 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Volume Preserving-based Feature Fusion Approach to Group-Level Expression Recognition on Crowd Videos
Nov 28, 2018
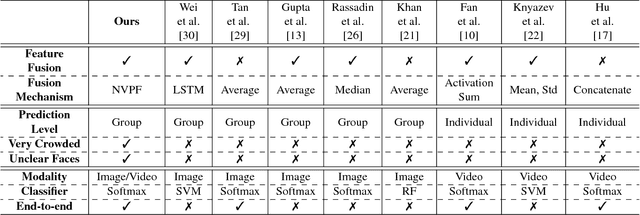

Group-level emotion recognition (ER) is a growing research area as the demands for assessing crowds of all sizes is becoming an interest in both the security arena and social media. This work investigates group-level expression recognition on crowd videos where information is not only aggregated across a variable length sequence of frames but also over the set of faces within each frame to produce aggregated recognition results. In this paper, we propose an effective deep feature level fusion mechanism to model the spatial-temporal information in the crowd videos. Furthermore, we extend our proposed NVP fusion mechanism to temporal NVP fussion appoarch to learn the temporal information between frames. In order to demonstrate the robustness and effectiveness of each component in the proposed approach, three experiments were conducted: (i) evaluation on the AffectNet database to benchmark the proposed emoNet for recognizing facial expression; (ii) evaluation on EmotiW2018 to benchmark the proposed deep feature level fusion mechanism NVPF; and, (iii) examine the proposed TNVPF on an innovative Group-level Emotion on Crowd Videos (GECV) dataset composed of 627 videos collected from social media. GECV dataset is a collection of videos ranging in duration from 10 to 20 seconds of crowds of twenty (20) or more subjects and each video is labeled as positive, negative, or neutral.
Automatic Face Aging in Videos via Deep Reinforcement Learning
Nov 27, 2018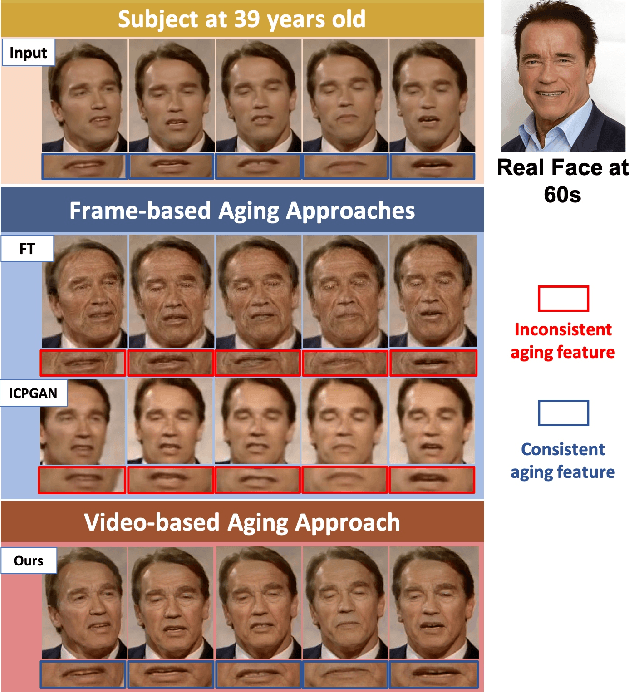

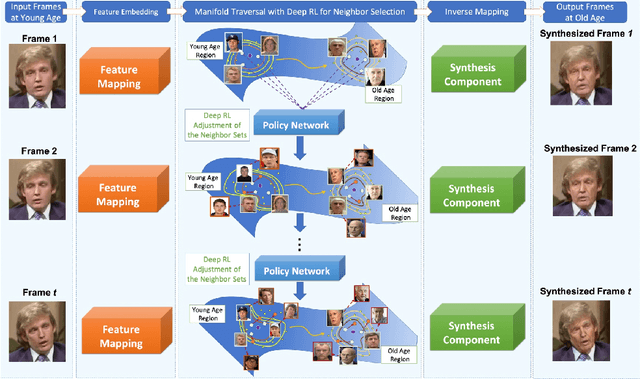
This paper presents a novel approach for synthesizing automatically age-progressed facial images in video sequences using Deep Reinforcement Learning. The proposed method models facial structures and the longitudinal face-aging process of given subjects coherently across video frames. The approach is optimized using a long-term reward, Reinforcement Learning function with deep feature extraction from Deep Convolutional Neural Network. Unlike previous age-progression methods that are only able to synthesize an aged likeness of a face from a single input image, the proposed approach is capable of age-progressing facial likenesses in videos with consistently synthesized facial features across frames. In addition, the deep reinforcement learning method guarantees preservation of the visual identity of input faces after age-progression. Results on videos of our new collected aging face AGFW-v2 database demonstrate the advantages of the proposed solution in terms of both quality of age-progressed faces, temporal smoothness, and cross-age face verification.
MobiFace: A Lightweight Deep Learning Face Recognition on Mobile Devices
Nov 27, 2018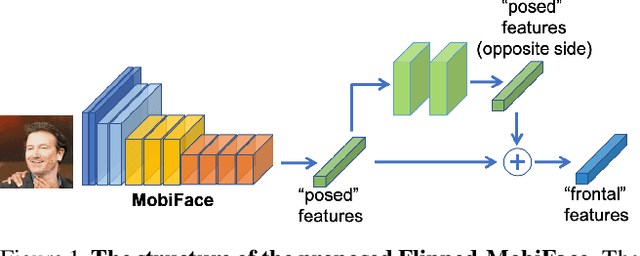
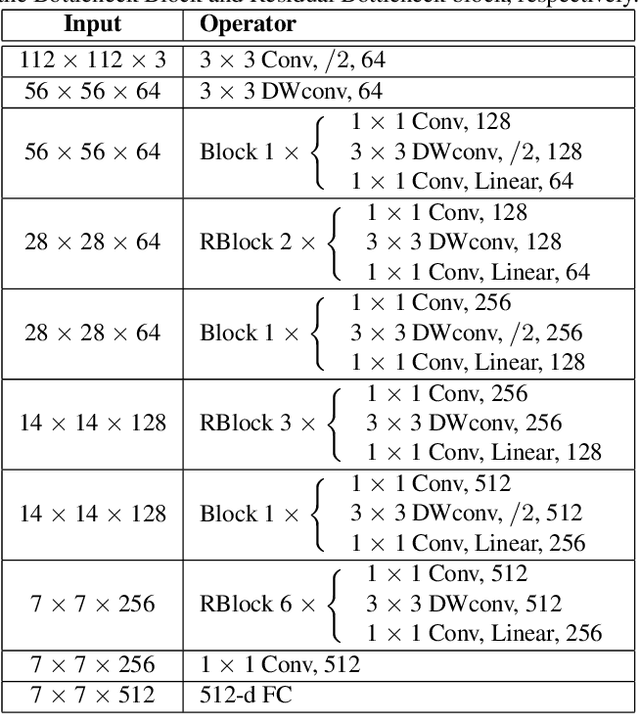
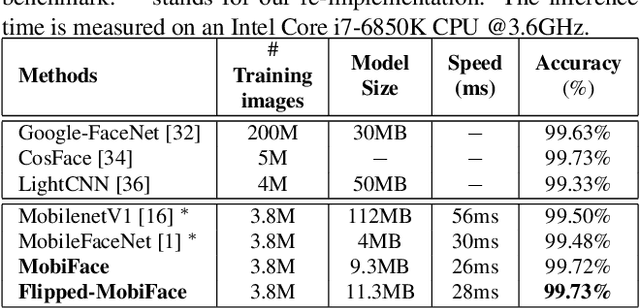

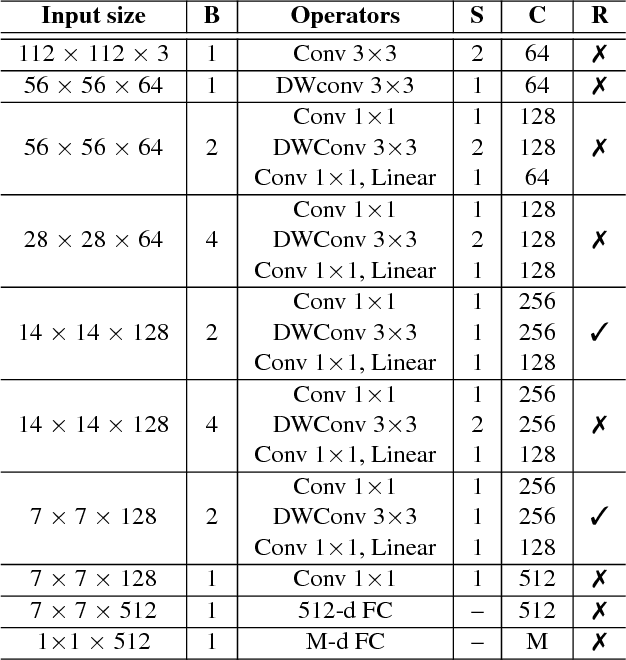
Deep neural networks have been widely used in numerous computer vision applications, particularly in face recognition. However, deploying deep neural network face recognition on mobile devices is still limited since most high-accuracy deep models are both time and GPU consumption in the inference stage. Therefore, developing a lightweight deep neural network is one of the most promising solutions to deploy face recognition on mobile devices. Such the lightweight deep neural network requires efficient memory with small number of weights representation and low cost operators. In this paper a novel deep neural network named MobiFace, which is simple but effective, is proposed for productively deploying face recognition on mobile devices. The experimental results have shown that our lightweight MobiFace is able to achieve high performance with 99.7% on LFW database and 91.3% on large-scale challenging Megaface database. It is also eventually competitive against large-scale deep-networks face recognition while significant reducing computational time and memory consumption.
Learning from Longitudinal Face Demonstration - Where Tractable Deep Modeling Meets Inverse Reinforcement Learning
Sep 04, 2018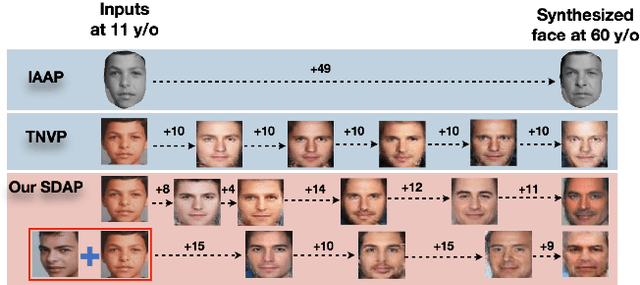
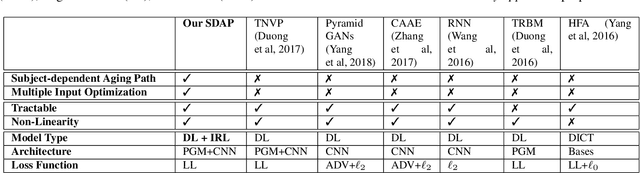
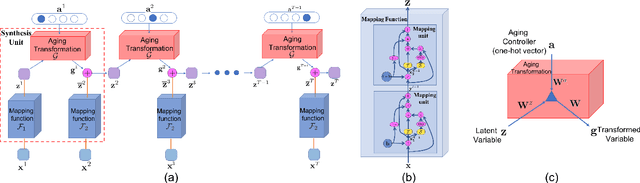
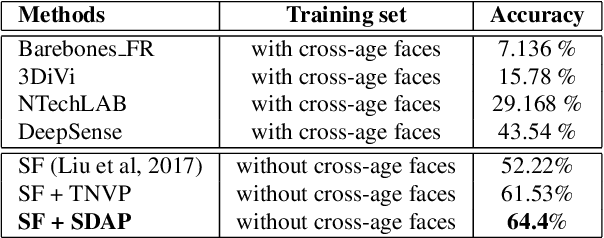
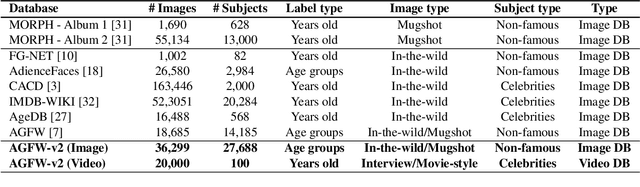
This paper presents a novel Subject-dependent Deep Aging Path (SDAP), which inherits the merits of both Generative Probabilistic Modeling and Inverse Reinforcement Learning to model the facial structures and the longitudinal face aging process of a given subject. The proposed SDAP is optimized using tractable log-likelihood objective functions with Convolutional Neural Networks (CNNs) based deep feature extraction. Instead of applying a fixed aging development path for all input faces and subjects, SDAP is able to provide the most appropriate aging development path for individual subject that optimizes the reward aging formulation. Unlike previous methods that can take only one image as the input, SDAP further allows multiple images as inputs, i.e. all information of a subject at either the same or different ages, to produce the optimal aging path for the given subject. Finally, SDAP allows efficiently synthesizing in-the-wild aging faces. The proposed model is experimented in both tasks of face aging synthesis and cross-age face verification. The experimental results consistently show SDAP achieves the state-of-the-art performance on numerous face aging databases, i.e. FG-NET, MORPH, AginG Faces in the Wild (AGFW), and Cross-Age Celebrity Dataset (CACD). Furthermore, we also evaluate the performance of SDAP on large-scale Megaface challenge to demonstrate the advantages of the proposed solution.
Longitudinal Face Aging in the Wild - Recent Deep Learning Approaches
Feb 23, 2018
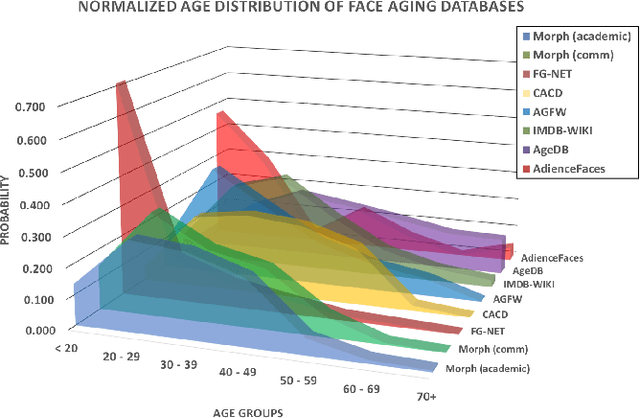

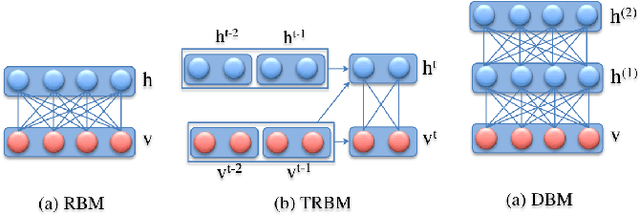
Face Aging has raised considerable attentions and interest from the computer vision community in recent years. Numerous approaches ranging from purely image processing techniques to deep learning structures have been proposed in literature. In this paper, we aim to give a review of recent developments of modern deep learning based approaches, i.e. Deep Generative Models, for Face Aging task. Their structures, formulation, learning algorithms as well as synthesized results are also provided with systematic discussions. Moreover, the aging databases used in most methods to learn the aging process are also reviewed.
Deep Appearance Models: A Deep Boltzmann Machine Approach for Face Modeling
Dec 21, 2017
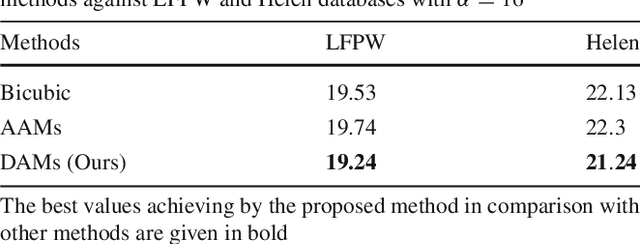
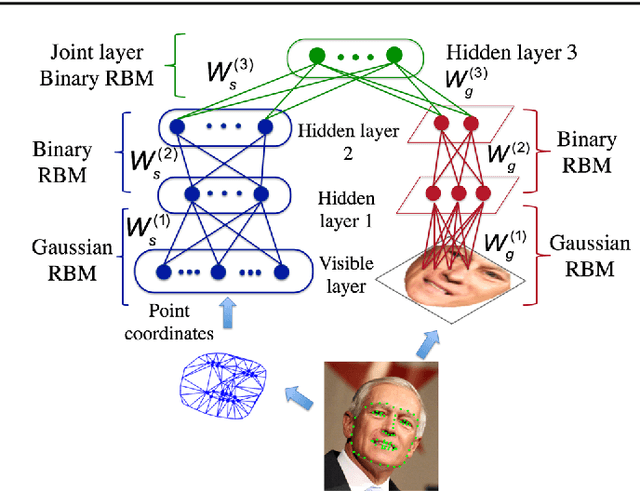
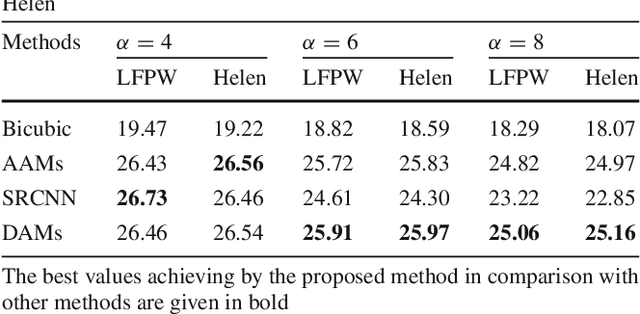
The "interpretation through synthesis" approach to analyze face images, particularly Active Appearance Models (AAMs) method, has become one of the most successful face modeling approaches over the last two decades. AAM models have ability to represent face images through synthesis using a controllable parameterized Principal Component Analysis (PCA) model. However, the accuracy and robustness of the synthesized faces of AAM are highly depended on the training sets and inherently on the generalizability of PCA subspaces. This paper presents a novel Deep Appearance Models (DAMs) approach, an efficient replacement for AAMs, to accurately capture both shape and texture of face images under large variations. In this approach, three crucial components represented in hierarchical layers are modeled using the Deep Boltzmann Machines (DBM) to robustly capture the variations of facial shapes and appearances. DAMs are therefore superior to AAMs in inferencing a representation for new face images under various challenging conditions. The proposed approach is evaluated in various applications to demonstrate its robustness and capabilities, i.e. facial super-resolution reconstruction, facial off-angle reconstruction or face frontalization, facial occlusion removal and age estimation using challenging face databases, i.e. Labeled Face Parts in the Wild (LFPW), Helen and FG-NET. Comparing to AAMs and other deep learning based approaches, the proposed DAMs achieve competitive results in those applications, thus this showed their advantages in handling occlusions, facial representation, and reconstruction.
Reformulating Level Sets as Deep Recurrent Neural Network Approach to Semantic Segmentation
Apr 12, 2017

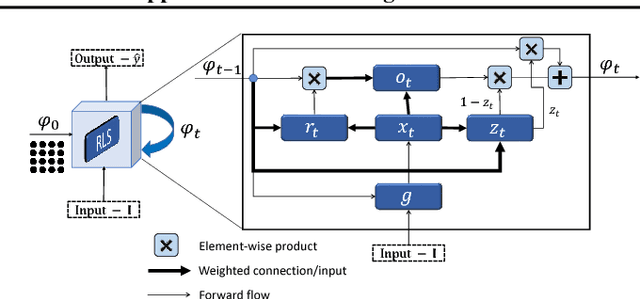
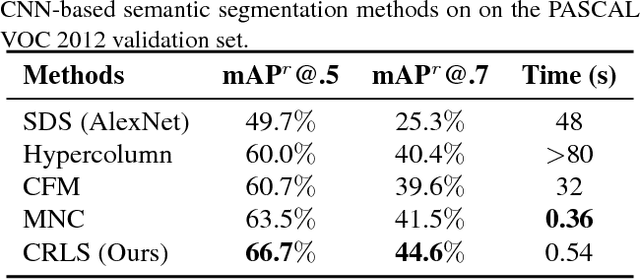
Variational Level Set (LS) has been a widely used method in medical segmentation. However, it is limited when dealing with multi-instance objects in the real world. In addition, its segmentation results are quite sensitive to initial settings and highly depend on the number of iterations. To address these issues and boost the classic variational LS methods to a new level of the learnable deep learning approaches, we propose a novel definition of contour evolution named Recurrent Level Set (RLS)} to employ Gated Recurrent Unit under the energy minimization of a variational LS functional. The curve deformation process in RLS is formed as a hidden state evolution procedure and updated by minimizing an energy functional composed of fitting forces and contour length. By sharing the convolutional features in a fully end-to-end trainable framework, we extend RLS to Contextual RLS (CRLS) to address semantic segmentation in the wild. The experimental results have shown that our proposed RLS improves both computational time and segmentation accuracy against the classic variations LS-based method, whereas the fully end-to-end system CRLS achieves competitive performance compared to the state-of-the-art semantic segmentation approaches.
Temporal Non-Volume Preserving Approach to Facial Age-Progression and Age-Invariant Face Recognition
Mar 24, 2017

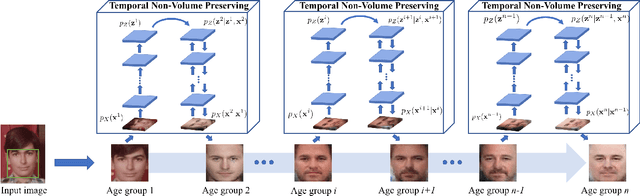
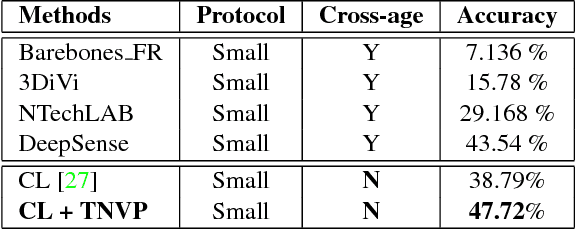
Modeling the long-term facial aging process is extremely challenging due to the presence of large and non-linear variations during the face development stages. In order to efficiently address the problem, this work first decomposes the aging process into multiple short-term stages. Then, a novel generative probabilistic model, named Temporal Non-Volume Preserving (TNVP) transformation, is presented to model the facial aging process at each stage. Unlike Generative Adversarial Networks (GANs), which requires an empirical balance threshold, and Restricted Boltzmann Machines (RBM), an intractable model, our proposed TNVP approach guarantees a tractable density function, exact inference and evaluation for embedding the feature transformations between faces in consecutive stages. Our model shows its advantages not only in capturing the non-linear age related variance in each stage but also producing a smooth synthesis in age progression across faces. Our approach can model any face in the wild provided with only four basic landmark points. Moreover, the structure can be transformed into a deep convolutional network while keeping the advantages of probabilistic models with tractable log-likelihood density estimation. Our method is evaluated in both terms of synthesizing age-progressed faces and cross-age face verification and consistently shows the state-of-the-art results in various face aging databases, i.e. FG-NET, MORPH, AginG Faces in the Wild (AGFW), and Cross-Age Celebrity Dataset (CACD). A large-scale face verification on Megaface challenge 1 is also performed to further show the advantages of our proposed approach.
Robust Deep Appearance Models
Jul 03, 2016
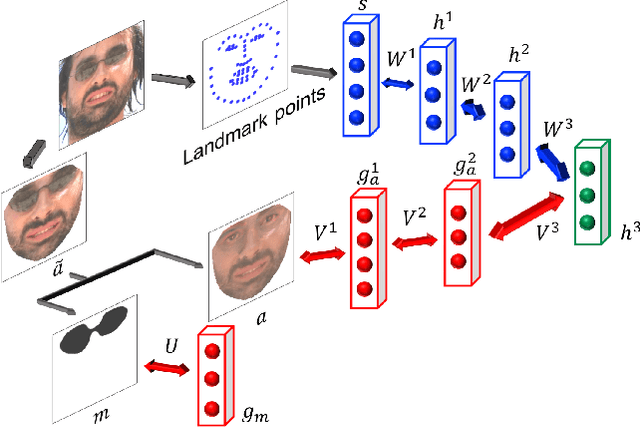


This paper presents a novel Robust Deep Appearance Models to learn the non-linear correlation between shape and texture of face images. In this approach, two crucial components of face images, i.e. shape and texture, are represented by Deep Boltzmann Machines and Robust Deep Boltzmann Machines (RDBM), respectively. The RDBM, an alternative form of Robust Boltzmann Machines, can separate corrupted/occluded pixels in the texture modeling to achieve better reconstruction results. The two models are connected by Restricted Boltzmann Machines at the top layer to jointly learn and capture the variations of both facial shapes and appearances. This paper also introduces new fitting algorithms with occlusion awareness through the mask obtained from the RDBM reconstruction. The proposed approach is evaluated in various applications by using challenging face datasets, i.e. Labeled Face Parts in the Wild (LFPW), Helen, EURECOM and AR databases, to demonstrate its robustness and capabilities.
Longitudinal Face Modeling via Temporal Deep Restricted Boltzmann Machines
Jun 07, 2016
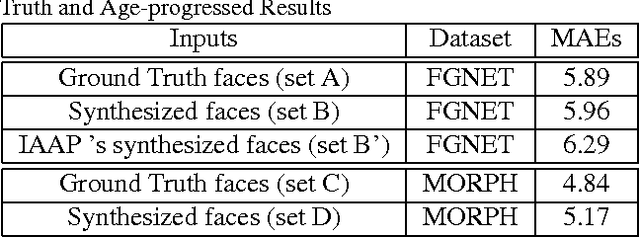

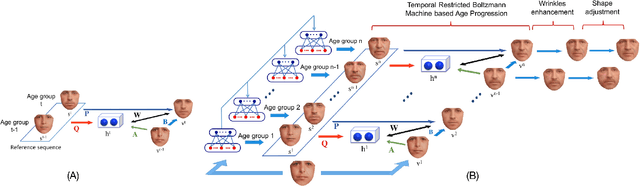
Modeling the face aging process is a challenging task due to large and non-linear variations present in different stages of face development. This paper presents a deep model approach for face age progression that can efficiently capture the non-linear aging process and automatically synthesize a series of age-progressed faces in various age ranges. In this approach, we first decompose the long-term age progress into a sequence of short-term changes and model it as a face sequence. The Temporal Deep Restricted Boltzmann Machines based age progression model together with the prototype faces are then constructed to learn the aging transformation between faces in the sequence. In addition, to enhance the wrinkles of faces in the later age ranges, the wrinkle models are further constructed using Restricted Boltzmann Machines to capture their variations in different facial regions. The geometry constraints are also taken into account in the last step for more consistent age-progressed results. The proposed approach is evaluated using various face aging databases, i.e. FG-NET, Cross-Age Celebrity Dataset (CACD) and MORPH, and our collected large-scale aging database named AginG Faces in the Wild (AGFW). In addition, when ground-truth age is not available for input image, our proposed system is able to automatically estimate the age of the input face before aging process is employed.