 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHREC 2025: Retrieval of Optimal Objects for Multi-modal Enhanced Language and Spatial Assistance (ROOMELSA)
Aug 12, 2025Recent 3D retrieval systems are typically designed for simple, controlled scenarios, such as identifying an object from a cropped image or a brief description. However, real-world scenarios are more complex, often requiring the recognition of an object in a cluttered scene based on a vague, free-form description. To this end, we present ROOMELSA, a new benchmark designed to evaluate a system's ability to interpret natural language. Specifically, ROOMELSA attends to a specific region within a panoramic room image and accurately retrieves the corresponding 3D model from a large database. In addition, ROOMELSA includes over 1,600 apartment scenes, nearly 5,200 rooms, and more than 44,000 targeted queries. Empirically, while coarse object retrieval is largely solved, only one top-performing model consistently ranked the correct match first across nearly all test cases. Notably, a lightweight CLIP-based model also performed well, although it struggled with subtle variations in materials, part structures, and contextual cues, resulting in occasional errors. These findings highlight the importance of tightly integrating visual and language understanding. By bridging the gap between scene-level grounding and fine-grained 3D retrieval, ROOMELSA establishes a new benchmark for advancing robust, real-world 3D recognition systems.
DeepRadiologyNet: Radiologist Level Pathology Detection in CT Head Images
Dec 02, 2017

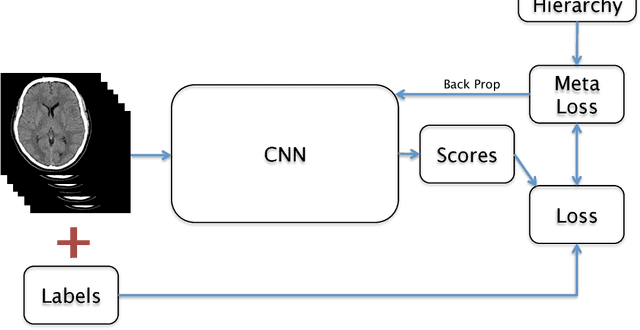
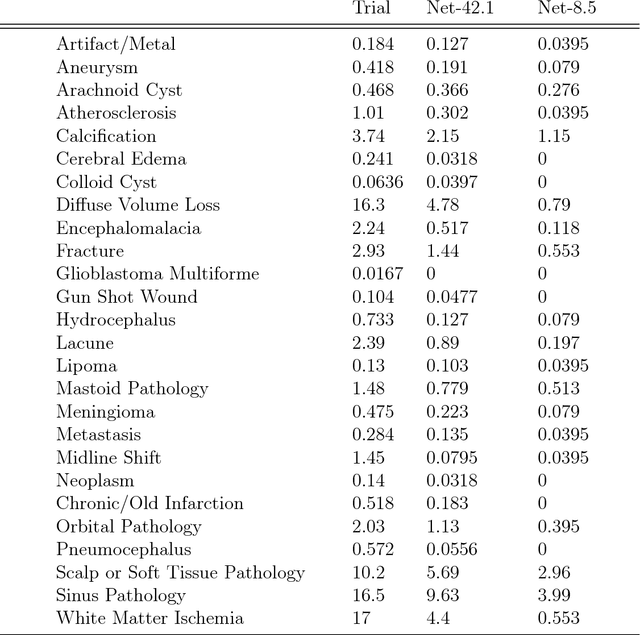
We describe a system to automatically filter clinically significant findings from computerized tomography (CT) head scans, operating at performance levels exceeding that of practicing radiologists. Our system, named DeepRadiologyNet, builds on top of deep convolutional neural networks (CNNs) trained using approximately 3.5 million CT head images gathered from over 24,000 studies taken from January 1, 2015 to August 31, 2015 and January 1, 2016 to April 30 2016 in over 80 clinical sites. For our initial system, we identified 30 phenomenological traits to be recognized in the CT scans. To test the system, we designed a clinical trial using over 4.8 million CT head images (29,925 studies), completely disjoint from the training and validation set, interpreted by 35 US Board Certified radiologists with specialized CT head experience. We measured clinically significant error rates to ascertain whether the performance of DeepRadiologyNet was comparable to or better than that of US Board Certified radiologists. DeepRadiologyNet achieved a clinically significant miss rate of 0.0367% on automatically selected high-confidence studies. Thus, DeepRadiologyNet enables significant reduction in the workload of human radiologists by automatically filtering studies and reporting on the high-confidence ones at an operating point well below the literal error rate for US Board Certified radiologists, estimated at 0.82%.