 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Hyperbolic Deep Reinforcement Learning
Dec 16, 2025The performance of reinforcement learning (RL) agents depends critically on the quality of the underlying feature representations. Hyperbolic feature spaces are well-suited for this purpose, as they naturally capture hierarchical and relational structure often present in complex RL environments. However, leveraging these spaces commonly faces optimization challenges due to the nonstationarity of RL. In this work, we identify key factors that determine the success and failure of training hyperbolic deep RL agents. By analyzing the gradients of core operations in the Poincaré Ball and Hyperboloid models of hyperbolic geometry, we show that large-norm embeddings destabilize gradient-based training, leading to trust-region violations in proximal policy optimization (PPO). Based on these insights, we introduce Hyper++, a new hyperbolic PPO agent that consists of three components: (i) stable critic training through a categorical value loss instead of regression; (ii) feature regularization guaranteeing bounded norms while avoiding the curse of dimensionality from clipping; and (iii) using a more optimization-friendly formulation of hyperbolic network layers. In experiments on ProcGen, we show that Hyper++ guarantees stable learning, outperforms prior hyperbolic agents, and reduces wall-clock time by approximately 30%. On Atari-5 with Double DQN, Hyper++ strongly outperforms Euclidean and hyperbolic baselines. We release our code at https://github.com/Probabilistic-and-Interactive-ML/hyper-rl .
Plasticity Loss in Deep Reinforcement Learning: A Survey
Nov 07, 2024



Akin to neuroplasticity in human brains, the plasticity of deep neural networks enables their quick adaption to new data. This makes plasticity particularly crucial for deep Reinforcement Learning (RL) agents: Once plasticity is lost, an agent's performance will inevitably plateau because it cannot improve its policy to account for changes in the data distribution, which are a necessary consequence of its learning process. Thus, developing well-performing and sample-efficient agents hinges on their ability to remain plastic during training. Furthermore, the loss of plasticity can be connected to many other issues plaguing deep RL, such as training instabilities, scaling failures, overestimation bias, and insufficient exploration. With this survey, we aim to provide an overview of the emerging research on plasticity loss for academics and practitioners of deep reinforcement learning. First, we propose a unified definition of plasticity loss based on recent works, relate it to definitions from the literature, and discuss metrics for measuring plasticity loss. Then, we categorize and discuss numerous possible causes of plasticity loss before reviewing currently employed mitigation strategies. Our taxonomy is the first systematic overview of the current state of the field. Lastly, we discuss prevalent issues within the literature, such as a necessity for broader evaluation, and provide recommendations for future research, like gaining a better understanding of an agent's neural activity and behavior.
Breaking the Reclustering Barrier in Centroid-based Deep Clustering
Nov 04, 2024



This work investigates an important phenomenon in centroid-based deep clustering (DC) algorithms: Performance quickly saturates after a period of rapid early gains. Practitioners commonly address early saturation with periodic reclustering, which we demonstrate to be insufficient to address performance plateaus. We call this phenomenon the "reclustering barrier" and empirically show when the reclustering barrier occurs, what its underlying mechanisms are, and how it is possible to Break the Reclustering Barrier with our algorithm BRB. BRB avoids early over-commitment to initial clusterings and enables continuous adaptation to reinitialized clustering targets while remaining conceptually simple. Applying our algorithm to widely-used centroid-based DC algorithms, we show that (1) BRB consistently improves performance across a wide range of clustering benchmarks, (2) BRB enables training from scratch, and (3) BRB performs competitively against state-of-the-art DC algorithms when combined with a contrastive loss. We release our code and pre-trained models at https://github.com/Probabilistic-and-Interactive-ML/breaking-the-reclustering-barrier .
Text-Guided Image Clustering
Feb 05, 2024



Image clustering divides a collection of images into meaningful groups, typically interpreted post-hoc via human-given annotations. Those are usually in the form of text, begging the question of using text as an abstraction for image clustering. Current image clustering methods, however, neglect the use of generated textual descriptions. We, therefore, propose Text-Guided Image Clustering, i.e., generating text using image captioning and visual question-answering (VQA) models and subsequently clustering the generated text. Further, we introduce a novel approach to inject task- or domain knowledge for clustering by prompting VQA models. Across eight diverse image clustering datasets, our results show that the obtained text representations often outperform image features. Additionally, we propose a counting-based cluster explainability method. Our evaluations show that the derived keyword-based explanations describe clusters better than the respective cluster accuracy suggests. Overall, this research challenges traditional approaches and paves the way for a paradigm shift in image clustering, using generated text.
Neural Network Augmented Compartmental Pandemic Models
Dec 15, 2022Compartmental models are a tool commonly used in epidemiology for the mathematical modelling of the spread of infectious diseases, with their most popular representative being the Susceptible-Infected-Removed (SIR) model and its derivatives. However, current SIR models are bounded in their capabilities to model government policies in the form of non-pharmaceutical interventions (NPIs) and weather effects and offer limited predictive power. More capable alternatives such as agent based models (ABMs) are computationally expensive and require specialized hardware. We introduce a neural network augmented SIR model that can be run on commodity hardware, takes NPIs and weather effects into account and offers improved predictive power as well as counterfactual analysis capabilities. We demonstrate our models improvement of the state-of-the-art modeling COVID-19 in Austria during the 03.2020 to 03.2021 period and provide an outlook for the future up to 01.2024.
Adaptive Precision Training (ADEPT): A dynamic fixed point quantized sparsifying training approach for DNNs
Aug 13, 2021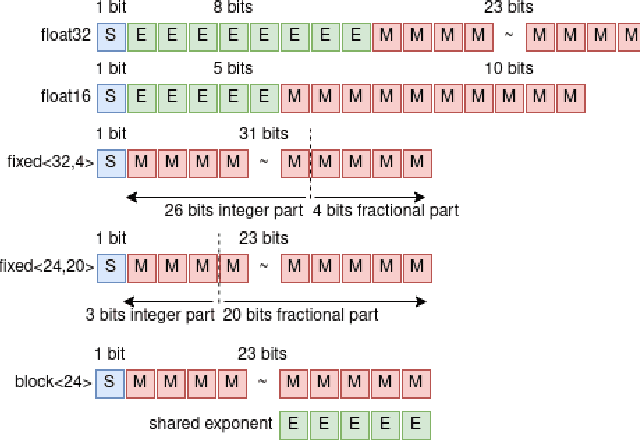
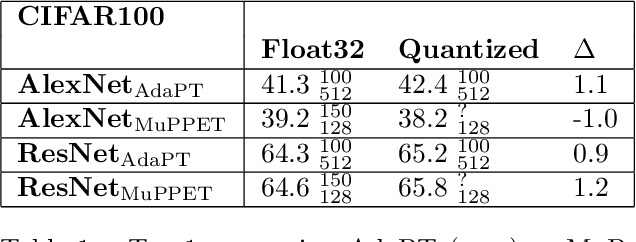

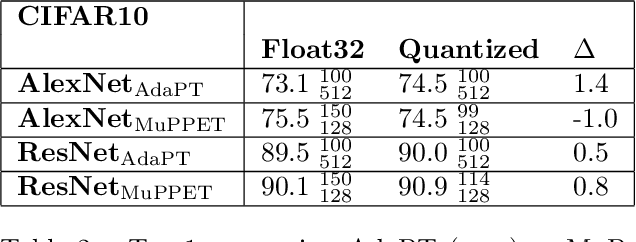
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Little work on quantized training exists and usually, existing approaches re-quire full precision refinement afterwards or enforce a global word length across the whole DNN. This leads to suboptimal bitwidth-to-layers assignments and re-source usage. Recognizing these limits, we introduce ADEPT, a new quantized sparsifying training strategy using information theory-based intra-epoch precision switching to find on a per-layer basis the lowest precision that causes no quantization-induced information loss while keeping precision high enough for future learning steps to not suffer from vanishing gradients, producing a fully quantized DNN. Based on a bitwidth-weighted MAdds performance model, our approach achieves an average speedup of 1.26 and model size reduction of 0.53 compared to standard training in float32 with an average accuracy increase of 0.98% on AlexNet/ResNet on CIFAR10/100.