 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for Quantum Computing
Mar 26, 2026This review is designed to introduce mathematicians and computational scientists to quantum computing (QC) through the lens of uncertainty quantification (UQ) by presenting a mathematically rigorous and accessible narrative for understanding how noise and intrinsic randomness shape quantum computational outcomes in the language of mathematics. By grounding quantum computation in statistical inference, we highlight how mathematical tools such as probabilistic modeling, stochastic analysis, Bayesian inference, and sensitivity analysis, can directly address error propagation and reliability challenges in today's quantum devices. We also connect these methods to key scientific priorities in the field, including scalable uncertainty-aware algorithms and characterization of correlated errors. The purpose is to narrow the conceptual divide between applied mathematics, scientific computing and quantum information sciences, demonstrating how mathematically rooted UQ methodologies can guide validation, error mitigation, and principled algorithm design for emerging quantum technologies, in order to address challenges and opportunities present in modern-day quantum high performance and fault-tolerant quantum computing paradigms.
Sparse RBF Networks for PDEs and nonlocal equations: function space theory, operator calculus, and training algorithms
Jan 24, 2026This work presents a systematic analysis and extension of the sparse radial basis function network (SparseRBFnet) previously introduced for solving nonlinear partial differential equations (PDEs). Based on its adaptive-width shallow kernel network formulation, we further investigate its function-space characterization, operator evaluation, and computational algorithm. We provide a unified description of the solution space for a broad class of radial basis functions (RBFs). Under mild assumptions, this space admits a characterization as a Besov space, independent of the specific kernel choice. We further demonstrate how the explicit kernel-based structure enables quasi-analytical evaluation of both differential and nonlocal operators, including fractional Laplacians. On the computational end, we study the adaptive-width network and related three-phase training strategy through a comparison with variants concerning the modeling and algorithmic details. In particular, we assess the roles of second-order optimization, inner-weight training, network adaptivity, and anisotropic kernel parameterizations. Numerical experiments on high-order, fractional, and anisotropic PDE benchmarks illustrate the empirical insensitivity to kernel choice, as well as the resulting trade-offs between accuracy, sparsity, and computational cost. Collectively, these results consolidate and generalize the theoretical and computational framework of SparseRBFnet, supporting accurate sparse representations with efficient operator evaluation and offering theory-grounded guidance for algorithmic and modeling choices.
Solving Nonlinear PDEs with Sparse Radial Basis Function Networks
May 12, 2025We propose a novel framework for solving nonlinear PDEs using sparse radial basis function (RBF) networks. Sparsity-promoting regularization is employed to prevent over-parameterization and reduce redundant features. This work is motivated by longstanding challenges in traditional RBF collocation methods, along with the limitations of physics-informed neural networks (PINNs) and Gaussian process (GP) approaches, aiming to blend their respective strengths in a unified framework. The theoretical foundation of our approach lies in the function space of Reproducing Kernel Banach Spaces (RKBS) induced by one-hidden-layer neural networks of possibly infinite width. We prove a representer theorem showing that the solution to the sparse optimization problem in the RKBS admits a finite solution and establishes error bounds that offer a foundation for generalizing classical numerical analysis. The algorithmic framework is based on a three-phase algorithm to maintain computational efficiency through adaptive feature selection, second-order optimization, and pruning of inactive neurons. Numerical experiments demonstrate the effectiveness of our method and highlight cases where it offers notable advantages over GP approaches. This work opens new directions for adaptive PDE solvers grounded in rigorous analysis with efficient, learning-inspired implementation.
Nonuniform random feature models using derivative information
Oct 03, 2024We propose nonuniform data-driven parameter distributions for neural network initialization based on derivative data of the function to be approximated. These parameter distributions are developed in the context of non-parametric regression models based on shallow neural networks, and compare favorably to well-established uniform random feature models based on conventional weight initialization. We address the cases of Heaviside and ReLU activation functions, and their smooth approximations (sigmoid and softplus), and use recent results on the harmonic analysis and sparse representation of neural networks resulting from fully trained optimal networks. Extending analytic results that give exact representation, we obtain densities that concentrate in regions of the parameter space corresponding to neurons that are well suited to model the local derivatives of the unknown function. Based on these results, we suggest simplifications of these exact densities based on approximate derivative data in the input points that allow for very efficient sampling and lead to performance of random feature models close to optimal networks in several scenarios.
Orthogonally weighted $\ell_{2,1}$ regularization for rank-aware joint sparse recovery: algorithm and analysis
Nov 21, 2023



We propose and analyze an efficient algorithm for solving the joint sparse recovery problem using a new regularization-based method, named orthogonally weighted $\ell_{2,1}$ ($\mathit{ow}\ell_{2,1}$), which is specifically designed to take into account the rank of the solution matrix. This method has applications in feature extraction, matrix column selection, and dictionary learning, and it is distinct from commonly used $\ell_{2,1}$ regularization and other existing regularization-based approaches because it can exploit the full rank of the row-sparse solution matrix, a key feature in many applications. We provide a proof of the method's rank-awareness, establish the existence of solutions to the proposed optimization problem, and develop an efficient algorithm for solving it, whose convergence is analyzed. We also present numerical experiments to illustrate the theory and demonstrate the effectiveness of our method on real-life problems.
Nonconvex penalization for sparse neural networks
Apr 24, 2020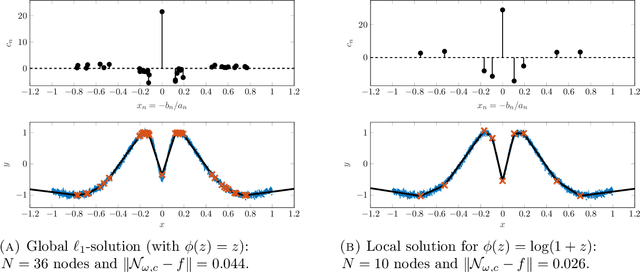

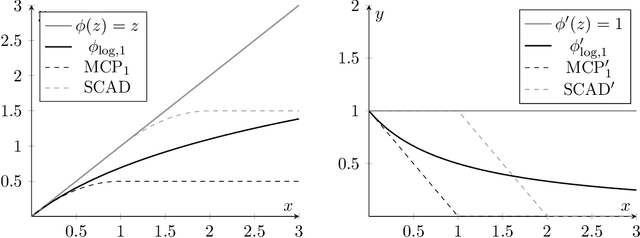

Training methods for artificial neural networks often rely on over-parameterization and random initialization in order to avoid spurious local minima of the loss function that fail to fit the data properly. To sidestep this, one can employ convex neural networks, which combine a convex interpretation of the loss term, sparsity promoting penalization of the outer weights, and greedy neuron insertion. However, the canonical $\ell_1$ penalty does not achieve a sufficient reduction in the number of nodes in a shallow network in the presence of large amounts of data, as observed in practice and supported by our theory. As a remedy, we propose a nonconvex penalization method for the outer weights that maintains the advantages of the convex approach. We investigate the analytic aspects of the method in the context of neural network integral representations and prove attainability of minimizers, together with a finite support property and approximation guarantees. Additionally, we describe how to numerically solve the minimization problem with an adaptive algorithm combining local gradient based training, and adaptive node insertion and extraction.