 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Positive and Negative Role Models to Help People Make Good Decisions
Mar 03, 2026We consider a setting where agents take action by following their role models in a social network, and study strategies for a social planner to help agents by revealing whether the role models are positive or negative. Specifically, agents observe a local neighborhood of possible role models they can emulate, but do not know their true labels. Revealing a positive label encourages emulation, while revealing a negative one redirects agents toward alternative options. The social planner observes all labels, but operates under a limited disclosure budget that it selectively allocates to maximize social welfare (the expected number of agents who emulate adjacent positive role models). We consider both algorithms and hardness results for welfare maximization, and provide a sample-complexity guarantee when the planner observes a sampled subset of agents. We also consider fairness guarantees when agents belong to different groups. It is a technical challenge that the ability to reveal negative role models breaks submodularity. We thus introduce a proxy welfare function that remains submodular even when revealed targets include negative ones. When each agent has at most a constant number of negative target neighbors, we use this proxy to achieve a constant-factor approximation to the true optimal welfare gain. When agents belong to different groups, we also show that each group's welfare gain is within a constant factor of the optimum achievable if the full budget were allocated to that group. Beyond this basic model, we also propose an intervention model that directly connects high-risk agents to positive role models, and a coverage radius model that expands the visibility of selected positive role models. Lastly, we conduct extensive experiments on four real-world datasets to support our theoretical results and assess the effectiveness of the proposed algorithms.
PAC Learning with Improvements
Mar 05, 2025One of the most basic lower bounds in machine learning is that in nearly any nontrivial setting, it takes $\textit{at least}$ $1/\epsilon$ samples to learn to error $\epsilon$ (and more, if the classifier being learned is complex). However, suppose that data points are agents who have the ability to improve by a small amount if doing so will allow them to receive a (desired) positive classification. In that case, we may actually be able to achieve $\textit{zero}$ error by just being "close enough". For example, imagine a hiring test used to measure an agent's skill at some job such that for some threshold $\theta$, agents who score above $\theta$ will be successful and those who score below $\theta$ will not (i.e., learning a threshold on the line). Suppose also that by putting in effort, agents can improve their skill level by some small amount $r$. In that case, if we learn an approximation $\hat{\theta}$ of $\theta$ such that $\theta \leq \hat{\theta} \leq \theta + r$ and use it for hiring, we can actually achieve error zero, in the sense that (a) any agent classified as positive is truly qualified, and (b) any agent who truly is qualified can be classified as positive by putting in effort. Thus, the ability for agents to improve has the potential to allow for a goal one could not hope to achieve in standard models, namely zero error. In this paper, we explore this phenomenon more broadly, giving general results and examining under what conditions the ability of agents to improve can allow for a reduction in the sample complexity of learning, or alternatively, can make learning harder. We also examine both theoretically and empirically what kinds of improvement-aware algorithms can take into account agents who have the ability to improve to a limited extent when it is in their interest to do so.
Learning Actionable Counterfactual Explanations in Large State Spaces
Apr 25, 2024



Counterfactual explanations (CFEs) are sets of actions that an agent with a negative classification could take to achieve a (desired) positive classification, for consequential decisions such as loan applications, hiring, admissions, etc. In this work, we consider settings where optimal CFEs correspond to solutions of weighted set cover problems. In particular, there is a collection of actions that agents can perform that each have their own cost and each provide the agent with different sets of capabilities. The agent wants to perform the cheapest subset of actions that together provide all the needed capabilities to achieve a positive classification. Since this is an NP-hard optimization problem, we are interested in the question: can we, from training data (instances of agents and their optimal CFEs) learn a CFE generator that will quickly provide optimal sets of actions for new agents? In this work, we provide a deep-network learning procedure that we show experimentally is able to achieve strong performance at this task. We consider several problem formulations, including formulations in which the underlying "capabilities" and effects of actions are not explicitly provided, and so there is an informational challenge in addition to the computational challenge. Our problem can also be viewed as one of learning an optimal policy in a family of large but deterministic Markov Decision Processes (MDPs).
Flickr Africa: Examining Geo-Diversity in Large-Scale, Human-Centric Visual Data
Aug 16, 2023Biases in large-scale image datasets are known to influence the performance of computer vision models as a function of geographic context. To investigate the limitations of standard Internet data collection methods in low- and middle-income countries, we analyze human-centric image geo-diversity on a massive scale using geotagged Flickr images associated with each nation in Africa. We report the quantity and content of available data with comparisons to population-matched nations in Europe as well as the distribution of data according to fine-grained intra-national wealth estimates. Temporal analyses are performed at two-year intervals to expose emerging data trends. Furthermore, we present findings for an ``othering'' phenomenon as evidenced by a substantial number of images from Africa being taken by non-local photographers. The results of our study suggest that further work is required to capture image data representative of African people and their environments and, ultimately, to improve the applicability of computer vision models in a global context.
Setting Fair Incentives to Maximize Improvement
Feb 28, 2022We consider the problem of helping agents improve by setting short-term goals. Given a set of target skill levels, we assume each agent will try to improve from their initial skill level to the closest target level within reach or do nothing if no target level is within reach. We consider two models: the common improvement capacity model, where agents have the same limit on how much they can improve, and the individualized improvement capacity model, where agents have individualized limits. Our goal is to optimize the target levels for social welfare and fairness objectives, where social welfare is defined as the total amount of improvement, and fairness objectives are considered where the agents belong to different underlying populations. A key technical challenge of this problem is the non-monotonicity of social welfare in the set of target levels, i.e., adding a new target level may decrease the total amount of improvement as it may get easier for some agents to improve. This is especially challenging when considering multiple groups because optimizing target levels in isolation for each group and outputting the union may result in arbitrarily low improvement for a group, failing the fairness objective. Considering these properties, we provide algorithms for optimal and near-optimal improvement for both social welfare and fairness objectives. These algorithmic results work for both the common and individualized improvement capacity models. Furthermore, we show a placement of target levels exists that is approximately optimal for the social welfare of each group. Unlike the algorithmic results, this structural statement only holds in the common improvement capacity model, and we show counterexamples in the individualized improvement capacity model. Finally, we extend our algorithms to learning settings where we have only sample access to the initial skill levels of agents.
On classification of strategic agents who can both game and improve
Feb 28, 2022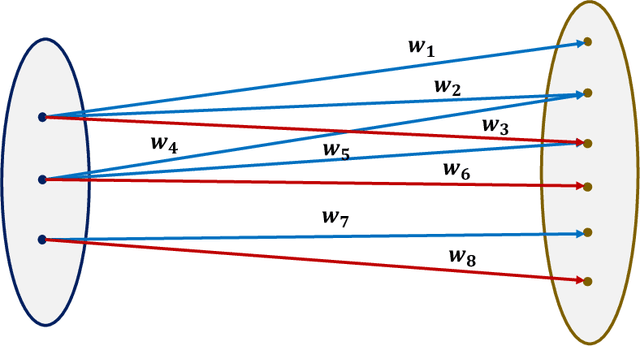
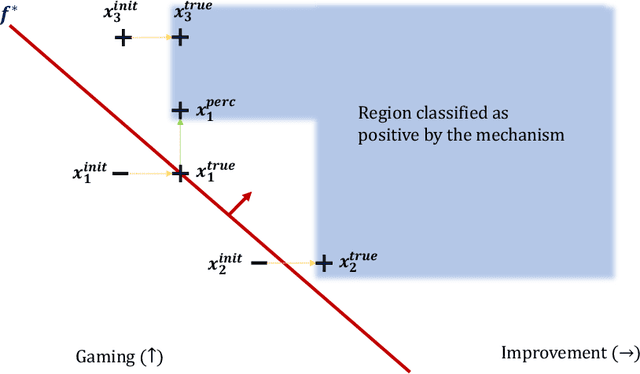
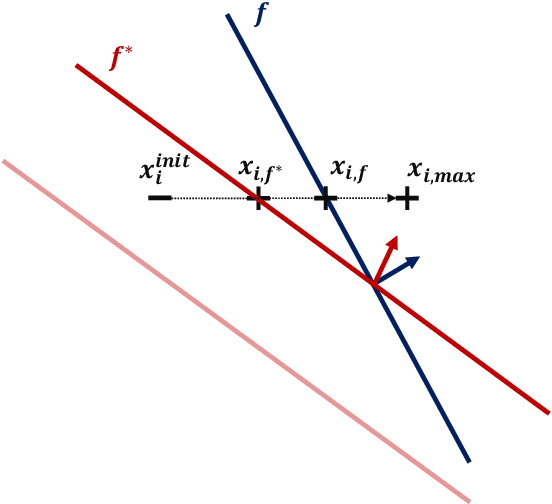
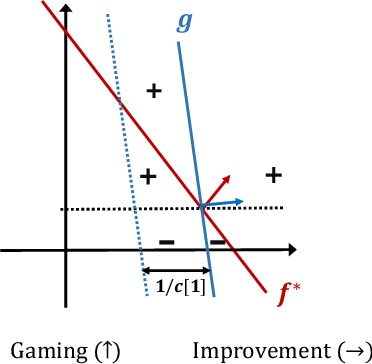
In this work, we consider classification of agents who can both game and improve. For example, people wishing to get a loan may be able to take some actions that increase their perceived credit-worthiness and others that also increase their true credit-worthiness. A decision-maker would like to define a classification rule with few false-positives (does not give out many bad loans) while yielding many true positives (giving out many good loans), which includes encouraging agents to improve to become true positives if possible. We consider two models for this problem, a general discrete model and a linear model, and prove algorithmic, learning, and hardness results for each. For the general discrete model, we give an efficient algorithm for the problem of maximizing the number of true positives subject to no false positives, and show how to extend this to a partial-information learning setting. We also show hardness for the problem of maximizing the number of true positives subject to a nonzero bound on the number of false positives, and that this hardness holds even for a finite-point version of our linear model. We also show that maximizing the number of true positives subject to no false positive is NP-hard in our full linear model. We additionally provide an algorithm that determines whether there exists a linear classifier that classifies all agents accurately and causes all improvable agents to become qualified, and give additional results for low-dimensional data.
The Strategic Perceptron
Aug 04, 2020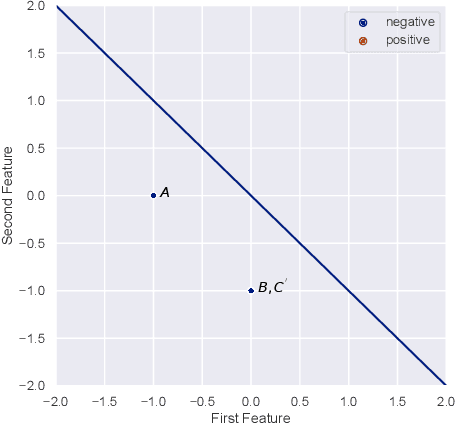
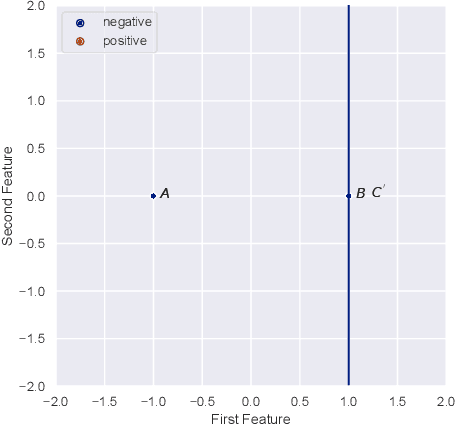
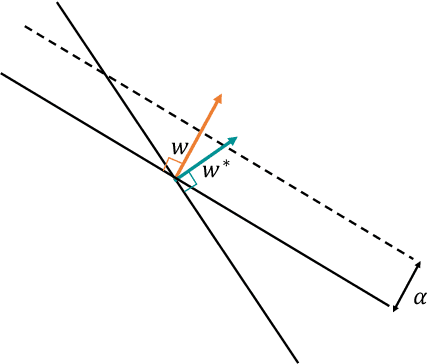
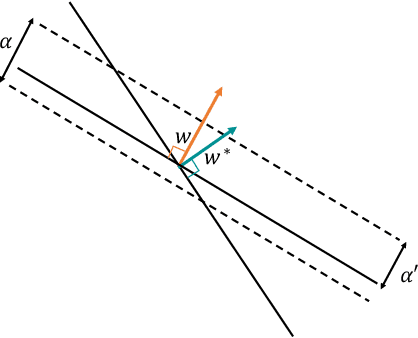
The classical Perceptron algorithm provides a simple and elegant procedure for learning a linear classifier. In each step, the algorithm observes the sample's position and label and may update the current predictor accordingly. In presence of strategic agents, however, the classifier may not be able to observe the true position but a position where the agent pretends to be in order to be classified desirably. Unlike the original setting with perfect knowledge of positions, in this situation the Perceptron algorithm fails to achieve its guarantees, and we illustrate examples with the predictor oscillating between two solutions forever, never reaching a perfect classifier even though one exists. Our main contribution is providing a modified Perceptron-style algorithm which finds a classifier in presence of strategic agents with both $\ell_2$ and weighted $\ell_1$ manipulation costs. In our baseline model, knowledge of the manipulation costs is assumed. In our most general model, we relax this assumption and provide an algorithm which learns and refines both the classifier and its cost estimates to achieve good mistake bounds even when manipulation costs are unknown.