 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecentering Validity Considerations through Early-Stage Deliberations Around AI and Policy Design
Mar 26, 2023AI-based decision-making tools are rapidly spreading across a range of real-world, complex domains like healthcare, criminal justice, and child welfare. A growing body of research has called for increased scrutiny around the validity of AI system designs. However, in real-world settings, it is often not possible to fully address questions around the validity of an AI tool without also considering the design of associated organizational and public policies. Yet, considerations around how an AI tool may interface with policy are often only discussed retrospectively, after the tool is designed or deployed. In this short position paper, we discuss opportunities to promote multi-stakeholder deliberations around the design of AI-based technologies and associated policies, at the earliest stages of a new project.
Understanding Frontline Workers' and Unhoused Individuals' Perspectives on AI Used in Homeless Services
Mar 17, 2023



Recent years have seen growing adoption of AI-based decision-support systems (ADS) in homeless services, yet we know little about stakeholder desires and concerns surrounding their use. In this work, we aim to understand impacted stakeholders' perspectives on a deployed ADS that prioritizes scarce housing resources. We employed AI lifecycle comicboarding, an adapted version of the comicboarding method, to elicit stakeholder feedback and design ideas across various components of an AI system's design. We elicited feedback from county workers who operate the ADS daily, service providers whose work is directly impacted by the ADS, and unhoused individuals in the region. Our participants shared concerns and design suggestions around the AI system's overall objective, specific model design choices, dataset selection, and use in deployment. Our findings demonstrate that stakeholders, even without AI knowledge, can provide specific and critical feedback on an AI system's design and deployment, if empowered to do so.
Exploring Challenges and Opportunities to Support Designers in Learning to Co-create with AI-based Manufacturing Design Tools
Mar 01, 2023



AI-based design tools are proliferating in professional software to assist engineering and industrial designers in complex manufacturing and design tasks. These tools take on more agentic roles than traditional computer-aided design tools and are often portrayed as "co-creators." Yet, working effectively with such systems requires different skills than working with complex CAD tools alone. To date, we know little about how engineering designers learn to work with AI-based design tools. In this study, we observed trained designers as they learned to work with two AI-based tools on a realistic design task. We find that designers face many challenges in learning to effectively co-create with current systems, including challenges in understanding and adjusting AI outputs and in communicating their design goals. Based on our findings, we highlight several design opportunities to better support designer-AI co-creation.
Ground Truth: A Causal Framework for Proxy Labels in Human-Algorithm Decision-Making
Feb 22, 2023



A growing literature on human-AI decision-making investigates strategies for combining human judgment with statistical models to improve decision-making. Research in this area often evaluates proposed improvements to models, interfaces, or workflows by demonstrating improved predictive performance on "ground truth" labels. However, this practice overlooks a key difference between human judgments and model predictions. Whereas humans reason about broader phenomena of interest in a decision -- including latent constructs that are not directly observable, such as disease status, the "toxicity" of online comments, or future "job performance" -- predictive models target proxy labels that are readily available in existing datasets. Predictive models' reliance on simplistic proxies makes them vulnerable to various sources of statistical bias. In this paper, we identify five sources of target variable bias that can impact the validity of proxy labels in human-AI decision-making tasks. We develop a causal framework to disentangle the relationship between each bias and clarify which are of concern in specific human-AI decision-making tasks. We demonstrate how our framework can be used to articulate implicit assumptions made in prior modeling work, and we recommend evaluation strategies for verifying whether these assumptions hold in practice. We then leverage our framework to re-examine the designs of prior human subjects experiments that investigate human-AI decision-making, finding that only a small fraction of studies examine factors related to target variable bias. We conclude by discussing opportunities to better address target variable bias in future research.
Counterfactual Prediction Under Outcome Measurement Error
Feb 22, 2023Across domains such as medicine, employment, and criminal justice, predictive models often target labels that imperfectly reflect the outcomes of interest to experts and policymakers. For example, clinical risk assessments deployed to inform physician decision-making often predict measures of healthcare utilization (e.g., costs, hospitalization) as a proxy for patient medical need. These proxies can be subject to outcome measurement error when they systematically differ from the target outcome they are intended to measure. However, prior modeling efforts to characterize and mitigate outcome measurement error overlook the fact that the decision being informed by a model often serves as a risk-mitigating intervention that impacts the target outcome of interest and its recorded proxy. Thus, in these settings, addressing measurement error requires counterfactual modeling of treatment effects on outcomes. In this work, we study intersectional threats to model reliability introduced by outcome measurement error, treatment effects, and selection bias from historical decision-making policies. We develop an unbiased risk minimization method which, given knowledge of proxy measurement error properties, corrects for the combined effects of these challenges. We also develop a method for estimating treatment-dependent measurement error parameters when these are unknown in advance. We demonstrate the utility of our approach theoretically and via experiments on real-world data from randomized controlled trials conducted in healthcare and employment domains. As importantly, we demonstrate that models correcting for outcome measurement error or treatment effects alone suffer from considerable reliability limitations. Our work underscores the importance of considering intersectional threats to model validity during the design and evaluation of predictive models for decision support.
Understanding Practices, Challenges, and Opportunities for User-Driven Algorithm Auditing in Industry Practice
Oct 10, 2022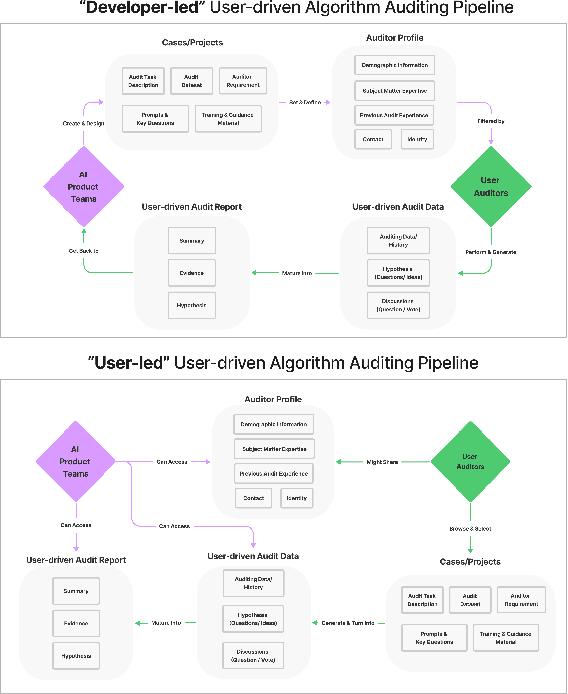
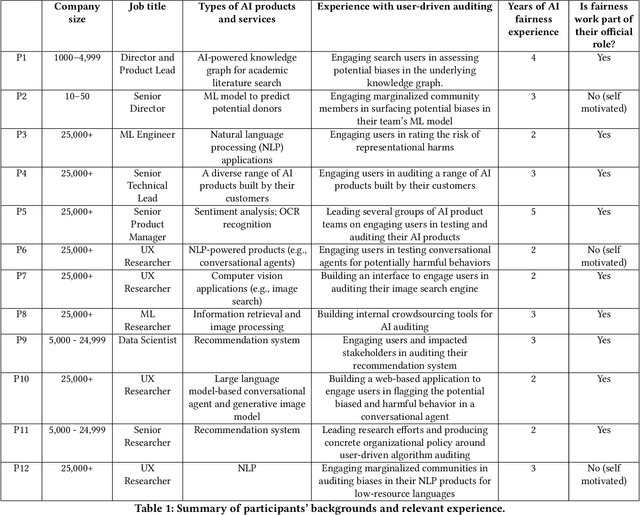
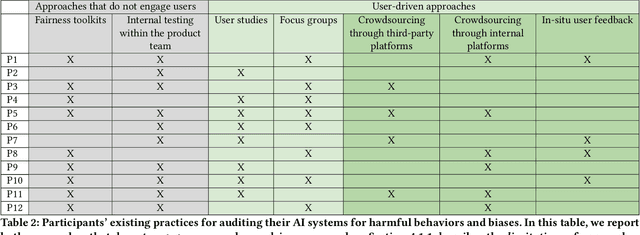

Recent years have seen growing interest among both researchers and practitioners in user-driven approaches to algorithm auditing, which directly engage users in detecting problematic behaviors in algorithmic systems. However, we know little about industry practitioners' current practices and challenges around user-driven auditing, nor what opportunities exist for them to better leverage such approaches in practice. To investigate, we conducted a series of interviews and iterative co-design activities with practitioners who employ user-driven auditing approaches in their work. Our findings reveal several challenges practitioners face in appropriately recruiting and incentivizing user auditors, scaffolding user audits, and deriving actionable insights from user-driven audit reports. Furthermore, practitioners shared organizational obstacles to user-driven auditing, surfacing a complex relationship between practitioners and user auditors. Based on these findings, we discuss opportunities for future HCI research to help realize the potential (and mitigate risks) of user-driven auditing in industry practice.
Toward Supporting Perceptual Complementarity in Human-AI Collaboration via Reflection on Unobservables
Jul 28, 2022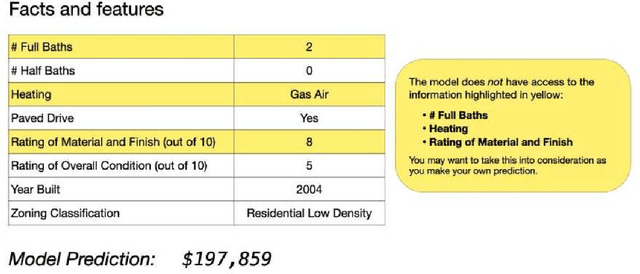
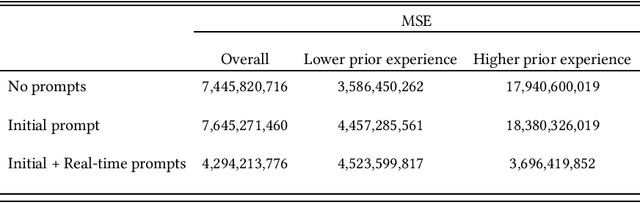
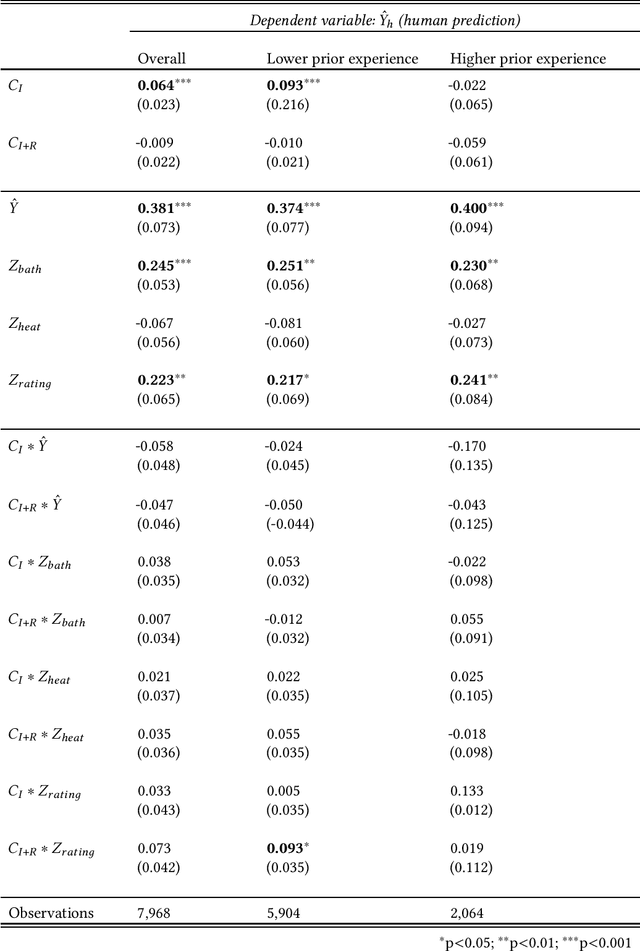

In many real world contexts, successful human-AI collaboration requires humans to productively integrate complementary sources of information into AI-informed decisions. However, in practice human decision-makers often lack understanding of what information an AI model has access to in relation to themselves. There are few available guidelines regarding how to effectively communicate about unobservables: features that may influence the outcome, but which are unavailable to the model. In this work, we conducted an online experiment to understand whether and how explicitly communicating potentially relevant unobservables influences how people integrate model outputs and unobservables when making predictions. Our findings indicate that presenting prompts about unobservables can change how humans integrate model outputs and unobservables, but do not necessarily lead to improved performance. Furthermore, the impacts of these prompts can vary depending on decision-makers' prior domain expertise. We conclude by discussing implications for future research and design of AI-based decision support tools.
Team Learning as a Lens for Designing Human-AI Co-Creative Systems
Jul 06, 2022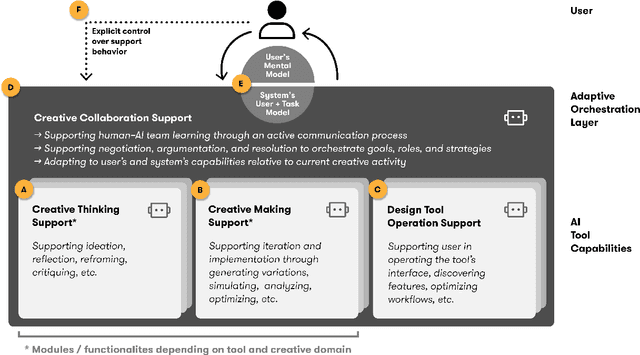
Generative, ML-driven interactive systems have the potential to change how people interact with computers in creative processes - turning tools into co-creators. However, it is still unclear how we might achieve effective human-AI collaboration in open-ended task domains. There are several known challenges around communication in the interaction with ML-driven systems. An overlooked aspect in the design of co-creative systems is how users can be better supported in learning to collaborate with such systems. Here we reframe human-AI collaboration as a learning problem: Inspired by research on team learning, we hypothesize that similar learning strategies that apply to human-human teams might also increase the collaboration effectiveness and quality of humans working with co-creative generative systems. In this position paper, we aim to promote team learning as a lens for designing more effective co-creative human-AI collaboration and emphasize collaboration process quality as a goal for co-creative systems. Furthermore, we outline a preliminary schematic framework for embedding team learning support in co-creative AI systems. We conclude by proposing a research agenda and posing open questions for further study on supporting people in learning to collaborate with generative AI systems.
Imagining new futures beyond predictive systems in child welfare: A qualitative study with impacted stakeholders
May 18, 2022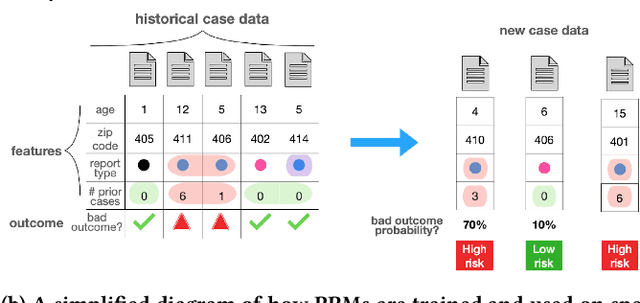
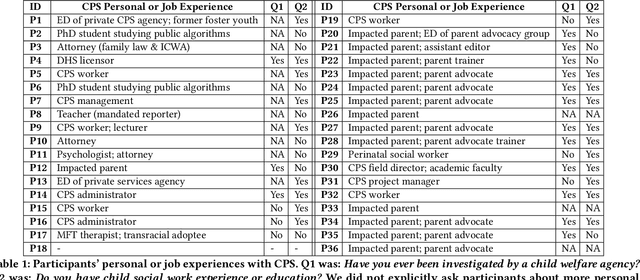

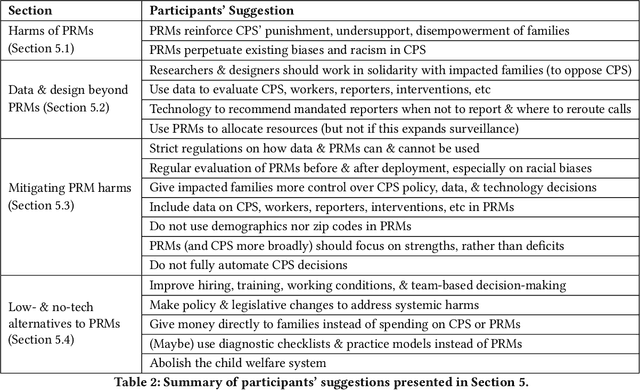
Child welfare agencies across the United States are turning to data-driven predictive technologies (commonly called predictive analytics) which use government administrative data to assist workers' decision-making. While some prior work has explored impacted stakeholders' concerns with current uses of data-driven predictive risk models (PRMs), less work has asked stakeholders whether such tools ought to be used in the first place. In this work, we conducted a set of seven design workshops with 35 stakeholders who have been impacted by the child welfare system or who work in it to understand their beliefs and concerns around PRMs, and to engage them in imagining new uses of data and technologies in the child welfare system. We found that participants worried current PRMs perpetuate or exacerbate existing problems in child welfare. Participants suggested new ways to use data and data-driven tools to better support impacted communities and suggested paths to mitigate possible harms of these tools. Participants also suggested low-tech or no-tech alternatives to PRMs to address problems in child welfare. Our study sheds light on how researchers and designers can work in solidarity with impacted communities, possibly to circumvent or oppose child welfare agencies.
Exploring How Machine Learning Practitioners (Try To) Use Fairness Toolkits
May 13, 2022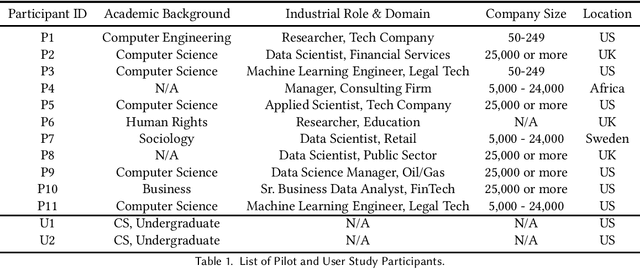
Recent years have seen the development of many open-source ML fairness toolkits aimed at helping ML practitioners assess and address unfairness in their systems. However, there has been little research investigating how ML practitioners actually use these toolkits in practice. In this paper, we conducted the first in-depth empirical exploration of how industry practitioners (try to) work with existing fairness toolkits. In particular, we conducted think-aloud interviews to understand how participants learn about and use fairness toolkits, and explored the generality of our findings through an anonymous online survey. We identified several opportunities for fairness toolkits to better address practitioner needs and scaffold them in using toolkits effectively and responsibly. Based on these findings, we highlight implications for the design of future open-source fairness toolkits that can support practitioners in better contextualizing, communicating, and collaborating around ML fairness efforts.