 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmaller Text Classifiers with Discriminative Cluster Embeddings
Jun 23, 2019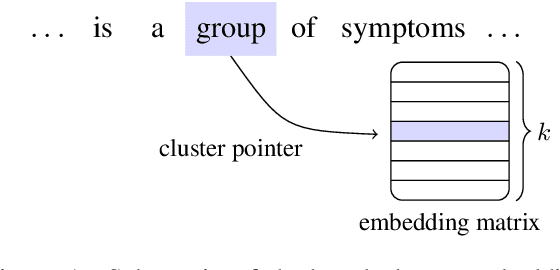
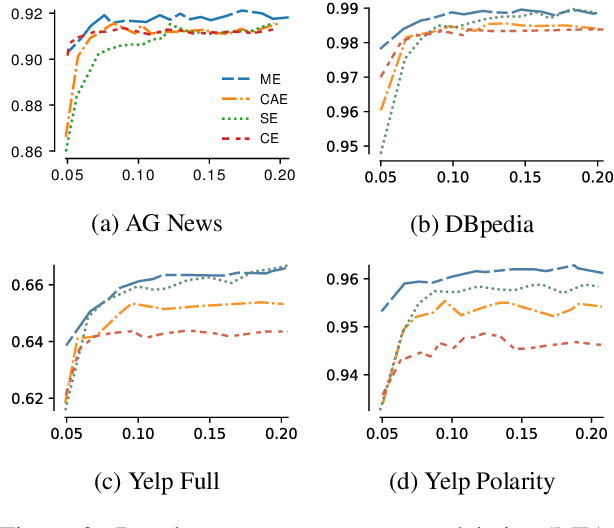
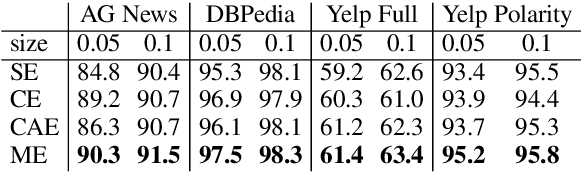
Word embedding parameters often dominate overall model sizes in neural methods for natural language processing. We reduce deployed model sizes of text classifiers by learning a hard word clustering in an end-to-end manner. We use the Gumbel-Softmax distribution to maximize over the latent clustering while minimizing the task loss. We propose variations that selectively assign additional parameters to words, which further improves accuracy while still remaining parameter-efficient.
Visually Grounded Neural Syntax Acquisition
Jun 07, 2019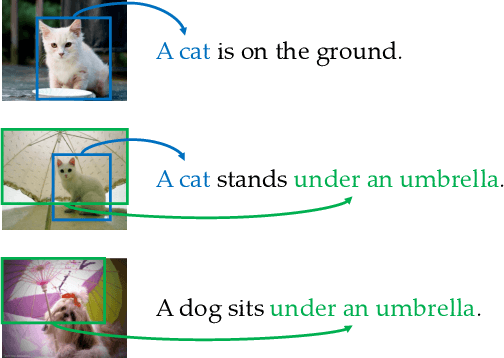
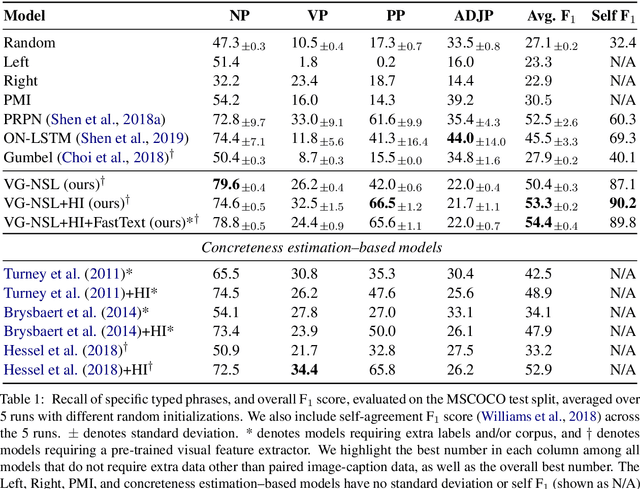
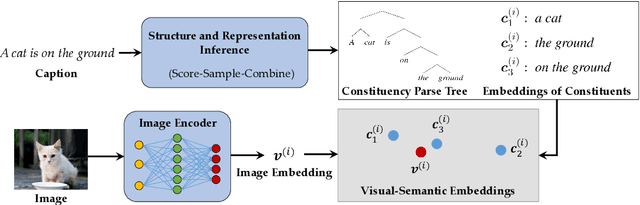
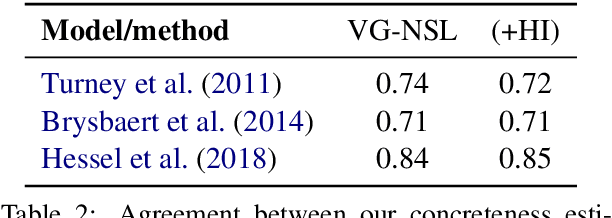
We present the Visually Grounded Neural Syntax Learner (VG-NSL), an approach for learning syntactic representations and structures without any explicit supervision. The model learns by looking at natural images and reading paired captions. VG-NSL generates constituency parse trees of texts, recursively composes representations for constituents, and matches them with images. We define concreteness of constituents by their matching scores with images, and use it to guide the parsing of text. Experiments on the MSCOCO data set show that VG-NSL outperforms various unsupervised parsing approaches that do not use visual grounding, in terms of F1 scores against gold parse trees. We find that VGNSL is much more stable with respect to the choice of random initialization and the amount of training data. We also find that the concreteness acquired by VG-NSL correlates well with a similar measure defined by linguists. Finally, we also apply VG-NSL to multiple languages in the Multi30K data set, showing that our model consistently outperforms prior unsupervised approaches.
Controllable Paraphrase Generation with a Syntactic Exemplar
Jun 03, 2019
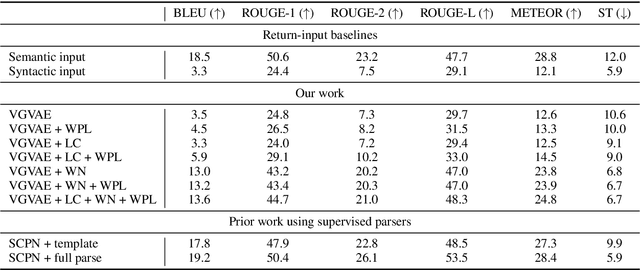
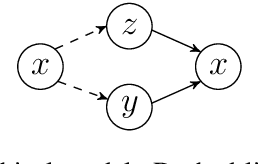
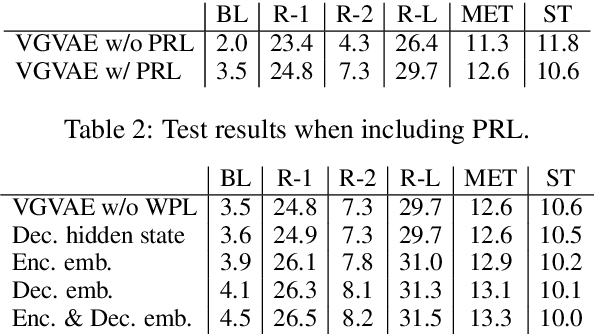
Prior work on controllable text generation usually assumes that the controlled attribute can take on one of a small set of values known a priori. In this work, we propose a novel task, where the syntax of a generated sentence is controlled rather by a sentential exemplar. To evaluate quantitatively with standard metrics, we create a novel dataset with human annotations. We also develop a variational model with a neural module specifically designed for capturing syntactic knowledge and several multitask training objectives to promote disentangled representation learning. Empirically, the proposed model is observed to achieve improvements over baselines and learn to capture desirable characteristics.
PoMo: Generating Entity-Specific Post-Modifiers in Context
Apr 08, 2019
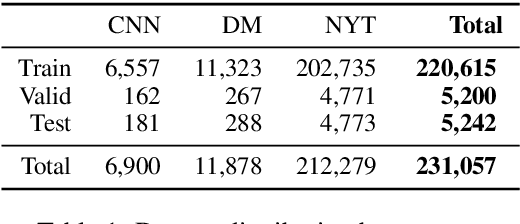

We introduce entity post-modifier generation as an instance of a collaborative writing task. Given a sentence about a target entity, the task is to automatically generate a post-modifier phrase that provides contextually relevant information about the entity. For example, for the sentence, "Barack Obama, _______, supported the #MeToo movement.", the phrase "a father of two girls" is a contextually relevant post-modifier. To this end, we build PoMo, a post-modifier dataset created automatically from news articles reflecting a journalistic need for incorporating entity information that is relevant to a particular news event. PoMo consists of more than 231K sentences with post-modifiers and associated facts extracted from Wikidata for around 57K unique entities. We use crowdsourcing to show that modeling contextual relevance is necessary for accurate post-modifier generation. We adapt a number of existing generation approaches as baselines for this dataset. Our results show there is large room for improvement in terms of both identifying relevant facts to include (knowing which claims are relevant gives a >20% improvement in BLEU score), and generating appropriate post-modifier text for the context (providing relevant claims is not sufficient for accurate generation). We conduct an error analysis that suggests promising directions for future research.
A Multi-Task Approach for Disentangling Syntax and Semantics in Sentence Representations
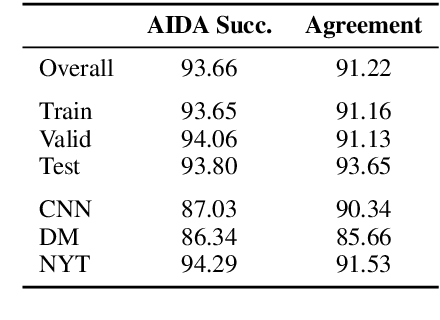
Apr 02, 2019
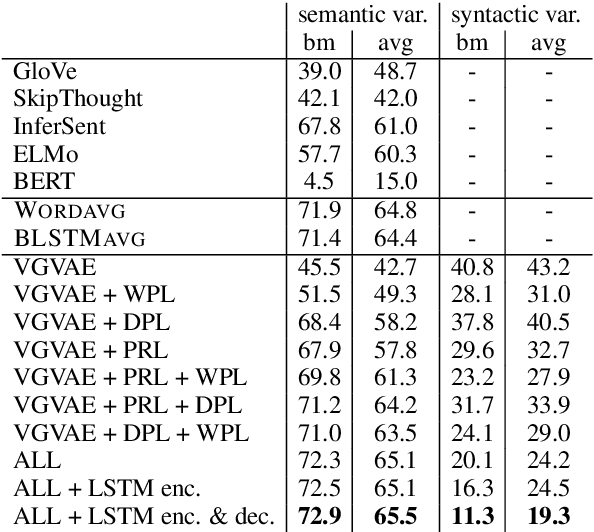
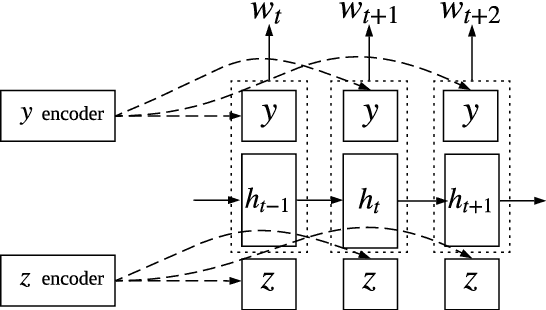
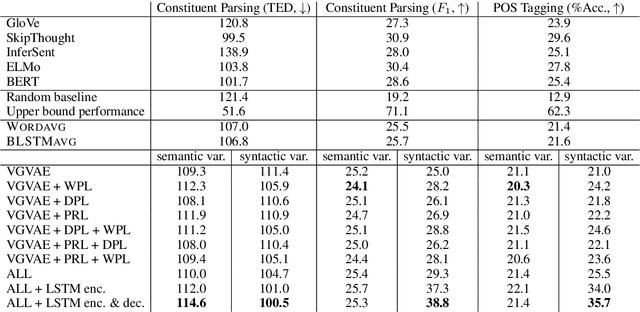
We propose a generative model for a sentence that uses two latent variables, with one intended to represent the syntax of the sentence and the other to represent its semantics. We show we can achieve better disentanglement between semantic and syntactic representations by training with multiple losses, including losses that exploit aligned paraphrastic sentences and word-order information. We also investigate the effect of moving from bag-of-words to recurrent neural network modules. We evaluate our models as well as several popular pretrained embeddings on standard semantic similarity tasks and novel syntactic similarity tasks. Empirically, we find that the model with the best performing syntactic and semantic representations also gives rise to the most disentangled representations.
* NAACL 2019 Long paper
Benchmarking Approximate Inference Methods for Neural Structured Prediction
Apr 01, 2019
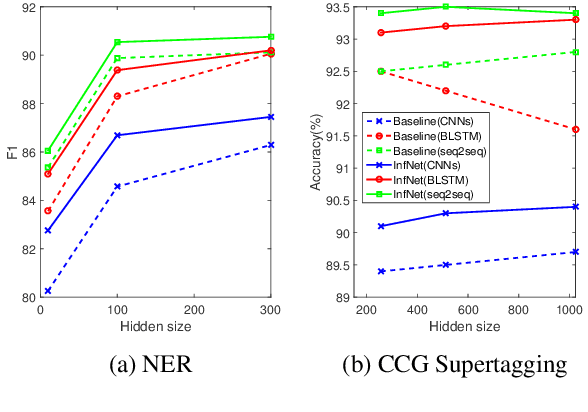
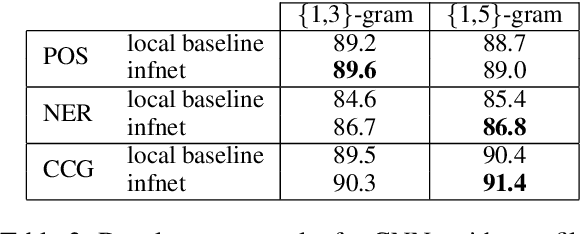
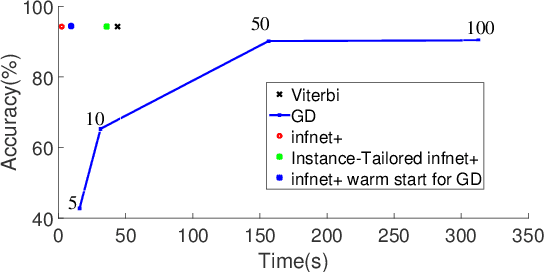
Exact structured inference with neural network scoring functions is computationally challenging but several methods have been proposed for approximating inference. One approach is to perform gradient descent with respect to the output structure directly (Belanger and McCallum, 2016). Another approach, proposed recently, is to train a neural network (an "inference network") to perform inference (Tu and Gimpel, 2018). In this paper, we compare these two families of inference methods on three sequence labeling datasets. We choose sequence labeling because it permits us to use exact inference as a benchmark in terms of speed, accuracy, and search error. Across datasets, we demonstrate that inference networks achieve a better speed/accuracy/search error trade-off than gradient descent, while also being faster than exact inference at similar accuracy levels. We find further benefit by combining inference networks and gradient descent, using the former to provide a warm start for the latter.
Using Trusted Data to Train Deep Networks on Labels Corrupted by Severe Noise
Oct 30, 2018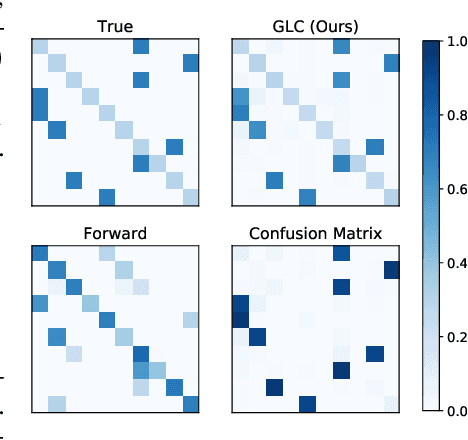
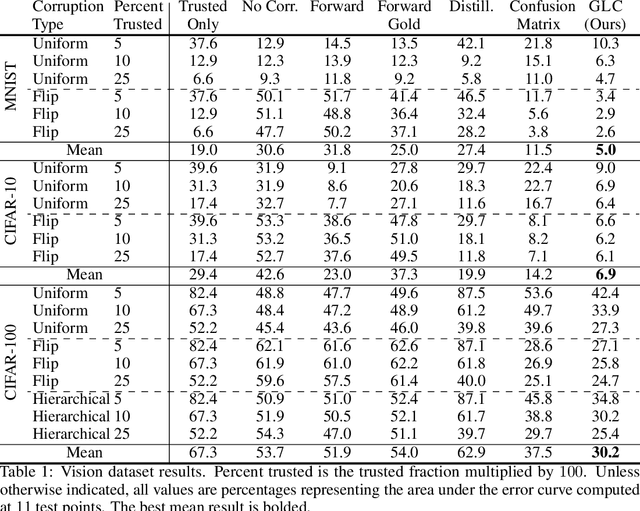
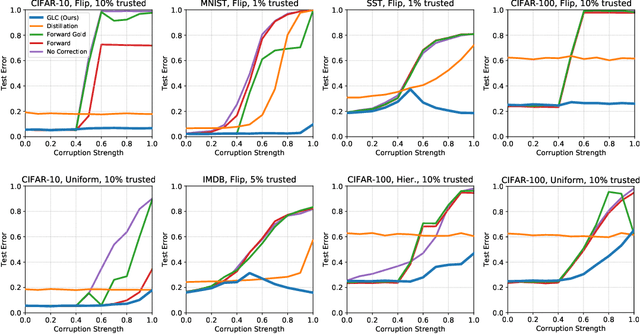
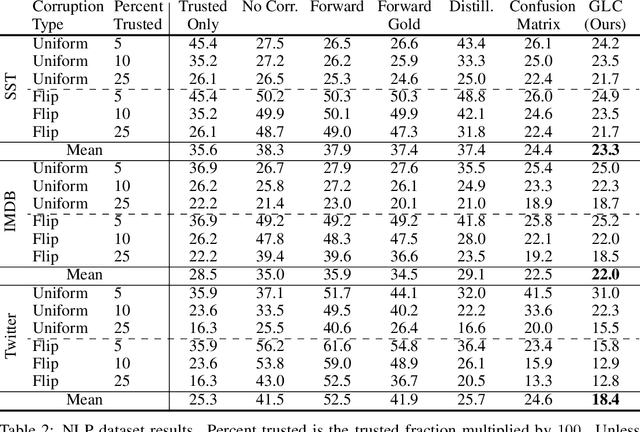
The growing importance of massive datasets with the advent of deep learning makes robustness to label noise a critical property for classifiers to have. Sources of label noise include automatic labeling for large datasets, non-expert labeling, and label corruption by data poisoning adversaries. In the latter case, corruptions may be arbitrarily bad, even so bad that a classifier predicts the wrong labels with high confidence. To protect against such sources of noise, we leverage the fact that a small set of clean labels is often easy to procure. We demonstrate that robustness to label noise up to severe strengths can be achieved by using a set of trusted data with clean labels, and propose a loss correction that utilizes trusted examples in a data-efficient manner to mitigate the effects of label noise on deep neural network classifiers. Across vision and natural language processing tasks, we experiment with various label noises at several strengths, and show that our method significantly outperforms existing methods.
Learning Criteria and Evaluation Metrics for Textual Transfer between Non-Parallel Corpora
Oct 28, 2018
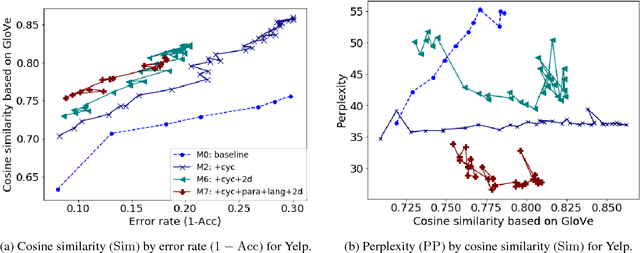
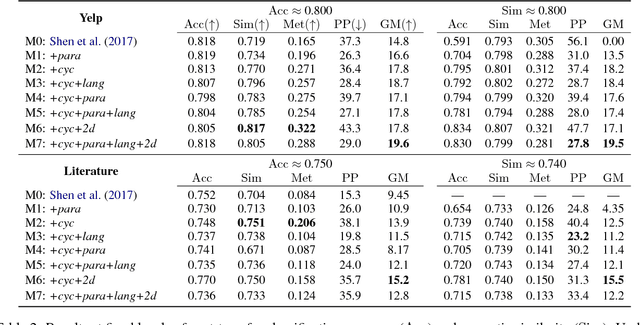
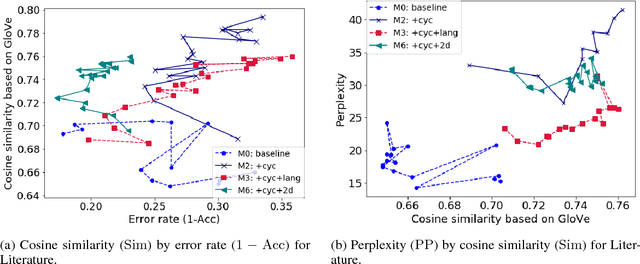
We consider the problem of automatically generating textual paraphrases with modified attributes or stylistic properties, focusing on the setting without parallel data (Hu et al., 2017; Shen et al., 2017). This setting poses challenges for learning and evaluation. We show that the metric of post-transfer classification accuracy is insufficient on its own, and propose additional metrics based on semantic content preservation and fluency. For reliable evaluation, all three metric categories must be taken into account. We contribute new loss functions and training strategies to address the new metrics. Semantic preservation is addressed by adding a cyclic consistency loss and a loss based on paraphrase pairs, while fluency is improved by integrating losses based on style-specific language models. Automatic and manual evaluation show large improvements over the baseline method of Shen et al. (2017). Our hope is that these losses and metrics can be general and useful tools for a range of textual transfer settings without parallel corpora.
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Oct 03, 2018
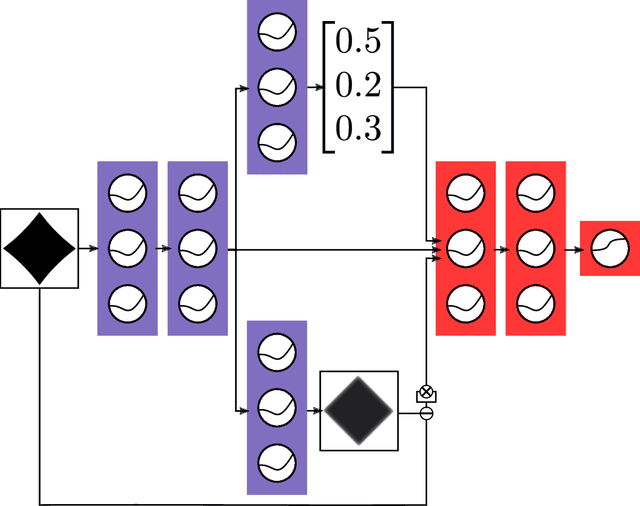
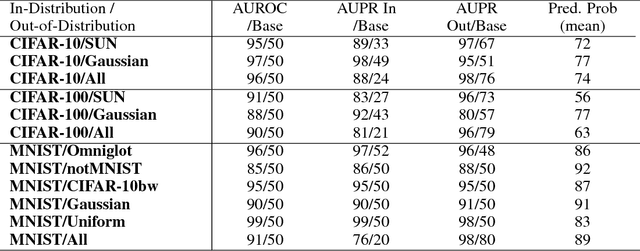

We consider the two related problems of detecting if an example is misclassified or out-of-distribution. We present a simple baseline that utilizes probabilities from softmax distributions. Correctly classified examples tend to have greater maximum softmax probabilities than erroneously classified and out-of-distribution examples, allowing for their detection. We assess performance by defining several tasks in computer vision, natural language processing, and automatic speech recognition, showing the effectiveness of this baseline across all. We then show the baseline can sometimes be surpassed, demonstrating the room for future research on these underexplored detection tasks.
* Published as a conference paper at ICLR 2017. 1 Figure in 1 Appendix. Minor changes from the previous version
ParaNMT-50M: Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations
Apr 20, 2018

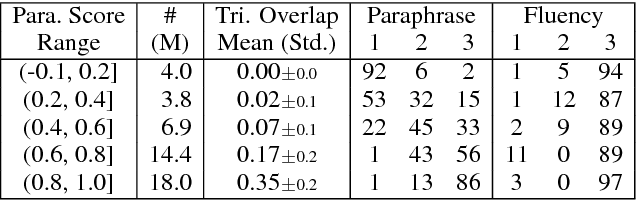
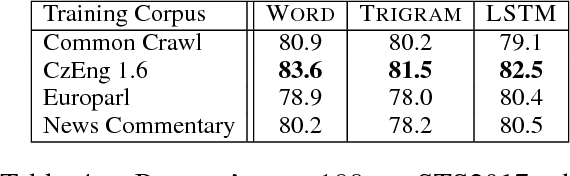
We describe PARANMT-50M, a dataset of more than 50 million English-English sentential paraphrase pairs. We generated the pairs automatically by using neural machine translation to translate the non-English side of a large parallel corpus, following Wieting et al. (2017). Our hope is that ParaNMT-50M can be a valuable resource for paraphrase generation and can provide a rich source of semantic knowledge to improve downstream natural language understanding tasks. To show its utility, we use ParaNMT-50M to train paraphrastic sentence embeddings that outperform all supervised systems on every SemEval semantic textual similarity competition, in addition to showing how it can be used for paraphrase generation.