 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Supervision in Unsupervised Constituency Parsing
Oct 07, 2020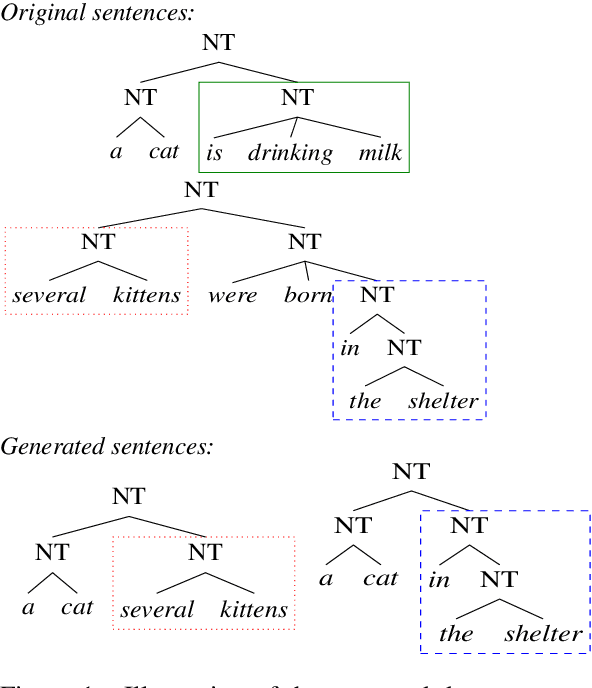
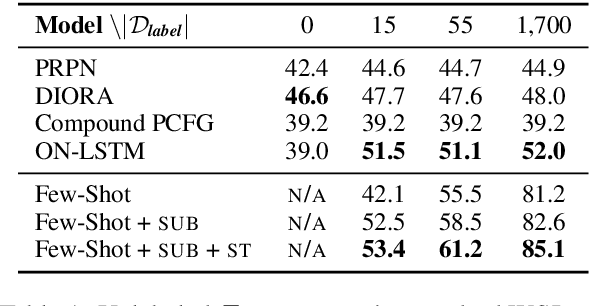
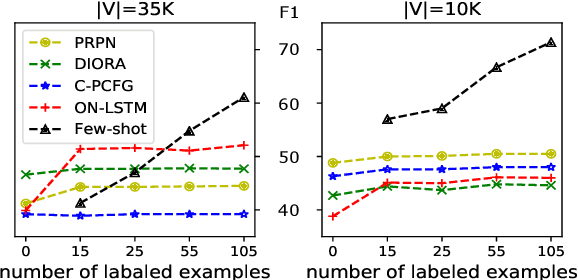
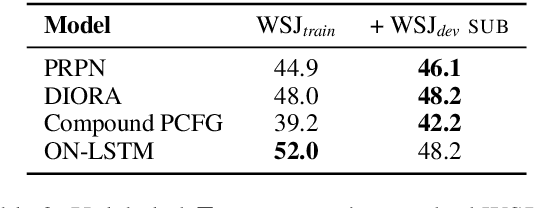
We analyze several recent unsupervised constituency parsing models, which are tuned with respect to the parsing $F_1$ score on the Wall Street Journal (WSJ) development set (1,700 sentences). We introduce strong baselines for them, by training an existing supervised parsing model (Kitaev and Klein, 2018) on the same labeled examples they access. When training on the 1,700 examples, or even when using only 50 examples for training and 5 for development, such a few-shot parsing approach can outperform all the unsupervised parsing methods by a significant margin. Few-shot parsing can be further improved by a simple data augmentation method and self-training. This suggests that, in order to arrive at fair conclusions, we should carefully consider the amount of labeled data used for model development. We propose two protocols for future work on unsupervised parsing: (i) use fully unsupervised criteria for hyperparameter tuning and model selection; (ii) use as few labeled examples as possible for model development, and compare to few-shot parsing trained on the same labeled examples.
Learning to Ignore: Long Document Coreference with Bounded Memory Neural Networks
Oct 06, 2020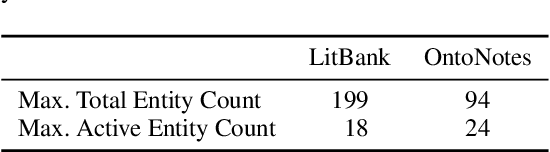
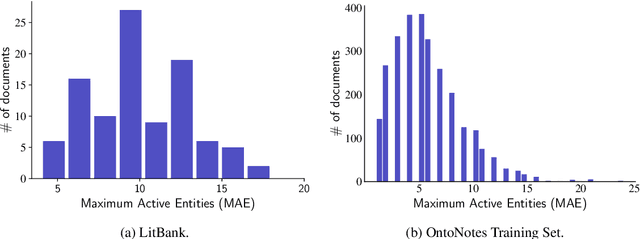
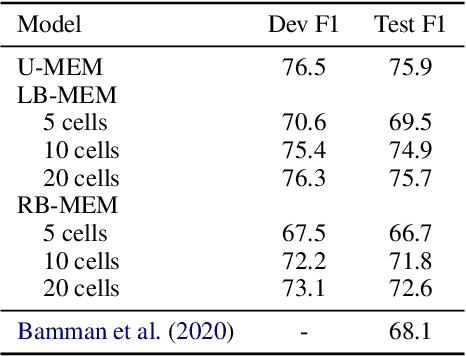
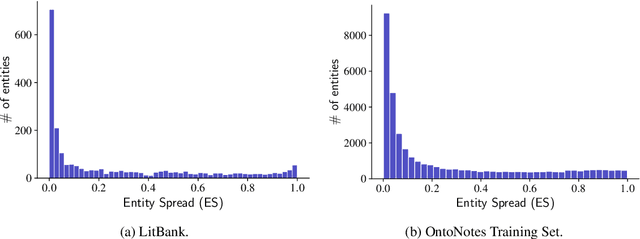
Long document coreference resolution remains a challenging task due to the large memory and runtime requirements of current models. Recent work doing incremental coreference resolution using just the global representation of entities shows practical benefits but requires keeping all entities in memory, which can be impractical for long documents. We argue that keeping all entities in memory is unnecessary, and we propose a memory-augmented neural network that tracks only a small bounded number of entities at a time, thus guaranteeing a linear runtime in length of document. We show that (a) the model remains competitive with models with high memory and computational requirements on OntoNotes and LitBank, and (b) the model learns an efficient memory management strategy easily outperforming a rule-based strategy.
An Exploration of Arbitrary-Order Sequence Labeling via Energy-Based Inference Networks
Oct 06, 2020
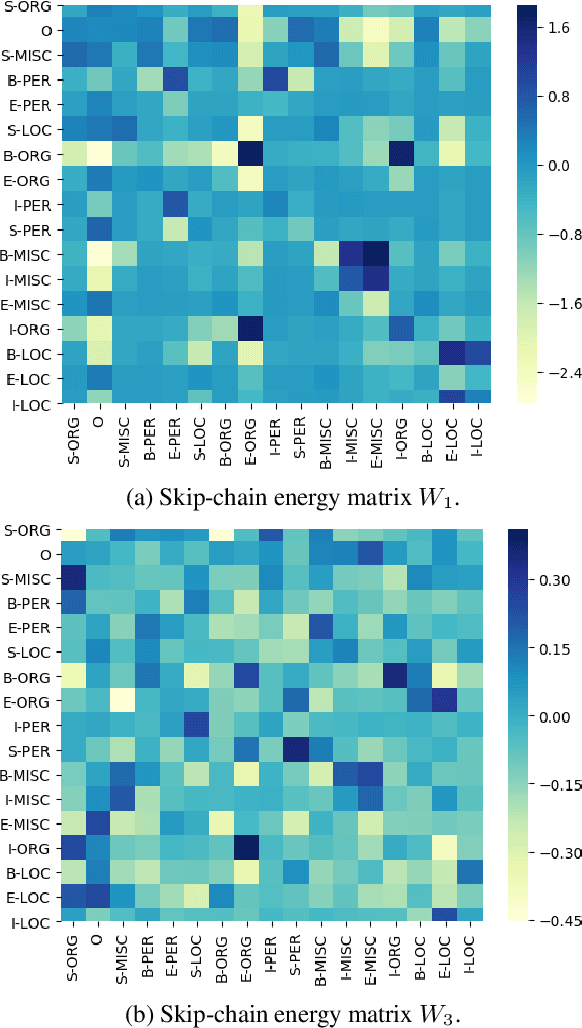
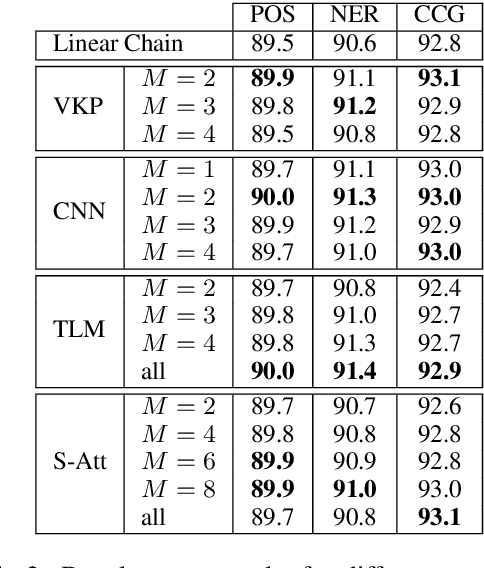
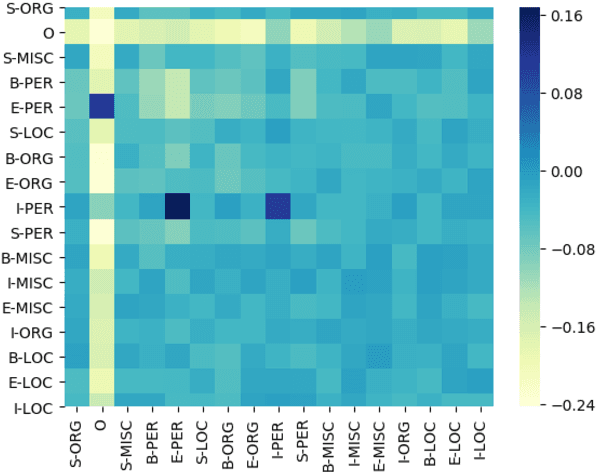
Many tasks in natural language processing involve predicting structured outputs, e.g., sequence labeling, semantic role labeling, parsing, and machine translation. Researchers are increasingly applying deep representation learning to these problems, but the structured component of these approaches is usually quite simplistic. In this work, we propose several high-order energy terms to capture complex dependencies among labels in sequence labeling, including several that consider the entire label sequence. We use neural parameterizations for these energy terms, drawing from convolutional, recurrent, and self-attention networks. We use the framework of learning energy-based inference networks (Tu and Gimpel, 2018) for dealing with the difficulties of training and inference with such models. We empirically demonstrate that this approach achieves substantial improvement using a variety of high-order energy terms on four sequence labeling tasks, while having the same decoding speed as simple, local classifiers. We also find high-order energies to help in noisy data conditions.
Mining Knowledge for Natural Language Inference from Wikipedia Categories
Oct 03, 2020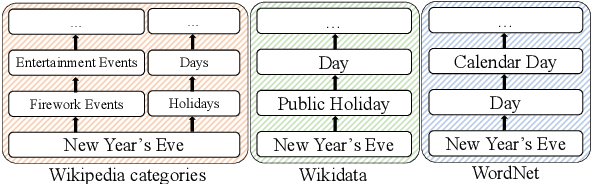
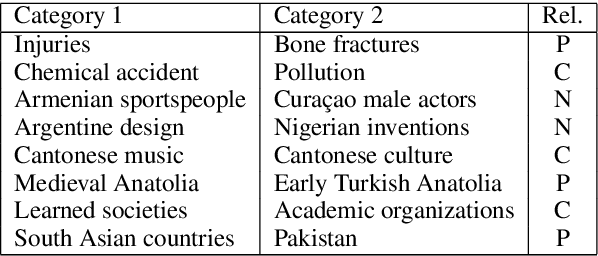
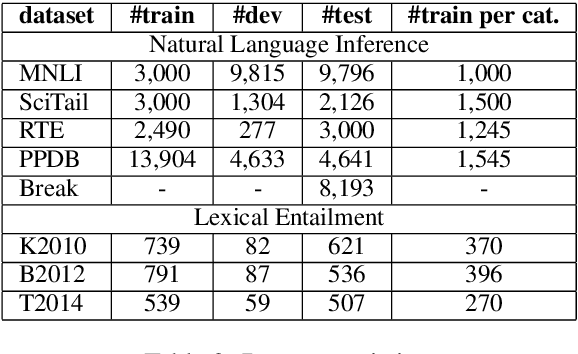
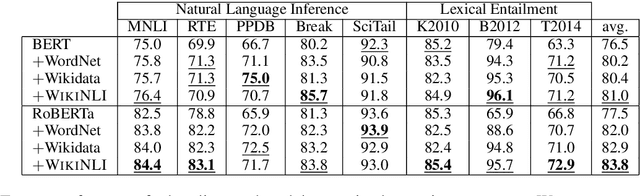
Accurate lexical entailment (LE) and natural language inference (NLI) often require large quantities of costly annotations. To alleviate the need for labeled data, we introduce WikiNLI: a resource for improving model performance on NLI and LE tasks. It contains 428,899 pairs of phrases constructed from naturally annotated category hierarchies in Wikipedia. We show that we can improve strong baselines such as BERT and RoBERTa by pretraining them on WikiNLI and transferring the models on downstream tasks. We conduct systematic comparisons with phrases extracted from other knowledge bases such as WordNet and Wikidata to find that pretraining on WikiNLI gives the best performance. In addition, we construct WikiNLI in other languages, and show that pretraining on them improves performance on NLI tasks of corresponding languages.
Natcat: Weakly Supervised Text Classification with Naturally Annotated Datasets
Sep 29, 2020
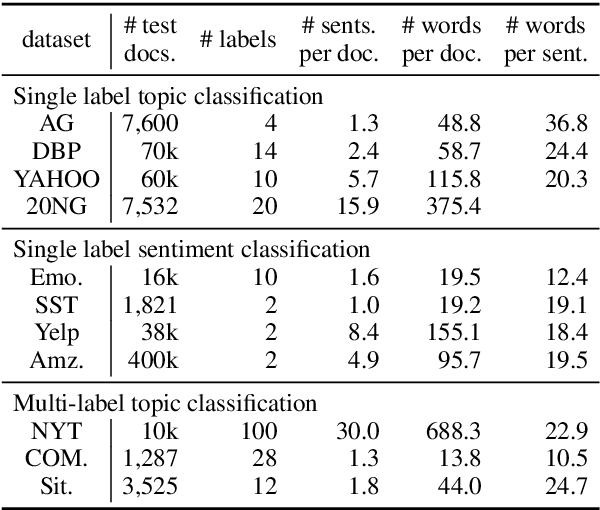
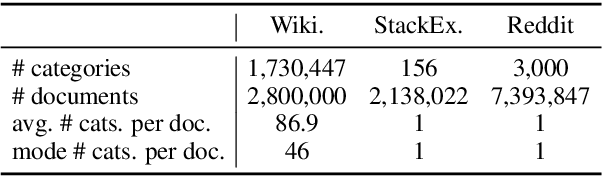
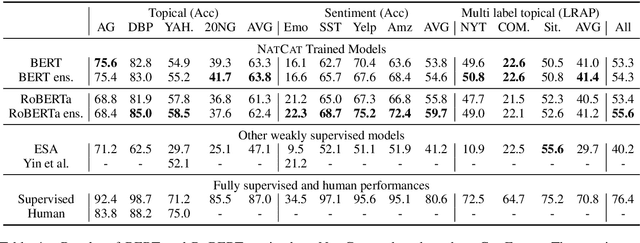
We seek to improve text classification by leveraging naturally annotated data. In particular, we construct a general purpose text categorization dataset (NatCat) from three online resources: Wikipedia, Reddit, and Stack Exchange. These datasets consist of document-category pairs derived from manual curation that occurs naturally by their communities. We build general purpose text classifiers by training on NatCat and evaluate them on a suite of 11 text classification tasks (CatEval). We benchmark different modeling choices and dataset combinations, and show how each task benefits from different NatCat training resources.
Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size
Aug 16, 2020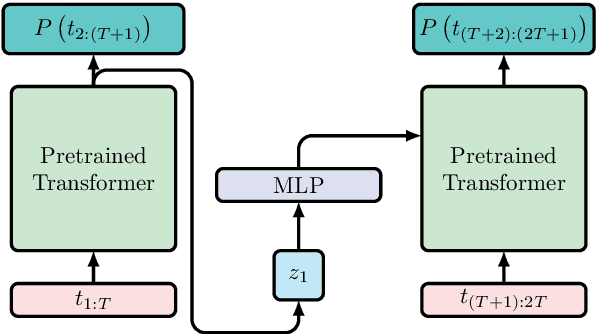
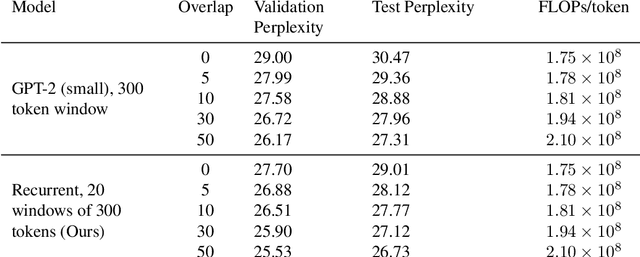
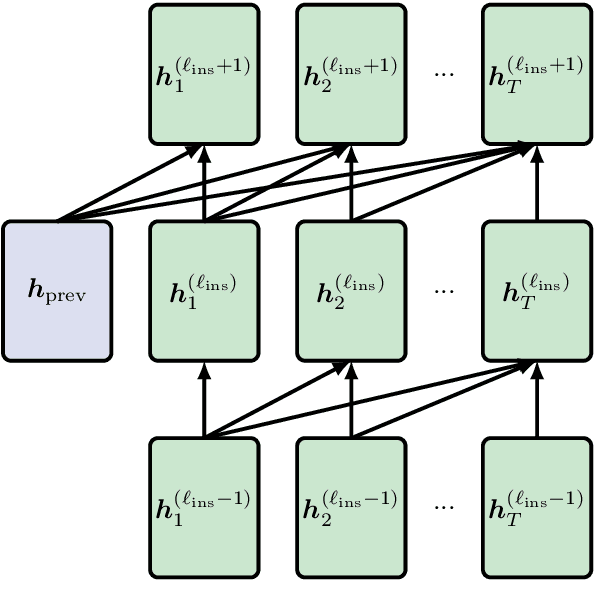
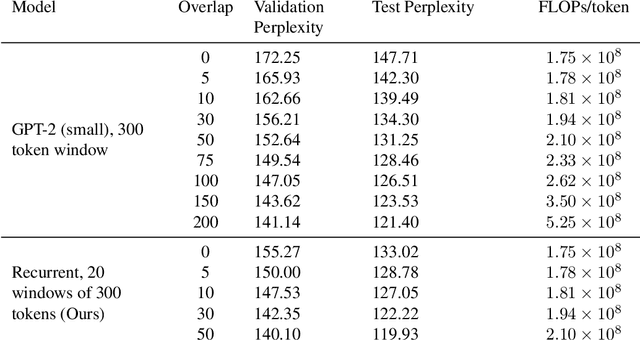
Fine-tuning a pretrained transformer for a downstream task has become a standard method in NLP in the last few years. While the results from these models are impressive, applying them can be extremely computationally expensive, as is pretraining new models with the latest architectures. We present a novel method for applying pretrained transformer language models which lowers their memory requirement both at training and inference time. An additional benefit is that our method removes the fixed context size constraint that most transformer models have, allowing for more flexible use. When applied to the GPT-2 language model, we find that our method attains better perplexity than an unmodified GPT-2 model on the PG-19 and WikiText-103 corpora, for a given amount of computation or memory.
A Cross-Task Analysis of Text Span Representations
Jun 06, 2020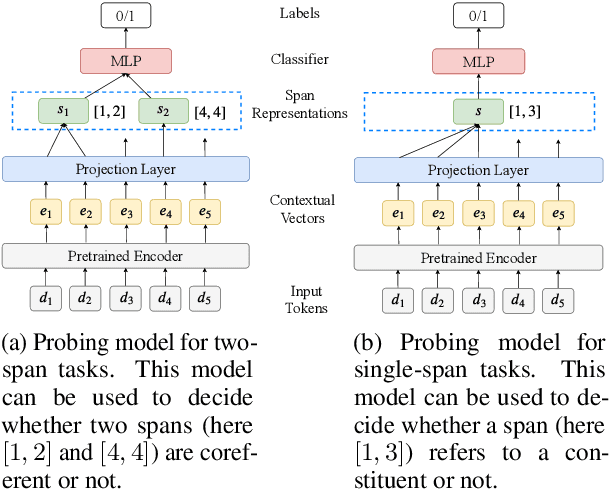
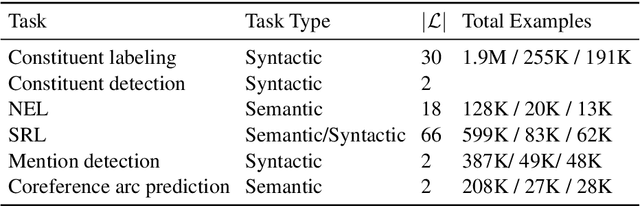
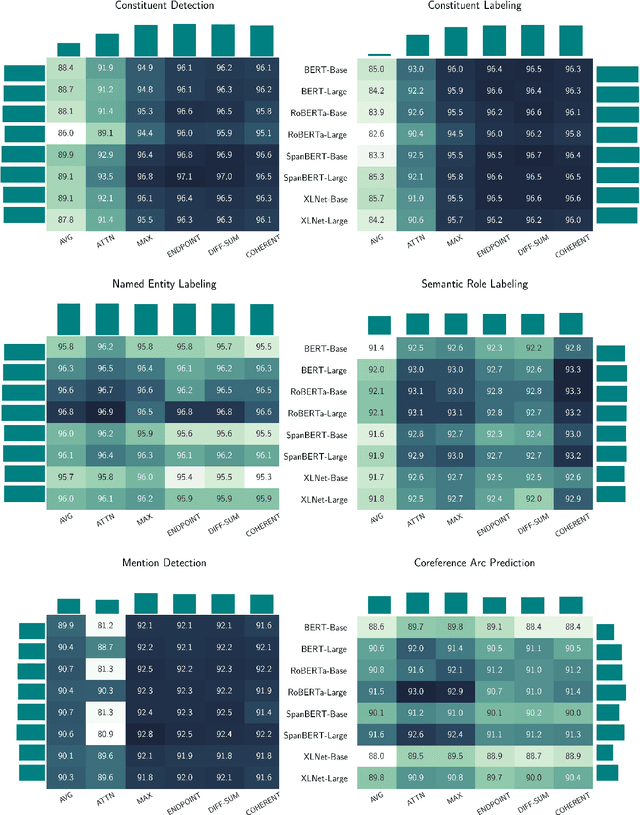
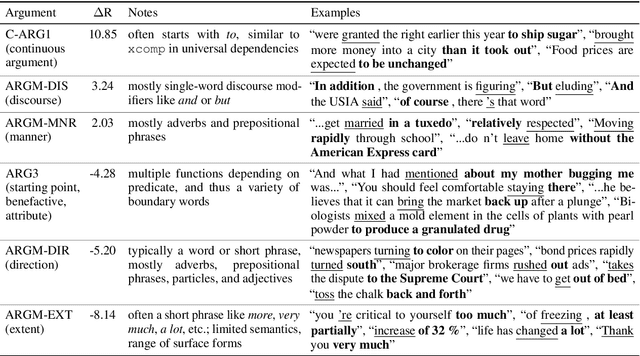
Many natural language processing (NLP) tasks involve reasoning with textual spans, including question answering, entity recognition, and coreference resolution. While extensive research has focused on functional architectures for representing words and sentences, there is less work on representing arbitrary spans of text within sentences. In this paper, we conduct a comprehensive empirical evaluation of six span representation methods using eight pretrained language representation models across six tasks, including two tasks that we introduce. We find that, although some simple span representations are fairly reliable across tasks, in general the optimal span representation varies by task, and can also vary within different facets of individual tasks. We also find that the choice of span representation has a bigger impact with a fixed pretrained encoder than with a fine-tuned encoder.
Learning Probabilistic Sentence Representations from Paraphrases
May 16, 2020
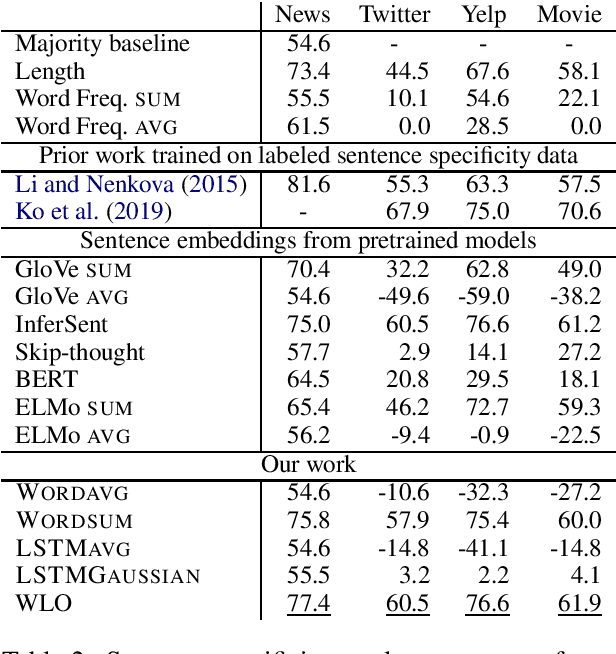
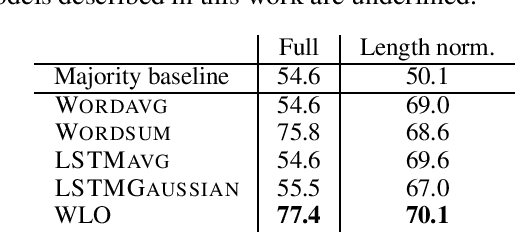
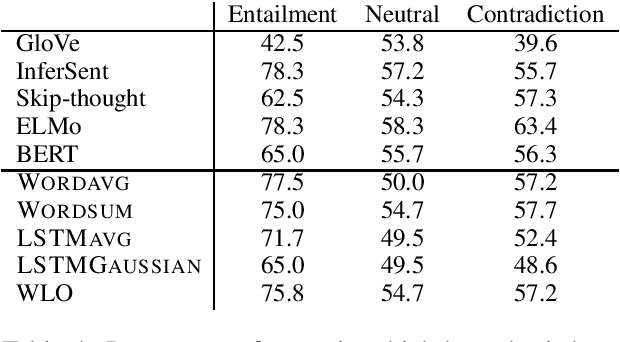
Probabilistic word embeddings have shown effectiveness in capturing notions of generality and entailment, but there is very little work on doing the analogous type of investigation for sentences. In this paper we define probabilistic models that produce distributions for sentences. Our best-performing model treats each word as a linear transformation operator applied to a multivariate Gaussian distribution. We train our models on paraphrases and demonstrate that they naturally capture sentence specificity. While our proposed model achieves the best performance overall, we also show that specificity is represented by simpler architectures via the norm of the sentence vectors. Qualitative analysis shows that our probabilistic model captures sentential entailment and provides ways to analyze the specificity and preciseness of individual words.
ENGINE: Energy-Based Inference Networks for Non-Autoregressive Machine Translation
May 12, 2020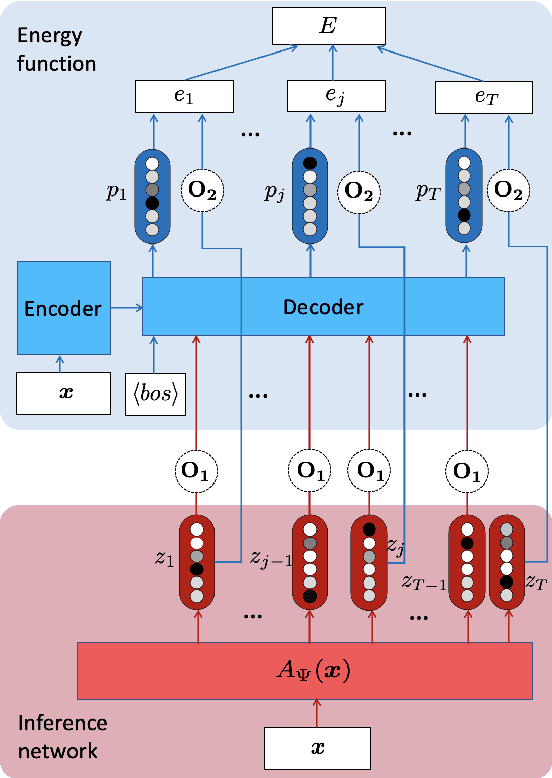
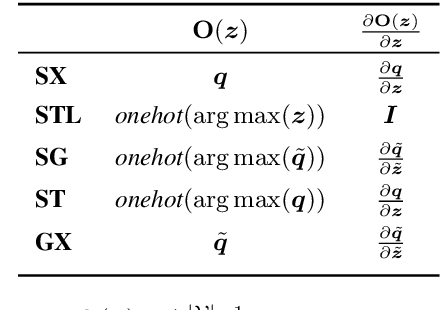

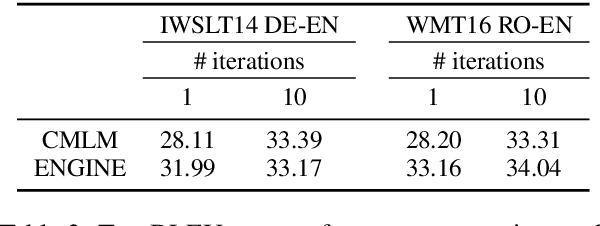
We propose to train a non-autoregressive machine translation model to minimize the energy defined by a pretrained autoregressive model. In particular, we view our non-autoregressive translation system as an inference network (Tu and Gimpel, 2018) trained to minimize the autoregressive teacher energy. This contrasts with the popular approach of training a non-autoregressive model on a distilled corpus consisting of the beam-searched outputs of such a teacher model. Our approach, which we call ENGINE (ENerGy-based Inference NEtworks), achieves state-of-the-art non-autoregressive results on the IWSLT 2014 DE-EN and WMT 2016 RO-EN datasets, approaching the performance of autoregressive models.
PeTra: A Sparsely Supervised Memory Model for People Tracking
May 06, 2020

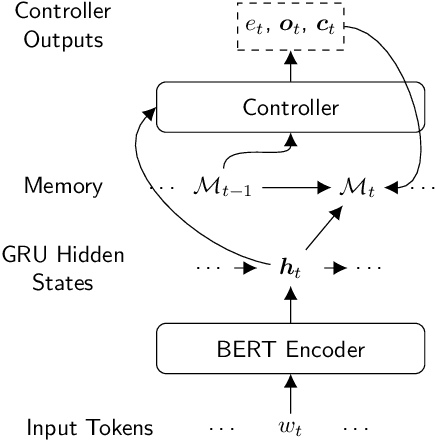
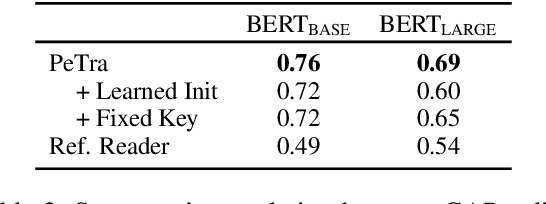
We propose PeTra, a memory-augmented neural network designed to track entities in its memory slots. PeTra is trained using sparse annotation from the GAP pronoun resolution dataset and outperforms a prior memory model on the task while using a simpler architecture. We empirically compare key modeling choices, finding that we can simplify several aspects of the design of the memory module while retaining strong performance. To measure the people tracking capability of memory models, we (a) propose a new diagnostic evaluation based on counting the number of unique entities in text, and (b) conduct a small scale human evaluation to compare evidence of people tracking in the memory logs of PeTra relative to a previous approach. PeTra is highly effective in both evaluations, demonstrating its ability to track people in its memory despite being trained with limited annotation.