 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Based Optimistic Policy Iteration For Multi-Agent MDPs with Kullback-Leibler Control Cost
Oct 19, 2024

This paper proposes an agent-based optimistic policy iteration (OPI) scheme for learning stationary optimal stochastic policies in multi-agent Markov Decision Processes (MDPs), in which agents incur a Kullback-Leibler (KL) divergence cost for their control efforts and an additional cost for the joint state. The proposed scheme consists of a greedy policy improvement step followed by an m-step temporal difference (TD) policy evaluation step. We use the separable structure of the instantaneous cost to show that the policy improvement step follows a Boltzmann distribution that depends on the current value function estimate and the uncontrolled transition probabilities. This allows agents to compute the improved joint policy independently. We show that both the synchronous (entire state space evaluation) and asynchronous (a uniformly sampled set of substates) versions of the OPI scheme with finite policy evaluation rollout converge to the optimal value function and an optimal joint policy asymptotically. Simulation results on a multi-agent MDP with KL control cost variant of the Stag-Hare game validates our scheme's performance in terms of minimizing the cost return.
SACPlanner: Real-World Collision Avoidance with a Soft Actor Critic Local Planner and Polar State Representations
Mar 21, 2023



We study the training performance of ROS local planners based on Reinforcement Learning (RL), and the trajectories they produce on real-world robots. We show that recent enhancements to the Soft Actor Critic (SAC) algorithm such as RAD and DrQ achieve almost perfect training after only 10000 episodes. We also observe that on real-world robots the resulting SACPlanner is more reactive to obstacles than traditional ROS local planners such as DWA.
DeepTOP: Deep Threshold-Optimal Policy for MDPs and RMABs
Sep 28, 2022
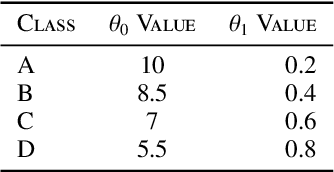
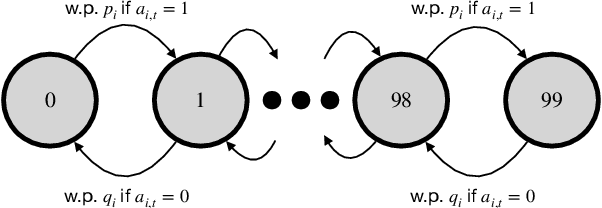
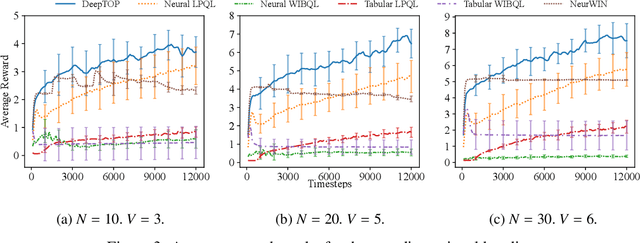
We consider the problem of learning the optimal threshold policy for control problems. Threshold policies make control decisions by evaluating whether an element of the system state exceeds a certain threshold, whose value is determined by other elements of the system state. By leveraging the monotone property of threshold policies, we prove that their policy gradients have a surprisingly simple expression. We use this simple expression to build an off-policy actor-critic algorithm for learning the optimal threshold policy. Simulation results show that our policy significantly outperforms other reinforcement learning algorithms due to its ability to exploit the monotone property. In addition, we show that the Whittle index, a powerful tool for restless multi-armed bandit problems, is equivalent to the optimal threshold policy for an alternative problem. This observation leads to a simple algorithm that finds the Whittle index by learning the optimal threshold policy in the alternative problem. Simulation results show that our algorithm learns the Whittle index much faster than several recent studies that learn the Whittle index through indirect means.
NeurWIN: Neural Whittle Index Network For Restless Bandits Via Deep RL
Oct 05, 2021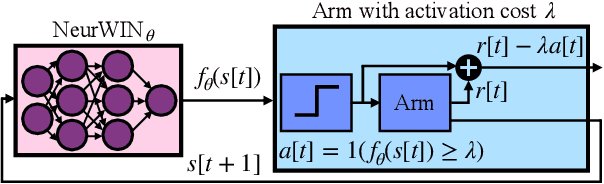
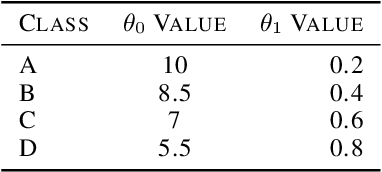
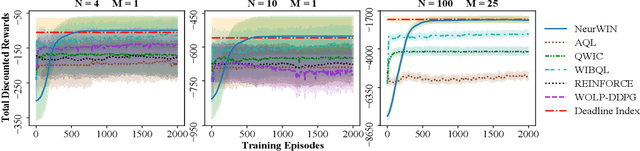
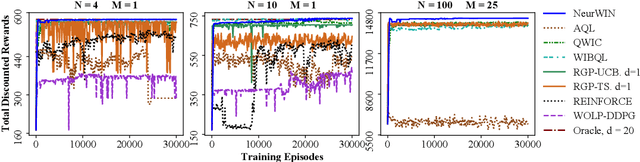
Whittle index policy is a powerful tool to obtain asymptotically optimal solutions for the notoriously intractable problem of restless bandits. However, finding the Whittle indices remains a difficult problem for many practical restless bandits with convoluted transition kernels. This paper proposes NeurWIN, a neural Whittle index network that seeks to learn the Whittle indices for any restless bandits by leveraging mathematical properties of the Whittle indices. We show that a neural network that produces the Whittle index is also one that produces the optimal control for a set of Markov decision problems. This property motivates using deep reinforcement learning for the training of NeurWIN. We demonstrate the utility of NeurWIN by evaluating its performance for three recently studied restless bandit problems. Our experiment results show that the performance of NeurWIN is significantly better than other RL algorithms.