 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable and Efficient Large-Scale Generative Recommenders
May 22, 2026Generative recommendation models can model user behavior as sequences of events and provide a shared backbone for multiple recommendation tasks. In production, however, pre-training gains do not automatically translate into downstream application improvements: task headroom, repeated-training cost, serving latency, and item freshness all affect transfer. We describe our experience scaling a generative recommender from 2M to 1B backbone parameters, excluding embedding and decoding layers, in a production-scale title recommendation setting. Across multiple downstream tasks, we observe task-dependent scaling behavior: some tasks approach an empirical ceiling within the observed scale range, while others continue to benefit from additional capacity. This motivates using offset scaling-law fits as a diagnostic for where additional model scale may be more or less useful. We then study production constraints that arise when applying the model in practice. Frequent retraining over trillions of behavior tokens makes training and decoding efficiency important; cached serving can make the immediate next-token target stale; and newly launched titles may need to be scored from semantic metadata before collaborative ID embeddings are reliable. We address these issues with multi-token prediction for serving-latency alignment, sampled softmax and a projected decoding head for efficient repeated training, and semantic item towers with collaborative-embedding masking for cold-start adaptation. In a one-week production-shadow evaluation over 1M users, the 1B-backbone model achieves higher MRR than the 2M-backbone baseline across all reported tasks. Overall, the results support treating model scale as one component of a production transfer problem, alongside task headroom, decoding cost, serving-latency alignment, and item generalization.
Robust Post-Training for Generative Recommenders: Why Exponential Reward-Weighted SFT Outperforms RLHF
Mar 10, 2026Aligning generative recommender systems to user preferences via post-training is critical for closing the gap between next-item prediction and actual recommendation quality. Existing post-training methods are ill-suited for production-scale systems: RLHF methods reward hack due to noisy user feedback and unreliable reward models, offline RL alternatives require propensity scores that are unavailable, and online interaction is infeasible. We identify exponential reward-weighted SFT with weights $w = \exp(r/λ)$ as uniquely suited to this setting, and provide the theoretical and empirical foundations that explain why. By optimizing directly on observed rewards without querying a learned reward model, the method is immune to reward hacking, requires no propensity scores, and is fully offline. We prove the first policy improvement guarantees for this setting under noisy rewards, showing that the gap scales only logarithmically with catalog size and remains informative even for large item catalogs. Crucially, we show that temperature $λ$ explicitly and quantifiably controls the robustness-improvement tradeoff, providing practitioners with a single interpretable regularization hyperparameter with theoretical grounding. Experiments on three open-source and one proprietary dataset against four baselines confirm that exponential reward weighting is simple, scalable, and consistently outperforms RLHF-based alternatives.
Orthogonal Low Rank Embedding Stabilization
Aug 11, 2025The instability of embedding spaces across model retraining cycles presents significant challenges to downstream applications using user or item embeddings derived from recommendation systems as input features. This paper introduces a novel orthogonal low-rank transformation methodology designed to stabilize the user/item embedding space, ensuring consistent embedding dimensions across retraining sessions. Our approach leverages a combination of efficient low-rank singular value decomposition and orthogonal Procrustes transformation to map embeddings into a standardized space. This transformation is computationally efficient, lossless, and lightweight, preserving the dot product and inference quality while reducing operational burdens. Unlike existing methods that modify training objectives or embedding structures, our approach maintains the integrity of the primary model application and can be seamlessly integrated with other stabilization techniques.
Multi-criteria Similarity-based Anomaly Detection using Pareto Depth Analysis
Aug 20, 2015



We consider the problem of identifying patterns in a data set that exhibit anomalous behavior, often referred to as anomaly detection. Similarity-based anomaly detection algorithms detect abnormally large amounts of similarity or dissimilarity, e.g.~as measured by nearest neighbor Euclidean distances between a test sample and the training samples. In many application domains there may not exist a single dissimilarity measure that captures all possible anomalous patterns. In such cases, multiple dissimilarity measures can be defined, including non-metric measures, and one can test for anomalies by scalarizing using a non-negative linear combination of them. If the relative importance of the different dissimilarity measures are not known in advance, as in many anomaly detection applications, the anomaly detection algorithm may need to be executed multiple times with different choices of weights in the linear combination. In this paper, we propose a method for similarity-based anomaly detection using a novel multi-criteria dissimilarity measure, the Pareto depth. The proposed Pareto depth analysis (PDA) anomaly detection algorithm uses the concept of Pareto optimality to detect anomalies under multiple criteria without having to run an algorithm multiple times with different choices of weights. The proposed PDA approach is provably better than using linear combinations of the criteria and shows superior performance on experiments with synthetic and real data sets.
* The work is submitted to IEEE TNNLS Special Issue on Learning in Non-(geo)metric Spaces for review on October 28, 2013, revised on July 26, 2015 and accepted on July 30, 2015. A preliminary version of this work is reported in the conference Advances in Neural Information Processing Systems (NIPS) 2012
Pareto-depth for Multiple-query Image Retrieval
Feb 21, 2014
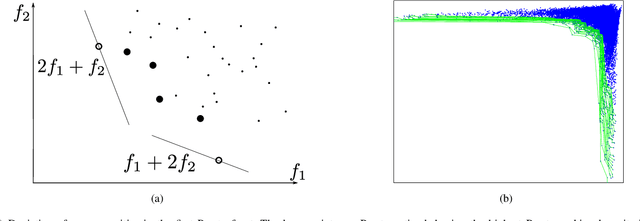
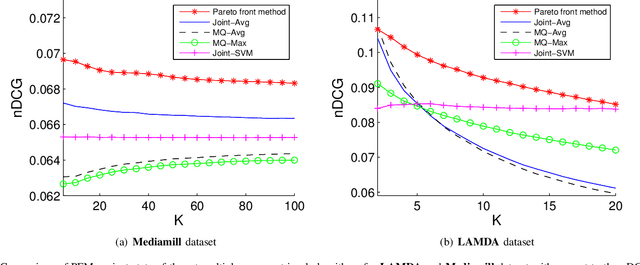
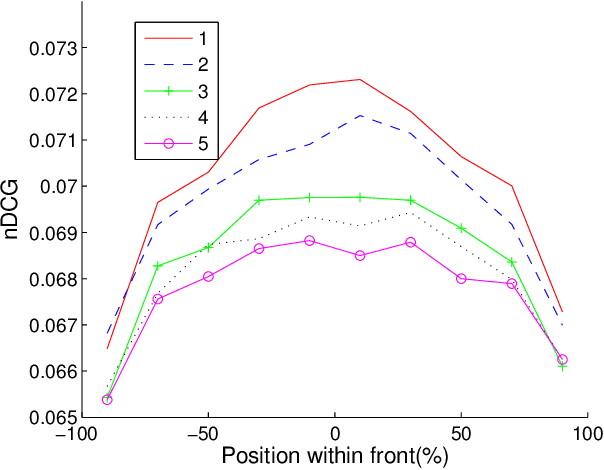
Most content-based image retrieval systems consider either one single query, or multiple queries that include the same object or represent the same semantic information. In this paper we consider the content-based image retrieval problem for multiple query images corresponding to different image semantics. We propose a novel multiple-query information retrieval algorithm that combines the Pareto front method (PFM) with efficient manifold ranking (EMR). We show that our proposed algorithm outperforms state of the art multiple-query retrieval algorithms on real-world image databases. We attribute this performance improvement to concavity properties of the Pareto fronts, and prove a theoretical result that characterizes the asymptotic concavity of the fronts.
Multi-criteria Anomaly Detection using Pareto Depth Analysis
Jan 07, 2013



We consider the problem of identifying patterns in a data set that exhibit anomalous behavior, often referred to as anomaly detection. In most anomaly detection algorithms, the dissimilarity between data samples is calculated by a single criterion, such as Euclidean distance. However, in many cases there may not exist a single dissimilarity measure that captures all possible anomalous patterns. In such a case, multiple criteria can be defined, and one can test for anomalies by scalarizing the multiple criteria using a linear combination of them. If the importance of the different criteria are not known in advance, the algorithm may need to be executed multiple times with different choices of weights in the linear combination. In this paper, we introduce a novel non-parametric multi-criteria anomaly detection method using Pareto depth analysis (PDA). PDA uses the concept of Pareto optimality to detect anomalies under multiple criteria without having to run an algorithm multiple times with different choices of weights. The proposed PDA approach scales linearly in the number of criteria and is provably better than linear combinations of the criteria.
* Removed an unnecessary line from Algorithm 1