 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversion Rate Prediction via Meta Learning in Small-Scale Recommendation Scenarios
Dec 27, 2021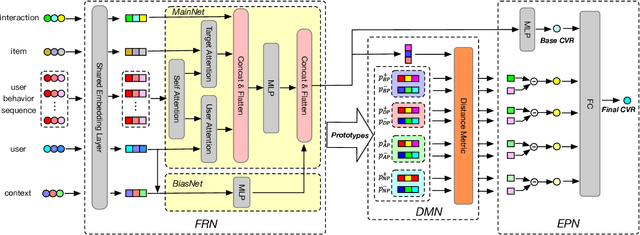
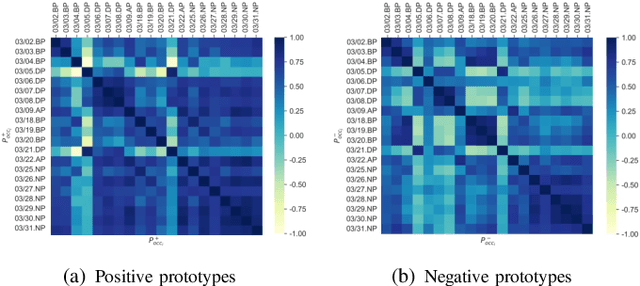
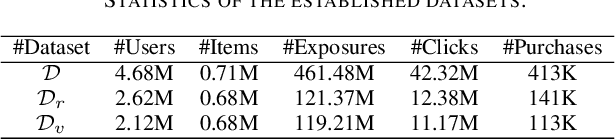
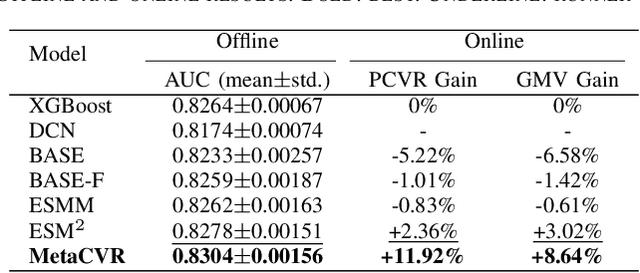
Different from large-scale platforms such as Taobao and Amazon, developing CVR models in small-scale recommendation scenarios is more challenging due to the severe Data Distribution Fluctuation (DDF) issue. DDF prevents existing CVR models from being effective since 1) several months of data are needed to train CVR models sufficiently in small scenarios, leading to considerable distribution discrepancy between training and online serving; and 2) e-commerce promotions have much more significant impacts on small scenarios, leading to distribution uncertainty of the upcoming time period. In this work, we propose a novel CVR method named MetaCVR from a perspective of meta learning to address the DDF issue. Firstly, a base CVR model which consists of a Feature Representation Network (FRN) and output layers is elaborately designed and trained sufficiently with samples across months. Then we treat time periods with different data distributions as different occasions and obtain positive and negative prototypes for each occasion using the corresponding samples and the pre-trained FRN. Subsequently, a Distance Metric Network (DMN) is devised to calculate the distance metrics between each sample and all prototypes to facilitate mitigating the distribution uncertainty. At last, we develop an Ensemble Prediction Network (EPN) which incorporates the output of FRN and DMN to make the final CVR prediction. In this stage, we freeze the FRN and train the DMN and EPN with samples from recent time period, therefore effectively easing the distribution discrepancy. To the best of our knowledge, this is the first study of CVR prediction targeting the DDF issue in small-scale recommendation scenarios. Experimental results on real-world datasets validate the superiority of our MetaCVR and online A/B test also shows our model achieves impressive gains of 11.92% on PCVR and 8.64% on GMV.
SAME: Scenario Adaptive Mixture-of-Experts for Promotion-Aware Click-Through Rate Prediction
Dec 27, 2021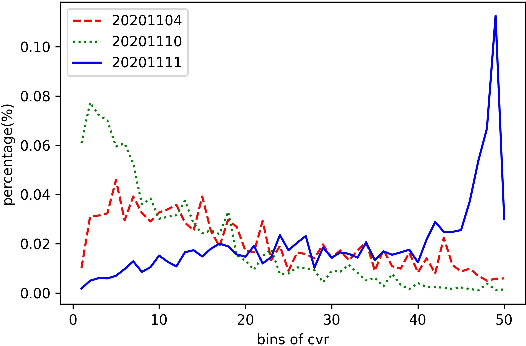
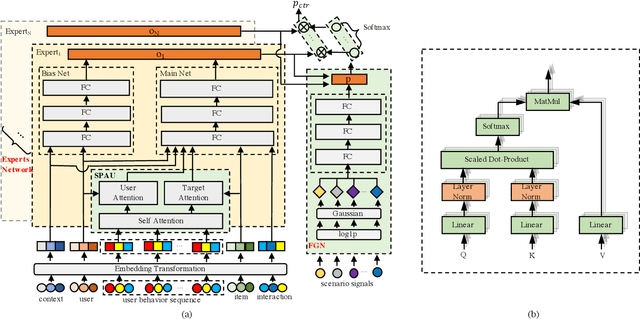
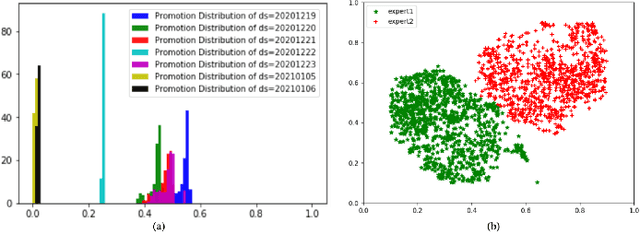
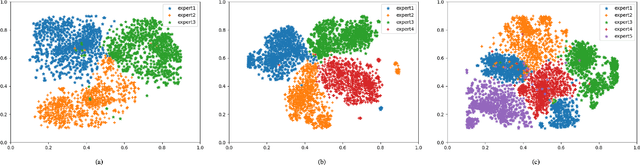
Promotions are becoming more important and prevalent in e-commerce platforms to attract customers and boost sales. However, Click-Through Rate (CTR) prediction methods in recommender systems are not able to handle such circumstances well since: 1) they can't generalize well to serving because the online data distribution is uncertain due to the potentially upcoming promotions; 2) without paying enough attention to scenario signals, they are incapable of learning different feature representation patterns which coexist in each scenario. In this work, we propose Scenario Adaptive Mixture-of-Experts (SAME), a simple yet effective model that serves both promotion and normal scenarios. Technically, it follows the idea of Mixture-of-Experts by adopting multiple experts to learn feature representations, which are modulated by a Feature Gated Network (FGN) via an attention mechanism. To obtain high-quality representations, we design a Stacked Parallel Attention Unit (SPAU) to help each expert better handle user behavior sequence. To tackle the distribution uncertainty, a set of scenario signals are elaborately devised from a perspective of time series prediction and fed into the FGN, whose output is concatenated with feature representation from each expert to learn the attention. Accordingly, a mixture of the feature representations is obtained scenario-adaptively and used for the final CTR prediction. In this way, each expert can learn a discriminative representation pattern. To the best of our knowledge, this is the first study for promotion-aware CTR prediction. Experimental results on real-world datasets validate the superiority of SAME. Online A/B test also shows SAME achieves significant gains of 3.58% on CTR and 5.94% on IPV during promotion periods as well as 3.93% and 6.57% in normal days, respectively.