 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Methods for Detecting Adversarial Images
Mar 23, 2017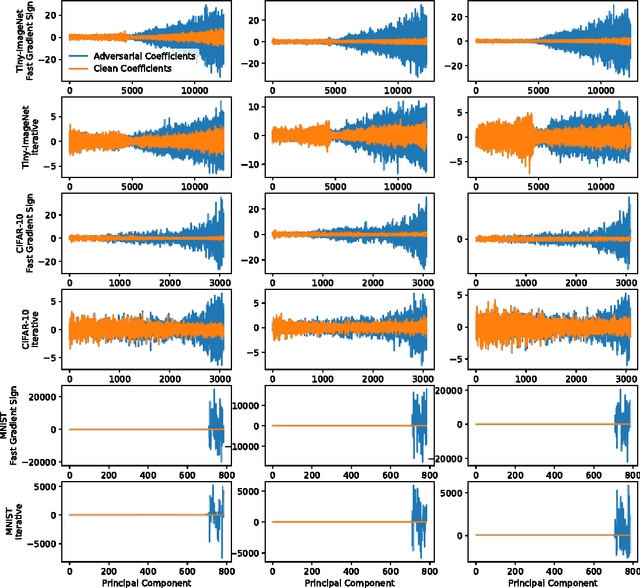



Many machine learning classifiers are vulnerable to adversarial perturbations. An adversarial perturbation modifies an input to change a classifier's prediction without causing the input to seem substantially different to human perception. We deploy three methods to detect adversarial images. Adversaries trying to bypass our detectors must make the adversarial image less pathological or they will fail trying. Our best detection method reveals that adversarial images place abnormal emphasis on the lower-ranked principal components from PCA. Other detectors and a colorful saliency map are in an appendix.
Broad Context Language Modeling as Reading Comprehension
Feb 16, 2017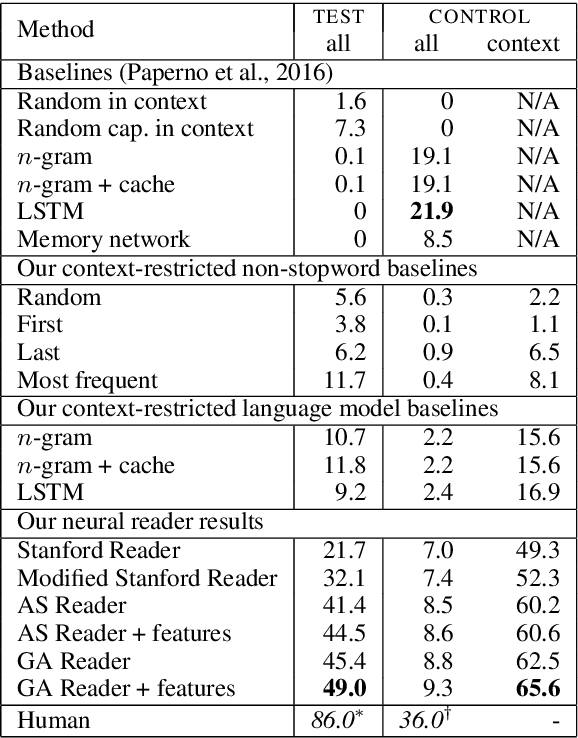
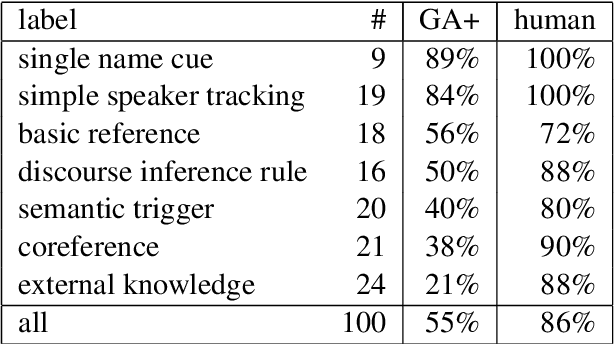
Progress in text understanding has been driven by large datasets that test particular capabilities, like recent datasets for reading comprehension (Hermann et al., 2015). We focus here on the LAMBADA dataset (Paperno et al., 2016), a word prediction task requiring broader context than the immediate sentence. We view LAMBADA as a reading comprehension problem and apply comprehension models based on neural networks. Though these models are constrained to choose a word from the context, they improve the state of the art on LAMBADA from 7.3% to 49%. We analyze 100 instances, finding that neural network readers perform well in cases that involve selecting a name from the context based on dialogue or discourse cues but struggle when coreference resolution or external knowledge is needed.
End-to-End Training Approaches for Discriminative Segmental Models
Oct 21, 2016

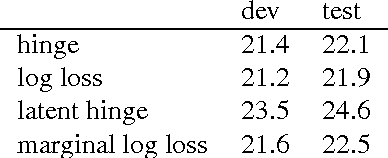
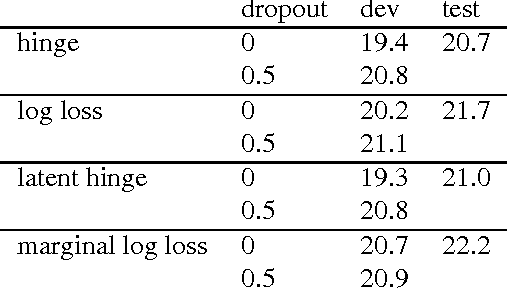
Recent work on discriminative segmental models has shown that they can achieve competitive speech recognition performance, using features based on deep neural frame classifiers. However, segmental models can be more challenging to train than standard frame-based approaches. While some segmental models have been successfully trained end to end, there is a lack of understanding of their training under different settings and with different losses. We investigate a model class based on recent successful approaches, consisting of a linear model that combines segmental features based on an LSTM frame classifier. Similarly to hybrid HMM-neural network models, segmental models of this class can be trained in two stages (frame classifier training followed by linear segmental model weight training), end to end (joint training of both frame classifier and linear weights), or with end-to-end fine-tuning after two-stage training. We study segmental models trained end to end with hinge loss, log loss, latent hinge loss, and marginal log loss. We consider several losses for the case where training alignments are available as well as where they are not. We find that in general, marginal log loss provides the most consistent strong performance without requiring ground-truth alignments. We also find that training with dropout is very important in obtaining good performance with end-to-end training. Finally, the best results are typically obtained by a combination of two-stage training and fine-tuning.
Who did What: A Large-Scale Person-Centered Cloze Dataset
Aug 19, 2016
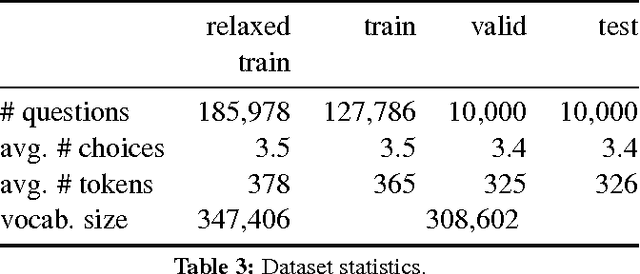
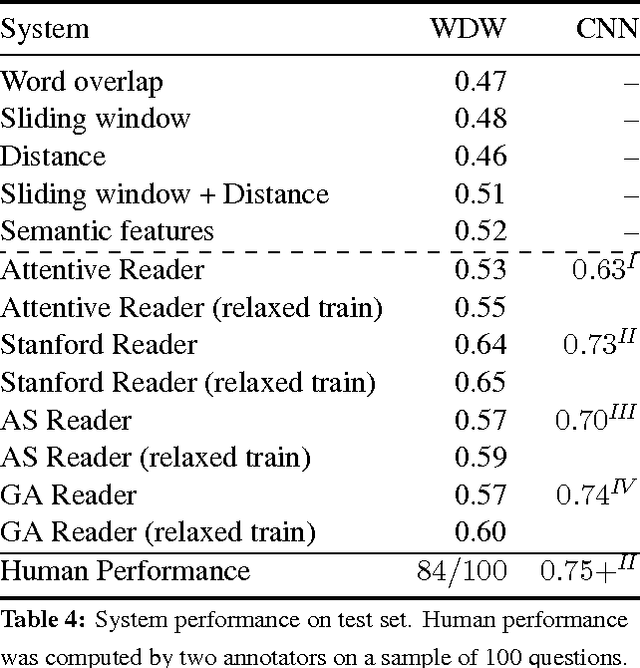
We have constructed a new "Who-did-What" dataset of over 200,000 fill-in-the-gap (cloze) multiple choice reading comprehension problems constructed from the LDC English Gigaword newswire corpus. The WDW dataset has a variety of novel features. First, in contrast with the CNN and Daily Mail datasets (Hermann et al., 2015) we avoid using article summaries for question formation. Instead, each problem is formed from two independent articles --- an article given as the passage to be read and a separate article on the same events used to form the question. Second, we avoid anonymization --- each choice is a person named entity. Third, the problems have been filtered to remove a fraction that are easily solved by simple baselines, while remaining 84% solvable by humans. We report performance benchmarks of standard systems and propose the WDW dataset as a challenge task for the community.
Discriminative Segmental Cascades for Feature-Rich Phone Recognition
Aug 04, 2016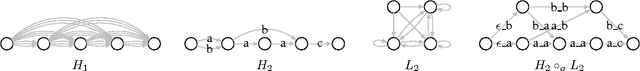
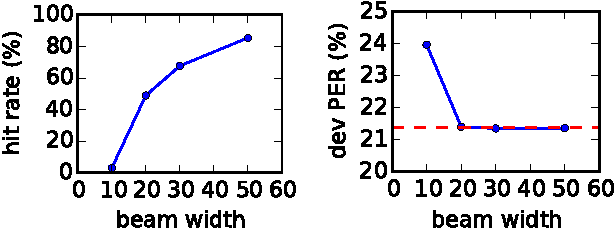

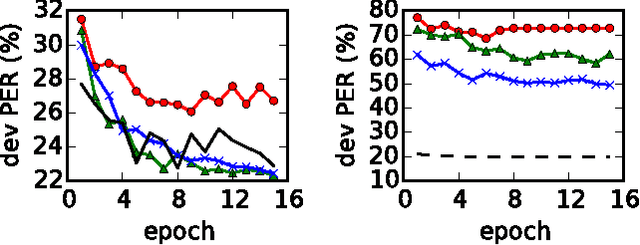
Discriminative segmental models, such as segmental conditional random fields (SCRFs) and segmental structured support vector machines (SSVMs), have had success in speech recognition via both lattice rescoring and first-pass decoding. However, such models suffer from slow decoding, hampering the use of computationally expensive features, such as segment neural networks or other high-order features. A typical solution is to use approximate decoding, either by beam pruning in a single pass or by beam pruning to generate a lattice followed by a second pass. In this work, we study discriminative segmental models trained with a hinge loss (i.e., segmental structured SVMs). We show that beam search is not suitable for learning rescoring models in this approach, though it gives good approximate decoding performance when the model is already well-trained. Instead, we consider an approach inspired by structured prediction cascades, which use max-marginal pruning to generate lattices. We obtain a high-accuracy phonetic recognition system with several expensive feature types: a segment neural network, a second-order language model, and second-order phone boundary features.
Efficient Segmental Cascades for Speech Recognition
Aug 02, 2016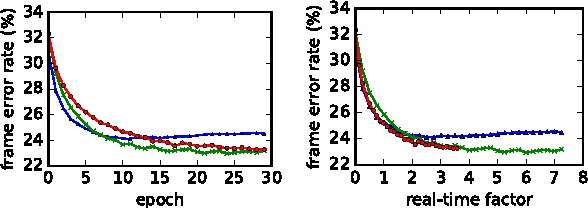

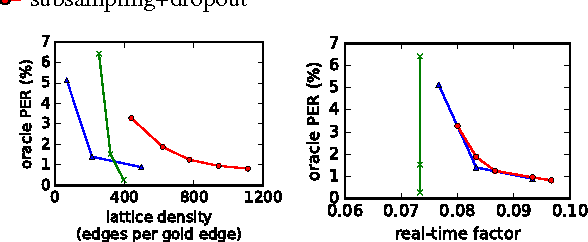

Discriminative segmental models offer a way to incorporate flexible feature functions into speech recognition. However, their appeal has been limited by their computational requirements, due to the large number of possible segments to consider. Multi-pass cascades of segmental models introduce features of increasing complexity in different passes, where in each pass a segmental model rescores lattices produced by a previous (simpler) segmental model. In this paper, we explore several ways of making segmental cascades efficient and practical: reducing the feature set in the first pass, frame subsampling, and various pruning approaches. In experiments on phonetic recognition, we find that with a combination of such techniques, it is possible to maintain competitive performance while greatly reducing decoding, pruning, and training time.
Charagram: Embedding Words and Sentences via Character n-grams
Jul 10, 2016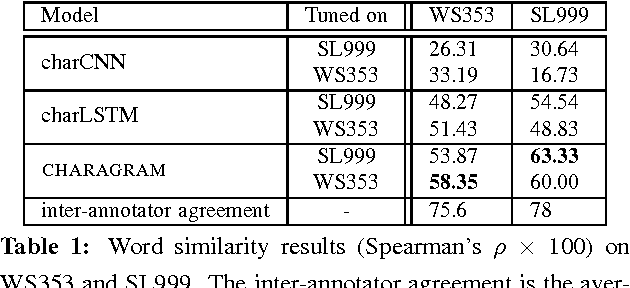
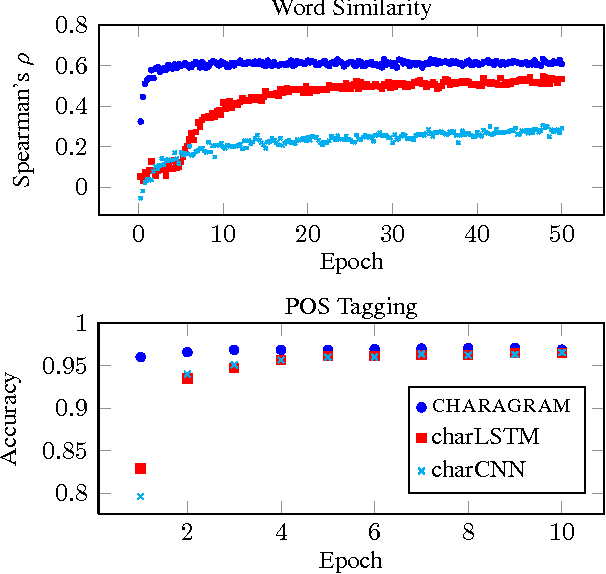

We present Charagram embeddings, a simple approach for learning character-based compositional models to embed textual sequences. A word or sentence is represented using a character n-gram count vector, followed by a single nonlinear transformation to yield a low-dimensional embedding. We use three tasks for evaluation: word similarity, sentence similarity, and part-of-speech tagging. We demonstrate that Charagram embeddings outperform more complex architectures based on character-level recurrent and convolutional neural networks, achieving new state-of-the-art performance on several similarity tasks.
Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units
Jul 08, 2016



We propose the Gaussian Error Linear Unit (GELU), a high-performing neural network activation function. The GELU nonlinearity is the expected transformation of a stochastic regularizer which randomly applies the identity or zero map, combining the intuitions of dropout and zoneout while respecting neuron values. This connection suggests a new probabilistic understanding of nonlinearities. We perform an empirical evaluation of the GELU nonlinearity against the ReLU and ELU activations and find performance improvements across all tasks.
Mapping Unseen Words to Task-Trained Embedding Spaces
Jun 23, 2016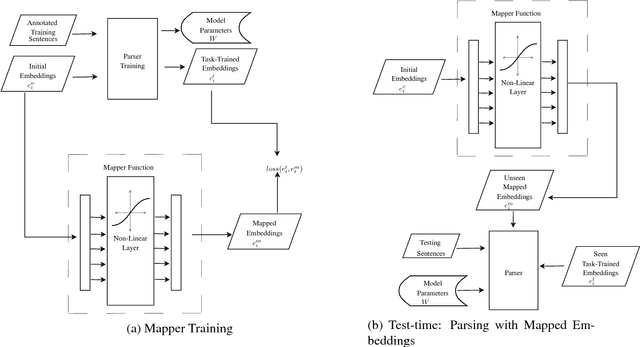
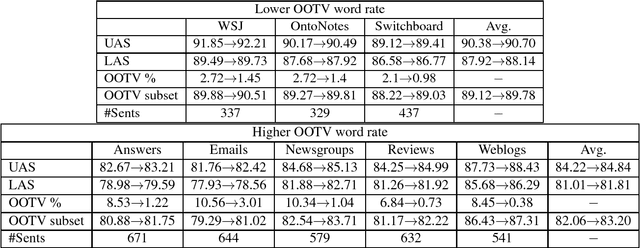
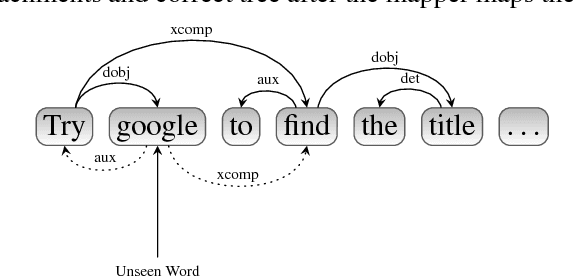
We consider the supervised training setting in which we learn task-specific word embeddings. We assume that we start with initial embeddings learned from unlabelled data and update them to learn task-specific embeddings for words in the supervised training data. However, for new words in the test set, we must use either their initial embeddings or a single unknown embedding, which often leads to errors. We address this by learning a neural network to map from initial embeddings to the task-specific embedding space, via a multi-loss objective function. The technique is general, but here we demonstrate its use for improved dependency parsing (especially for sentences with out-of-vocabulary words), as well as for downstream improvements on sentiment analysis.
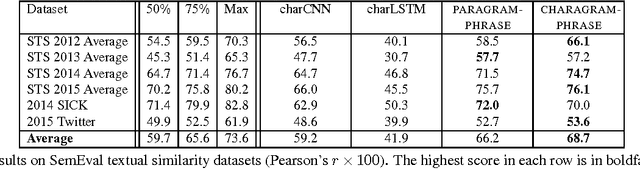
Towards Universal Paraphrastic Sentence Embeddings
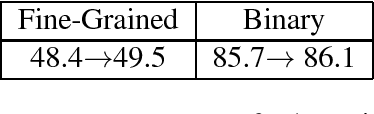
Mar 04, 2016
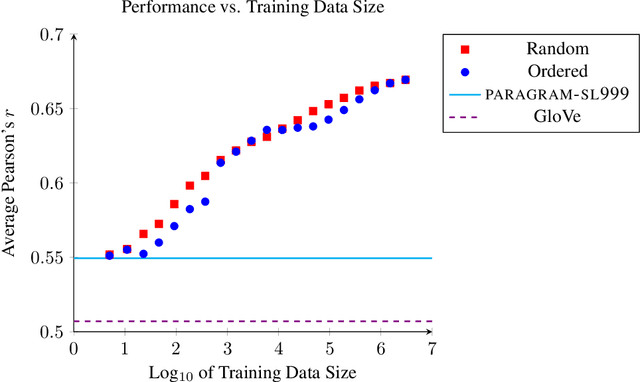
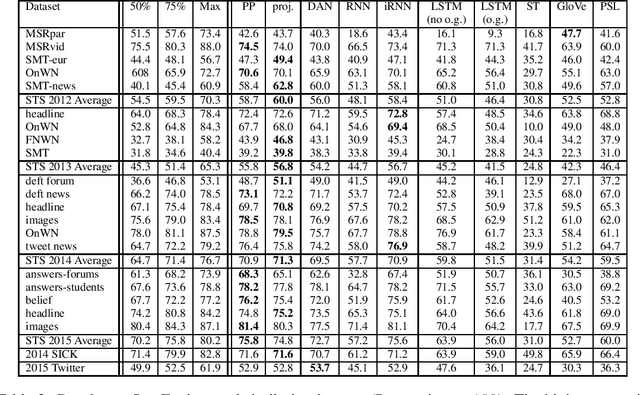
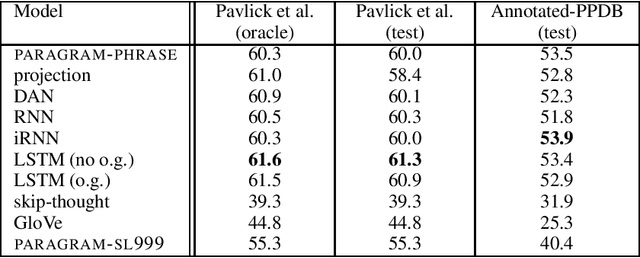
We consider the problem of learning general-purpose, paraphrastic sentence embeddings based on supervision from the Paraphrase Database (Ganitkevitch et al., 2013). We compare six compositional architectures, evaluating them on annotated textual similarity datasets drawn both from the same distribution as the training data and from a wide range of other domains. We find that the most complex architectures, such as long short-term memory (LSTM) recurrent neural networks, perform best on the in-domain data. However, in out-of-domain scenarios, simple architectures such as word averaging vastly outperform LSTMs. Our simplest averaging model is even competitive with systems tuned for the particular tasks while also being extremely efficient and easy to use. In order to better understand how these architectures compare, we conduct further experiments on three supervised NLP tasks: sentence similarity, entailment, and sentiment classification. We again find that the word averaging models perform well for sentence similarity and entailment, outperforming LSTMs. However, on sentiment classification, we find that the LSTM performs very strongly-even recording new state-of-the-art performance on the Stanford Sentiment Treebank. We then demonstrate how to combine our pretrained sentence embeddings with these supervised tasks, using them both as a prior and as a black box feature extractor. This leads to performance rivaling the state of the art on the SICK similarity and entailment tasks. We release all of our resources to the research community with the hope that they can serve as the new baseline for further work on universal sentence embeddings.