic problem and compare the two major classes of dynamic neural architectures for its solution, namely the finite-memory Time Delay Neural Networks (TDNN) and the potentially infinite-memory Recurrent Neural Networks (RNN). Since the next response is a function of the knowledge state of the student and this, in turn, is a function of their previous responses and the skills associated with the previous questions, we propose a two-part network architecture. The first part employs a dynamic neural network (either TDNN or RNN) to trace the student knowledge state. The second part applies on top of the dynamic part and it is a multi-layer feed-forward network which completes the classification task of predicting the student response based on our estimate of the student knowledge state. Both input skills and previous responses are encoded using different embeddings. Regarding the skill embeddings we tried two different initialization schemes using (a) random vectors and (b) pretrained vectors matching the textual descriptions of the skills. Our experiments show that the performance of the RNN approach is better compared to the TDNN approach in all datasets that we have used. Also, we show that our RNN architecture outperforms the state-of-the-art models in four out of five datasets. It is worth noting that the TDNN approach also outperforms the state of the art models in four out of five datasets, although it is slightly worse than our proposed RNN approach. Finally, contrary to our expectations, we find that the initialization of skill embeddings using pretrained vectors offers practically no advantage over random initialization.
Sparse Antenna Array Design for MIMO Radar Using Softmax Selection
Feb 09, 2021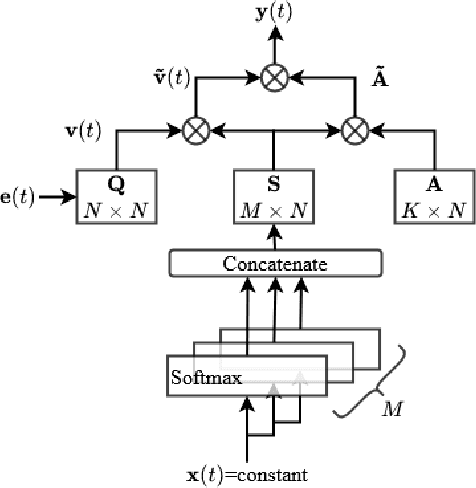
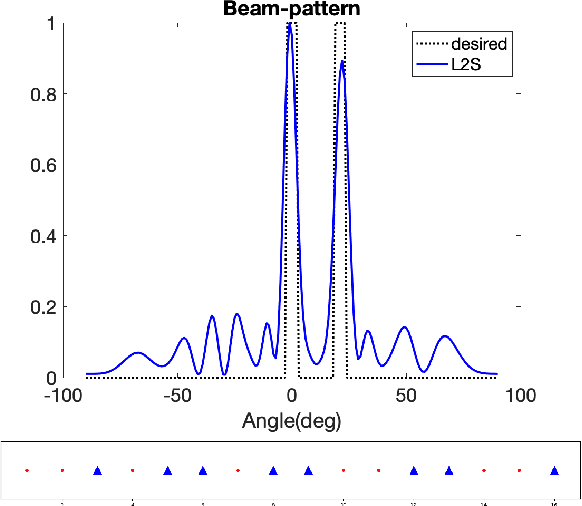
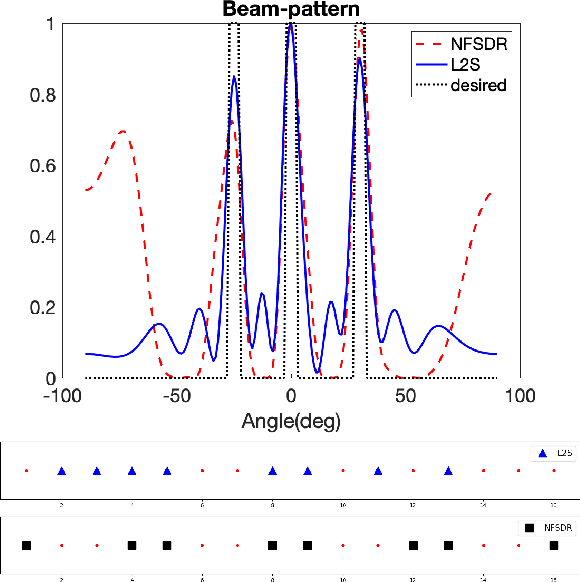
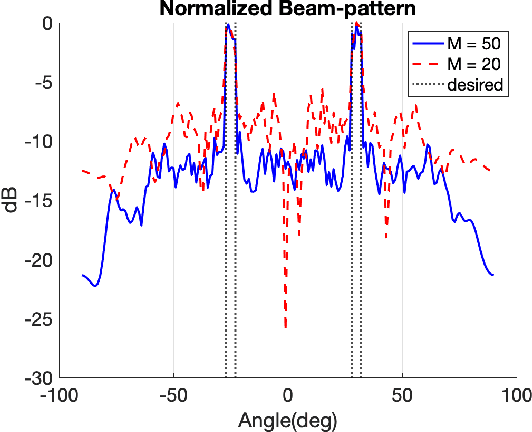
MIMO transmit arrays allow for flexible design of the transmit beampattern. However, the large number of elements required to achieve certain performance using uniform linear arrays (ULA) maybe be too costly. This motivated the need for thinned arrays by appropriately selecting a small number of elements so that the full array beampattern is preserved. In this paper, we propose Learn-to-Select (L2S), a novel machine learning model for selecting antennas from a dense ULA employing a combination of multiple Softmax layers constrained by an orthogonalization criterion. The proposed approach can be efficiently scaled for larger problems as it avoids the combinatorial explosion of the selection problem. It also offers a flexible array design framework as the selection problem can be easily formulated for any metric.
Learning to Select for MIMO Radar based on Hybrid Analog-Digital Beamforming
Jan 18, 2021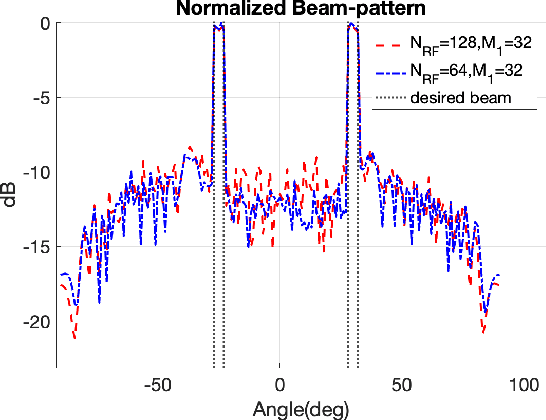
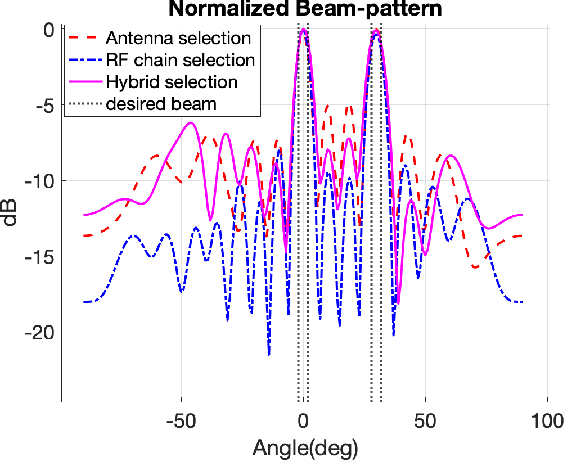
In this paper, we propose an energy-efficient radar beampattern design framework for a Millimeter Wave (mmWave) massive multi-input multi-output (mMIMO) system, equipped with a hybrid analog-digital (HAD) beamforming structure. Aiming to reduce the power consumption and hardware cost of the mMIMO system, we employ a machine learning approach to synthesize the probing beampattern based on a small number of RF chains and antennas. By leveraging a combination of softmax neural networks, the proposed solution is able to achieve a desirable beampattern with high accuracy.
Machine Learning Sentiment Prediction based on Hybrid Document Representation
Nov 29, 2015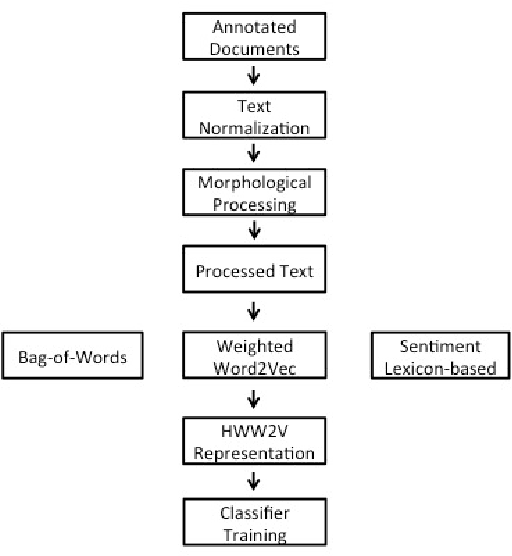
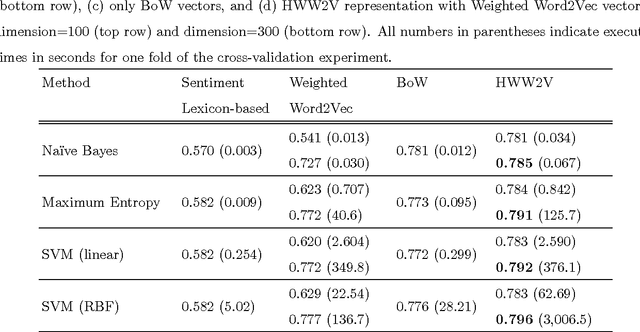
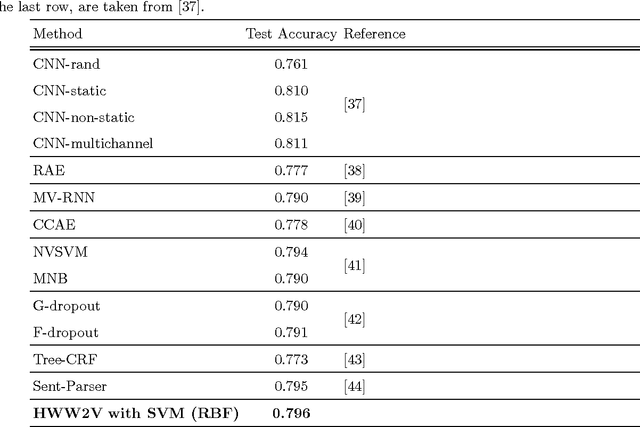
Automated sentiment analysis and opinion mining is a complex process concerning the extraction of useful subjective information from text. The explosion of user generated content on the Web, especially the fact that millions of users, on a daily basis, express their opinions on products and services to blogs, wikis, social networks, message boards, etc., render the reliable, automated export of sentiments and opinions from unstructured text crucial for several commercial applications. In this paper, we present a novel hybrid vectorization approach for textual resources that combines a weighted variant of the popular Word2Vec representation (based on Term Frequency-Inverse Document Frequency) representation and with a Bag- of-Words representation and a vector of lexicon-based sentiment values. The proposed text representation approach is assessed through the application of several machine learning classification algorithms on a dataset that is used extensively in literature for sentiment detection. The classification accuracy derived through the proposed hybrid vectorization approach is higher than when its individual components are used for text represenation, and comparable with state-of-the-art sentiment detection methodologies.