 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Curriculum Alignment across Topical Coverage, Competency, and Cognitive Depth: A Longitudinal Framework Applied to CS2013 and CS2023
Jun 17, 2026Undergraduate computer science is governed by international curricular guidelines revised about once a decade, yet programs lack a reliable, reproducible way to measure how completely they cover the current guidelines and how that coverage shifts when the guidelines are restructured. We address this with a human-in-the-loop pipeline that measures a program's coverage of an external body of knowledge, applied longitudinally to one accredited BSc in Computer Science against Computer Science Curricula 2013 (CS2013) and 2023 (CS2023). The pipeline represents the program and each guideline as structured corpora, generates candidate course-to-knowledge-unit matches by semantic retrieval, and confirms them through human judgment under an explicit coverage definition. Of seven benchmarked retrievers, a reciprocal-rank-fusion ensemble was strongest, and a reputed long-context model underperformed a small sentence model, so retriever choice must be measured. Both maps were validated by an independent second rater (Cohen's kappa 0.64 for CS2023, 0.69 for CS2013). The program covers 49.7% of CS2023 and 50.9% of CS2013 knowledge units, near-constant across a decade. Extending the same retrieve-then-confirm design to competency articulation and cognitive depth shows that the program articulates the competency for ~88% of covered units under each guideline, yet delivers it at the recommended depth for 76% of present units under CS2023 against 95% under CS2013, a gap reflecting the newer guideline's raised expectations, not the program. The longitudinal comparison separates persistent structural gaps (parallel and distributed computing, foundations of programming languages, systems fundamentals), uncovered against both guidelines and ABET, from differences that reflect the standard's evolution. The instrument is reusable and available from the authors on request.
An NLP-Driven Framework for Curriculum-Labor Market Alignment: Schema-Constrained LLM Extraction, ESCO-Anchored Semantic Matching, and Multi-Dimensional Gap Quantification
Jun 01, 2026Schema-constrained information extraction from diverse educational and labor-market corpora remains an open challenge in natural language processing because existing pipelines rely primarily on lexical-surface methods that cannot recover implicit competencies, lack grounding in shared taxonomies, and provide no formal measures of extraction reliability or document-level completeness. To address these limitations, this paper proposes a four-stage NLP framework that combines (i) schema-constrained prompting of a two-model frontier-LLM ensemble against a JSON Schema-enforced seven-slot competency formalism, (ii) Sentence-BERT (SBERT) alignment of the extracted records against an eleven-domain ESCO v1.2.1 controlled vocabulary, (iii) a two-tier adjudication protocol that resolves inter-model disagreements, and (iv) a verification mechanism that combines per-slot Cohen's kappa, schema conformance, and document-level completeness audits. The framework is instantiated for a critical application in higher-education quality assurance, namely curriculum-labor market alignment for the ABET-accredited BSc Computer Science program at the United Arab Emirates University. The pipeline extracts 400 competency records from the 85-course 2025-2026 study plan and aligns them, under a five-scope analysis ranging from the computing core to a probability-weighted student trajectory, with 30 job postings (483 requirement clauses) at an SBERT cosine threshold of 0.50. The extractor achieves Cohen's kappa of 0.79 on the skill slot, with 100% schema conformance and 100% document-level completeness. The alignment surfaces interpretable supply-demand gaps of 25.0% in general and transversal skills, 13.8% in algorithms and computational theory, and 12.2% in software engineering and project management, with a near-zero 1.8% gap in artificial intelligence and data science despite 38.6% supply coverage.
The Nonverbal Syntax Framework: An Evidence-Based Tiered System for Inferring Learner States from Observable Behavioral Cues
Apr 28, 2026Understanding learners' cognitive and affective states underpins adaptive educational systems and effective teaching. Although research links nonverbal cues to internal states, no framework calibrates them to evidence. We present the Nonverbal Syntax Framework, drawn from a systematic review of 908 studies and 17,043 cue-state mappings (Turaev et al., 2026). The framework addresses three challenges: terminological fragmentation (behaviors described inconsistently), evidence heterogeneity (single observations to replicated findings), and state ambiguity (similar patterns indicating multiple states). Normalization consolidated 5,537 state labels into 2,010 canonical states (63.7%) and 11,521 cues into 6,434 normalized cues (44.2%) across nine behavioral channels. Dual-evidence assessment separately evaluates Component Evidence (coverage of cues and states) and Relationship Evidence (independent studies per cue-state link). 52% of "Very High" relationships rest on one paper, so separation enables calibrated rather than overconfident inference from preliminary findings. The framework's four levels comprise a Cue Vocabulary of 6,434 indicators classified as observable/instrumental; State Clusters linking 2,010 states to indicative cues; State Profiles with multimodal behavioral signatures and actionable specifications; and Discriminative Analysis distinguishing 1,215 confusable state pairs. We identify 480 actionable R1-R4 relationships (three or more independent papers), the replicated core of six decades of research, covering 35.5% of mappings across 47 key learning states and 111 distinct indicators. The remaining 91.5% (9,653 single-paper findings) form exploratory hypotheses for replication. The framework gives researchers an empirical foundation for identifying gaps, practitioners evidence-based tools for state inference, and technologists validated features for multimodal detection.
SDN Flow Entry Management Using Reinforcement Learning
Sep 24, 2018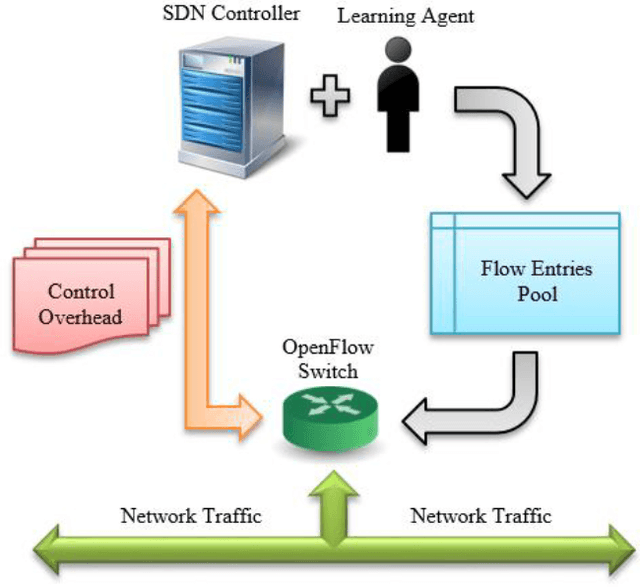
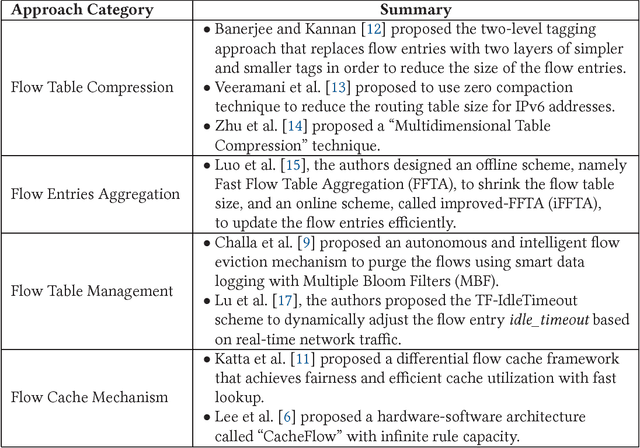
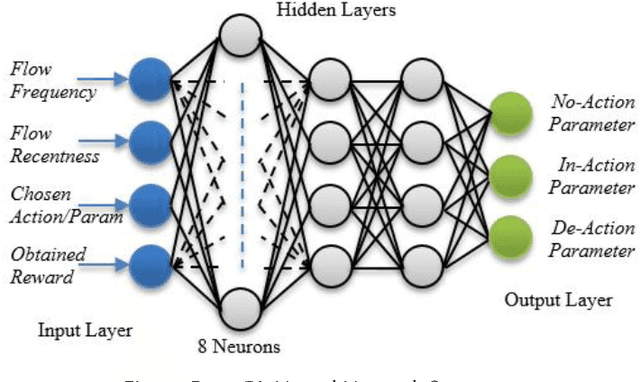
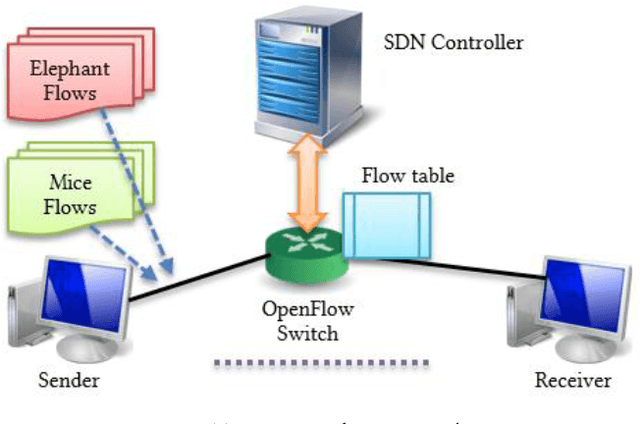
Modern information technology services largely depend on cloud infrastructures to provide their services. These cloud infrastructures are built on top of datacenter networks (DCNs) constructed with high-speed links, fast switching gear, and redundancy to offer better flexibility and resiliency. In this environment, network traffic includes long-lived (elephant) and short-lived (mice) flows with partitioned and aggregated traffic patterns. Although SDN-based approaches can efficiently allocate networking resources for such flows, the overhead due to network reconfiguration can be significant. With limited capacity of Ternary Content-Addressable Memory (TCAM) deployed in an OpenFlow enabled switch, it is crucial to determine which forwarding rules should remain in the flow table, and which rules should be processed by the SDN controller in case of a table-miss on the SDN switch. This is needed in order to obtain the flow entries that satisfy the goal of reducing the long-term control plane overhead introduced between the controller and the switches. To achieve this goal, we propose a machine learning technique that utilizes two variations of reinforcement learning (RL) algorithms-the first of which is traditional reinforcement learning algorithm based while the other is deep reinforcement learning based. Emulation results using the RL algorithm show around 60% improvement in reducing the long-term control plane overhead, and around 14% improvement in the table-hit ratio compared to the Multiple Bloom Filters (MBF) method given a fixed size flow table of 4KB.