 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATSal: An Attention Based Architecture for Saliency Prediction in 360 Videos
Nov 20, 2020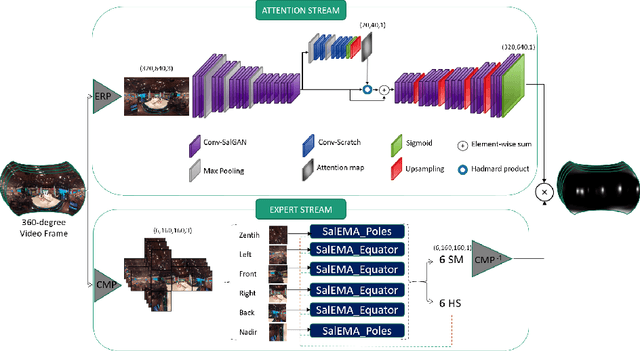

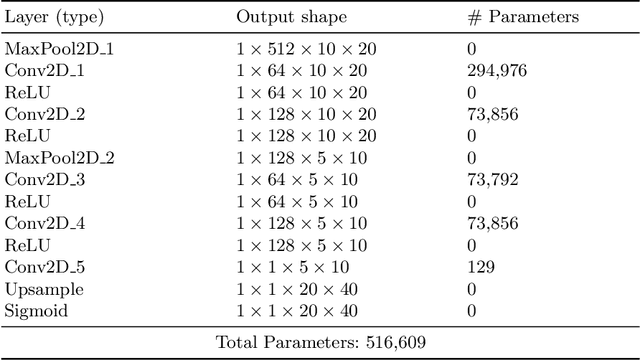

The spherical domain representation of 360 video/image presents many challenges related to the storage, processing, transmission and rendering of omnidirectional videos (ODV). Models of human visual attention can be used so that only a single viewport is rendered at a time, which is important when developing systems that allow users to explore ODV with head mounted displays (HMD). Accordingly, researchers have proposed various saliency models for 360 video/images. This paper proposes ATSal, a novel attention based (head-eye) saliency model for 360\degree videos. The attention mechanism explicitly encodes global static visual attention allowing expert models to focus on learning the saliency on local patches throughout consecutive frames. We compare the proposed approach to other state-of-the-art saliency models on two datasets: Salient360! and VR-EyeTracking. Experimental results on over 80 ODV videos (75K+ frames) show that the proposed method outperforms the existing state-of-the-art.
Unsupervised Contrastive Learning of Sound Event Representations
Nov 15, 2020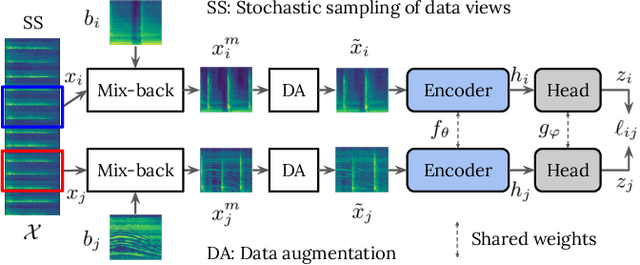

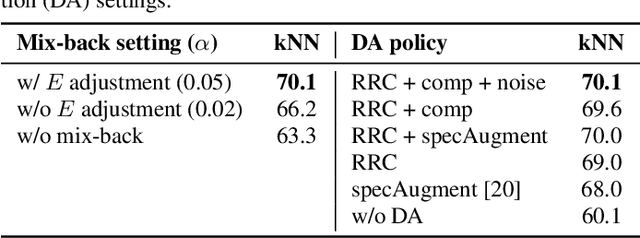
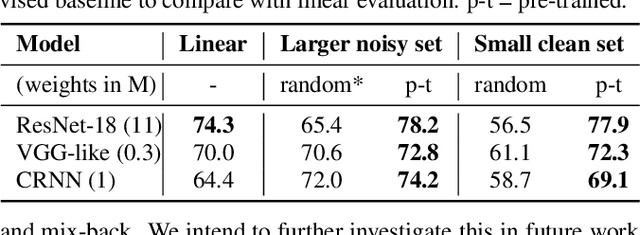
Self-supervised representation learning can mitigate the limitations in recognition tasks with few manually labeled data but abundant unlabeled data---a common scenario in sound event research. In this work, we explore unsupervised contrastive learning as a way to learn sound event representations. To this end, we propose to use the pretext task of contrasting differently augmented views of sound events. The views are computed primarily via mixing of training examples with unrelated backgrounds, followed by other data augmentations. We analyze the main components of our method via ablation experiments. We evaluate the learned representations using linear evaluation, and in two in-domain downstream sound event classification tasks, namely, using limited manually labeled data, and using noisy labeled data. Our results suggest that unsupervised contrastive pre-training can mitigate the impact of data scarcity and increase robustness against noisy labels, outperforming supervised baselines.
How important are faces for person re-identification?
Oct 13, 2020

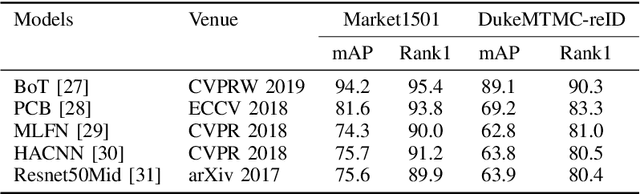

This paper investigates the dependence of existing state-of-the-art person re-identification models on the presence and visibility of human faces. We apply a face detection and blurring algorithm to create anonymized versions of several popular person re-identification datasets including Market1501, DukeMTMC-reID, CUHK03, Viper, and Airport. Using a cross-section of existing state-of-the-art models that range in accuracy and computational efficiency, we evaluate the effect of this anonymization on re-identification performance using standard metrics. Perhaps surprisingly, the effect on mAP is very small, and accuracy is recovered by simply training on the anonymized versions of the data rather than the original data. These findings are consistent across multiple models and datasets. These results indicate that datasets can be safely anonymized by blurring faces without significantly impacting the performance of person reidentification systems, and may allow for the release of new richer re-identification datasets where previously there were privacy or data protection concerns.
A Comparative Study of Existing and New Deep Learning Methods for Detecting Knee Injuries using the MRNet Dataset
Oct 05, 2020

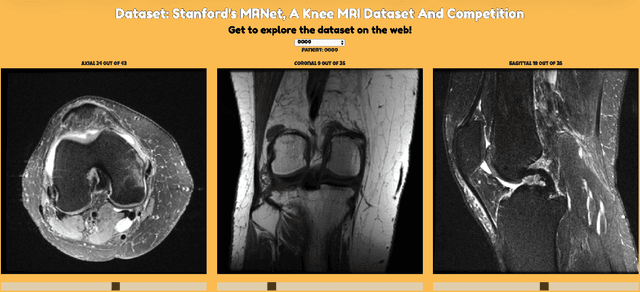
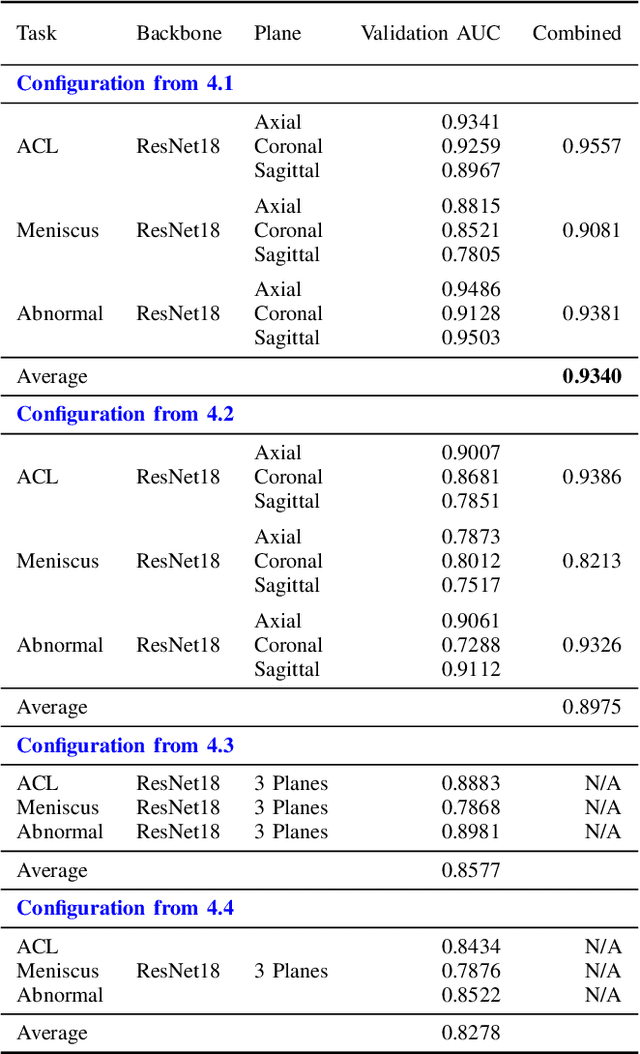
This work presents a comparative study of existing and new techniques to detect knee injuries by leveraging Stanford's MRNet Dataset. All approaches are based on deep learning and we explore the comparative performances of transfer learning and a deep residual network trained from scratch. We also exploit some characteristics of Magnetic Resonance Imaging (MRI) data by, for example, using a fixed number of slices or 2D images from each of the axial, coronal and sagittal planes as well as combining the three planes into one multi-plane network. Overall we achieved a performance of 93.4% AUC on the validation data by using the more recent deep learning architectures and data augmentation strategies. More flexible architectures are also proposed that might help with the development and training of models that process MRIs. We found that transfer learning and a carefully tuned data augmentation strategy were the crucial factors in determining best performance.
FastSal: a Computationally Efficient Network for Visual Saliency Prediction
Aug 25, 2020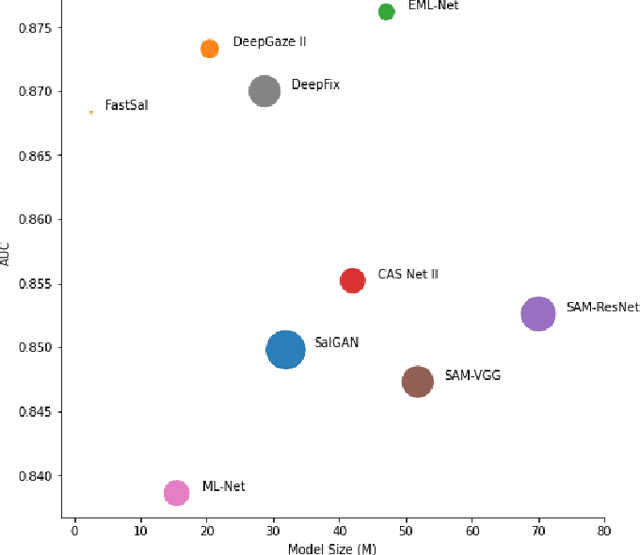
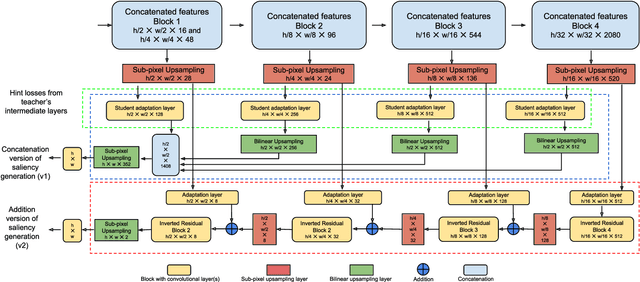
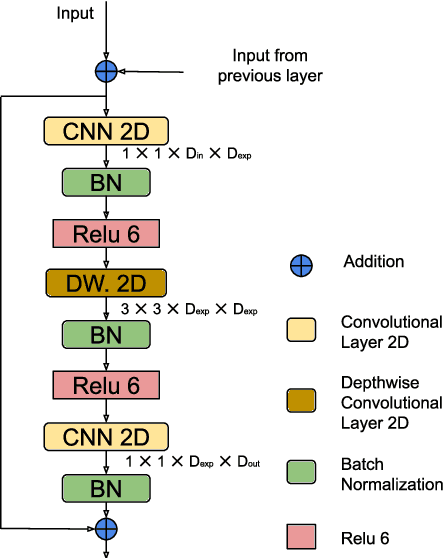
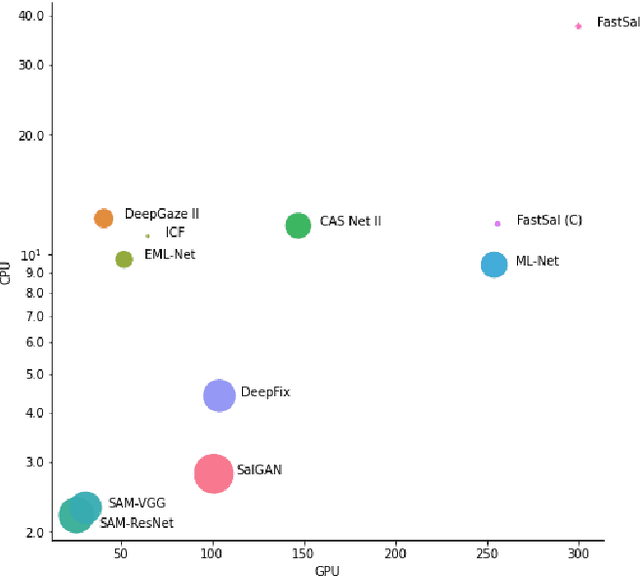
This paper focuses on the problem of visual saliency prediction, predicting regions of an image that tend to attract human visual attention, under a constrained computational budget. We modify and test various recent efficient convolutional neural network architectures like EfficientNet and MobileNetV2 and compare them with existing state-of-the-art saliency models such as SalGAN and DeepGaze II both in terms of standard accuracy metrics like AUC and NSS, and in terms of the computational complexity and model size. We find that MobileNetV2 makes an excellent backbone for a visual saliency model and can be effective even without a complex decoder. We also show that knowledge transfer from a more computationally expensive model like DeepGaze II can be achieved via pseudo-labelling an unlabelled dataset, and that this approach gives result on-par with many state-of-the-art algorithms with a fraction of the computational cost and model size. Source code is available at https://github.com/feiyanhu/FastSal.
ReLaB: Reliable Label Bootstrapping for Semi-Supervised Learning
Jul 23, 2020
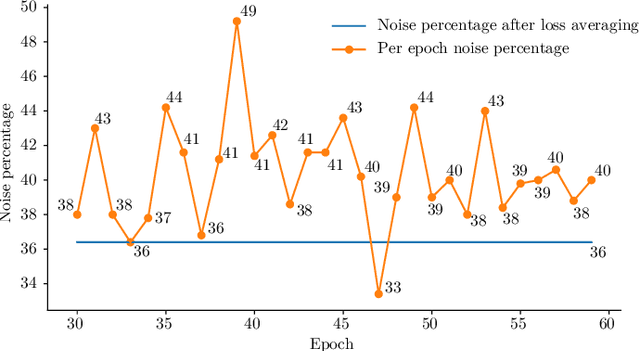

Reducing the amount of labels required to trainconvolutional neural networks without performance degradationis key to effectively reduce human annotation effort. We pro-pose Reliable Label Bootstrapping (ReLaB), an unsupervisedpreprossessing algorithm that paves the way for semi-supervisedlearning solutions, enabling them to work with much lowersupervision. Given a dataset with few labeled samples, we firstexploit a self-supervised learning algorithm to learn unsupervisedlatent features and then apply a label propagation algorithm onthese features and select only correctly labeled samples using alabel noise detection algorithm. This enables ReLaB to createa reliable extended labeled set from the initially few labeledsamples that can then be used for semi-supervised learning.We show that the selection of the network architecture andthe self-supervised method are important to achieve successfullabel propagation and demonstrate that ReLaB substantiallyimproves semi-supervised learning in scenarios of very lim-ited supervision in CIFAR-10, CIFAR-100, and mini-ImageNet. Code: https://github.com/PaulAlbert31/ReLaB.
Investigating Class-level Difficulty Factors in Multi-label Classification Problems
May 01, 2020

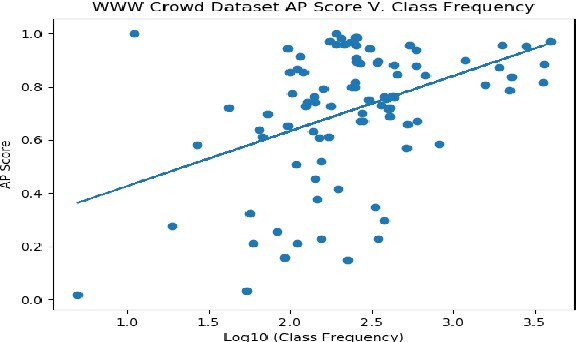

This work investigates the use of class-level difficulty factors in multi-label classification problems for the first time. Four class-level difficulty factors are proposed: frequency, visual variation, semantic abstraction, and class co-occurrence. Once computed for a given multi-label classification dataset, these difficulty factors are shown to have several potential applications including the prediction of class-level performance across datasets and the improvement of predictive performance through difficulty weighted optimisation. Significant improvements to mAP and AUC performance are observed for two challenging multi-label datasets (WWW Crowd and Visual Genome) with the inclusion of difficulty weighted optimisation. The proposed technique does not require any additional computational complexity during training or inference and can be extended over time with inclusion of other class-level difficulty factors.
Towards Robust Learning with Different Label Noise Distributions
Dec 18, 2019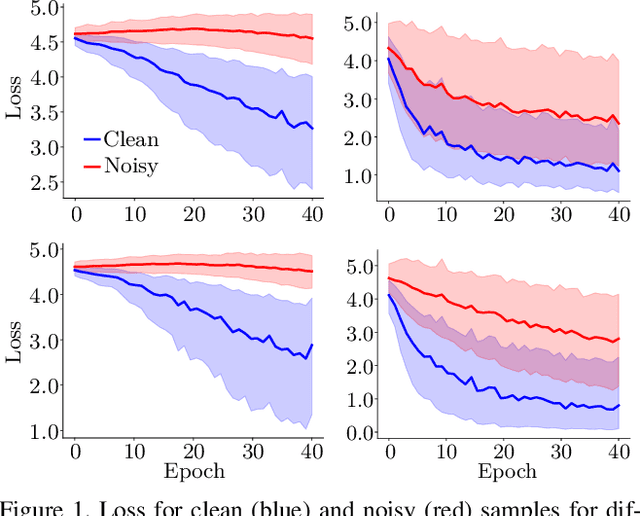

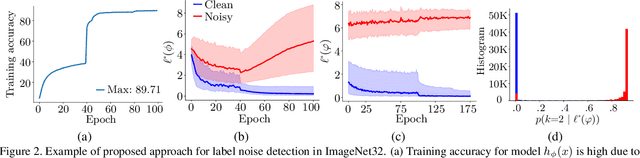
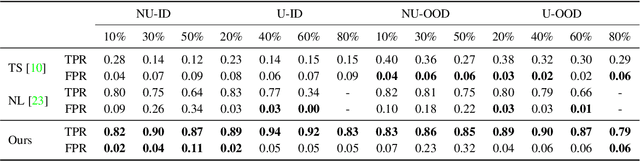
Noisy labels are an unavoidable consequence of automatic image labeling processes to reduce human supervision. Training in these conditions leads Convolutional Neural Networks to memorize label noise and degrade performance. Noisy labels are therefore dispensable, while image content can be exploited in a semi-supervised learning (SSL) setup. Handling label noise then becomes a label noise detection task. Noisy/clean samples are usually identified using the \textit{small loss trick}, which is based on the observation that clean samples represent easier patterns and, therefore, exhibit a lower loss. However, we show that different noise distributions make the application of this trick less straightforward. We propose to continuously relabel all images to reveal a loss that facilitates the use of the small loss trick with different noise distributions. SSL is then applied twice, once to improve the clean-noisy detection and again for training the final model. We design an experimental setup for better understanding the consequences of differing label noise distributions and find that non-uniform out-of-distribution noise better resembles real-world noise. We show that SSL outperforms other alternatives when using oracles and demonstrate substantial improvements across five datasets of our label noise Distribution Robust Pseudo-Labeling (DRPL). We further study the effects of label noise memorization via linear probes and find that in most cases intermediate features are not affected by label noise corruption. Code and details to reproduce our framework will be made available.
MediaEval 2019: Concealed FGSM Perturbations for Privacy Preservation
Oct 25, 2019
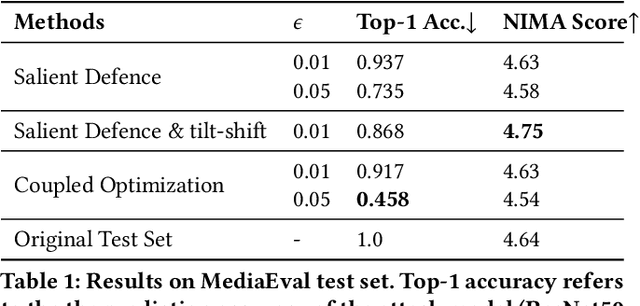
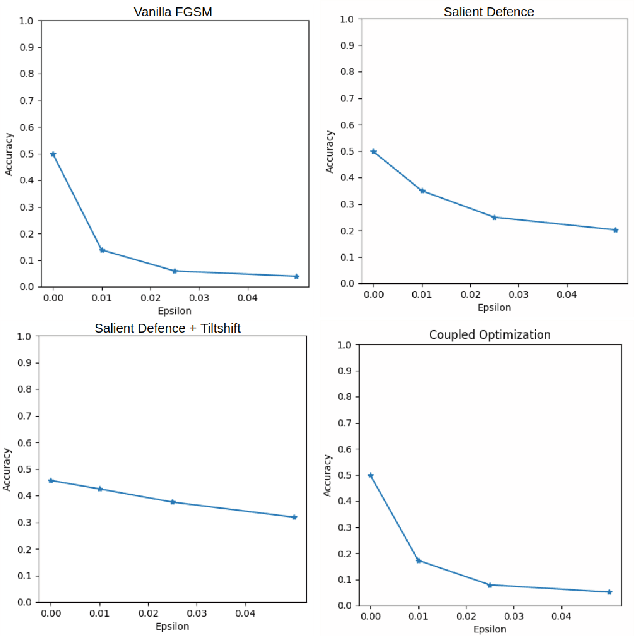

This work tackles the Pixel Privacy task put forth by MediaEval 2019. Our goal is to manipulate images in a way that conceals them from automatic scene classifiers while preserving the original image quality. We use the fast gradient sign method, which normally has a corrupting influence on image appeal, and devise two methods to minimize the damage. The first approach uses a map of pixel locations that are either salient or flat, and directs perturbations away from them. The second approach subtracts the gradient of an aesthetics evaluation model from the gradient of the attack model to guide the perturbations towards a direction that preserves appeal. We make our code available at: https://git.io/JesXr.
Predicting knee osteoarthritis severity: comparative modeling based on patient's data and plain X-ray images
Aug 23, 2019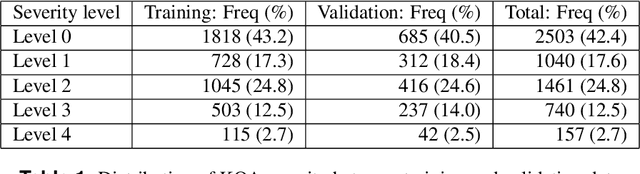
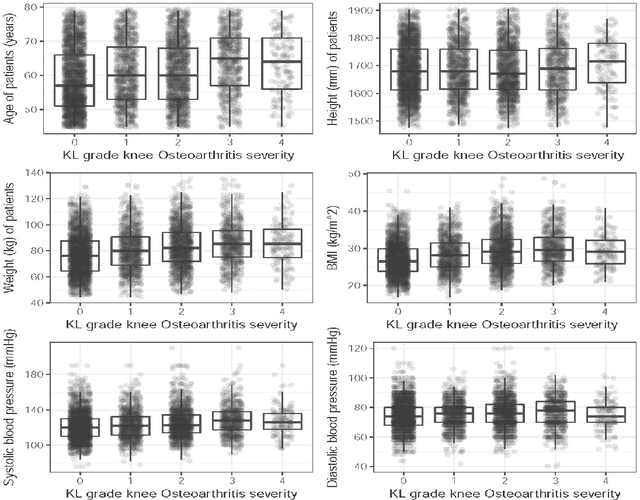
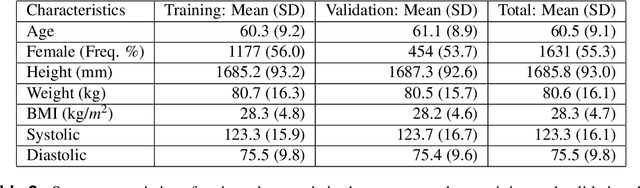
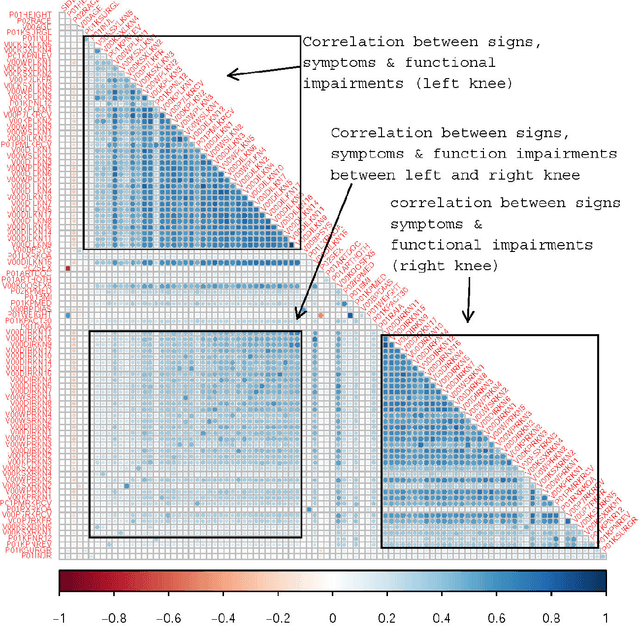
Knee osteoarthritis (KOA) is a disease that impairs knee function and causes pain. A radiologist reviews knee X-ray images and grades the severity level of the impairments according to the Kellgren and Lawrence grading scheme; a five-point ordinal scale (0--4). In this study, we used Elastic Net (EN) and Random Forests (RF) to build predictive models using patient assessment data (i.e. signs and symptoms of both knees and medication use) and a convolution neural network (CNN) trained using X-ray images only. Linear mixed effect models (LMM) were used to model the within subject correlation between the two knees. The root mean squared error for the CNN, EN, and RF models was 0.77, 0.97, and 0.94 respectively. The LMM shows similar overall prediction accuracy as the EN regression but correctly accounted for the hierarchical structure of the data resulting in more reliable inference. Useful explanatory variables were identified that could be used for patient monitoring before X-ray imaging. Our analyses suggest that the models trained for predicting the KOA severity levels achieve comparable results when modeling X-ray images and patient data. The subjectivity in the KL grade is still a primary concern.
* Published in Nature Scientific Reports, 2019