 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Convergence of Epanechnikov Mean Shift
Nov 20, 2017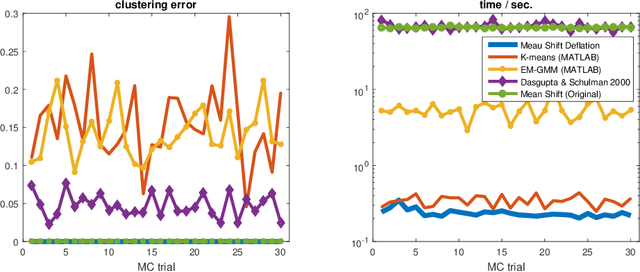
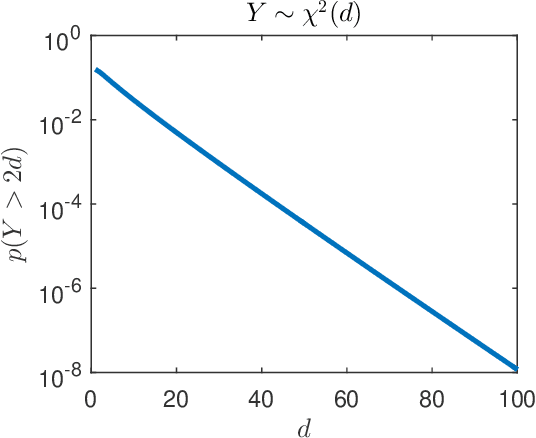
Epanechnikov Mean Shift is a simple yet empirically very effective algorithm for clustering. It localizes the centroids of data clusters via estimating modes of the probability distribution that generates the data points, using the `optimal' Epanechnikov kernel density estimator. However, since the procedure involves non-smooth kernel density functions, the convergence behavior of Epanechnikov mean shift lacks theoretical support as of this writing---most of the existing analyses are based on smooth functions and thus cannot be applied to Epanechnikov Mean Shift. In this work, we first show that the original Epanechnikov Mean Shift may indeed terminate at a non-critical point, due to the non-smoothness nature. Based on our analysis, we propose a simple remedy to fix it. The modified Epanechnikov Mean Shift is guaranteed to terminate at a local maximum of the estimated density, which corresponds to a cluster centroid, within a finite number of iterations. We also propose a way to avoid running the Mean Shift iterates from every data point, while maintaining good clustering accuracies under non-overlapping spherical Gaussian mixture models. This further pushes Epanechnikov Mean Shift to handle very large and high-dimensional data sets. Experiments show surprisingly good performance compared to the Lloyd's K-means algorithm and the EM algorithm.
Scalable and Flexible Multiview MAX-VAR Canonical Correlation Analysis
May 04, 2017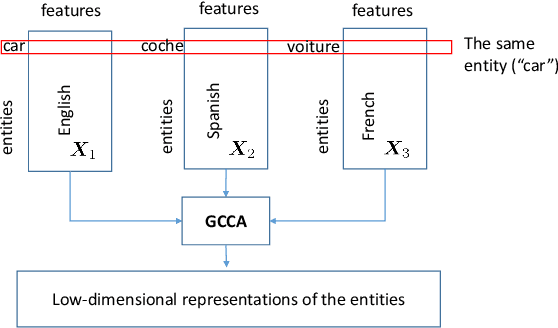
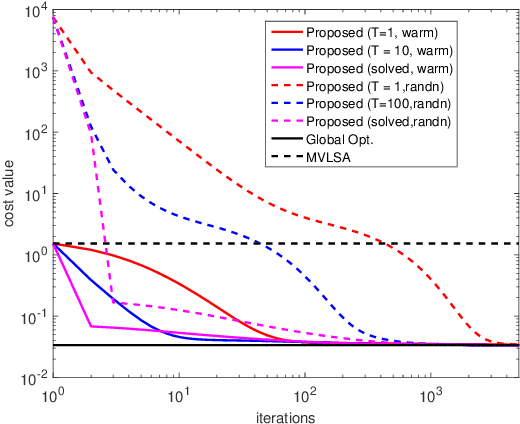
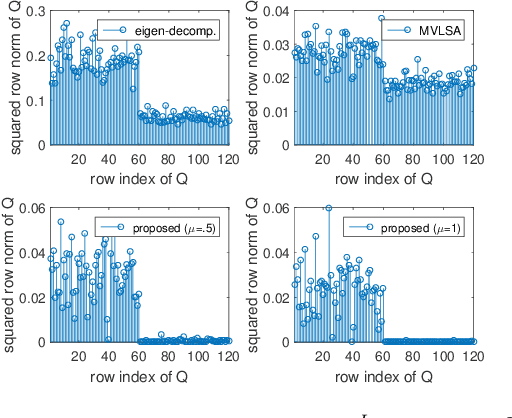
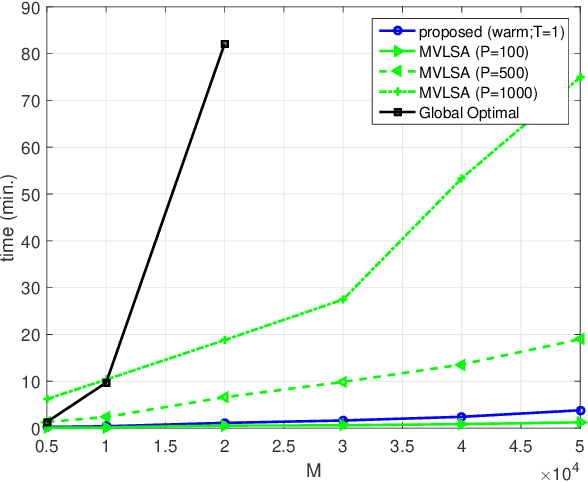
Generalized canonical correlation analysis (GCCA) aims at finding latent low-dimensional common structure from multiple views (feature vectors in different domains) of the same entities. Unlike principal component analysis (PCA) that handles a single view, (G)CCA is able to integrate information from different feature spaces. Here we focus on MAX-VAR GCCA, a popular formulation which has recently gained renewed interest in multilingual processing and speech modeling. The classic MAX-VAR GCCA problem can be solved optimally via eigen-decomposition of a matrix that compounds the (whitened) correlation matrices of the views; but this solution has serious scalability issues, and is not directly amenable to incorporating pertinent structural constraints such as non-negativity and sparsity on the canonical components. We posit regularized MAX-VAR GCCA as a non-convex optimization problem and propose an alternating optimization (AO)-based algorithm to handle it. Our algorithm alternates between {\em inexact} solutions of a regularized least squares subproblem and a manifold-constrained non-convex subproblem, thereby achieving substantial memory and computational savings. An important benefit of our design is that it can easily handle structure-promoting regularization. We show that the algorithm globally converges to a critical point at a sublinear rate, and approaches a global optimal solution at a linear rate when no regularization is considered. Judiciously designed simulations and large-scale word embedding tasks are employed to showcase the effectiveness of the proposed algorithm.
Tensor Decomposition for Signal Processing and Machine Learning
Dec 14, 2016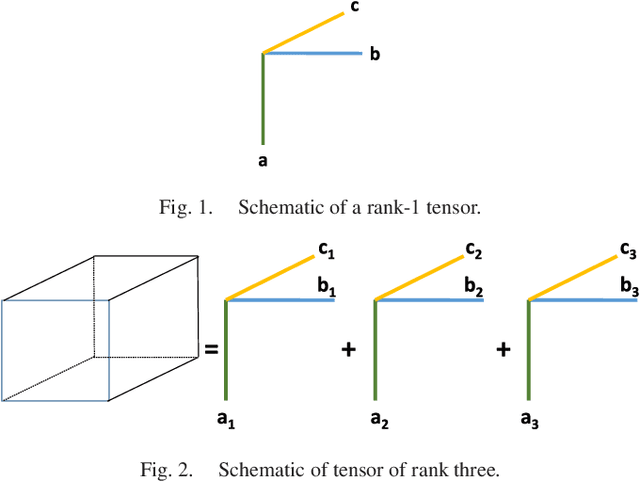
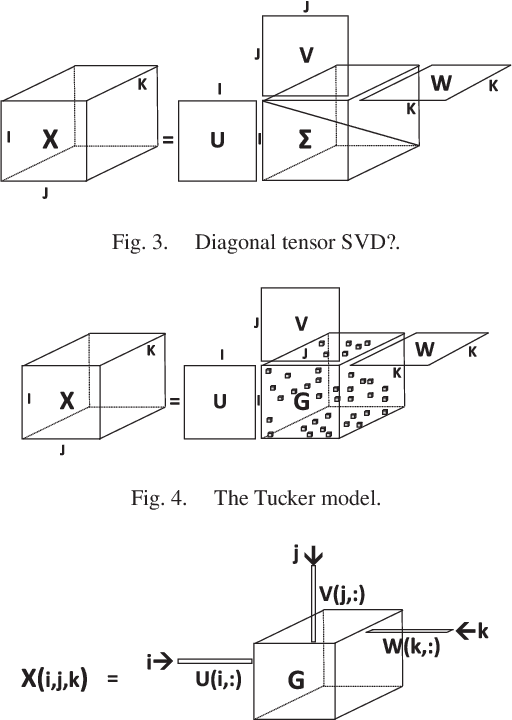
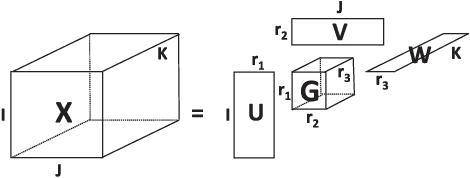
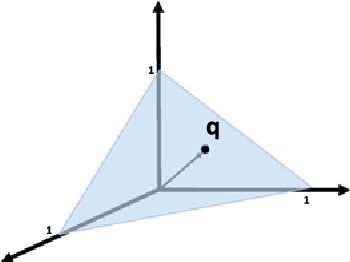
Tensors or {\em multi-way arrays} are functions of three or more indices $(i,j,k,\cdots)$ -- similar to matrices (two-way arrays), which are functions of two indices $(r,c)$ for (row,column). Tensors have a rich history, stretching over almost a century, and touching upon numerous disciplines; but they have only recently become ubiquitous in signal and data analytics at the confluence of signal processing, statistics, data mining and machine learning. This overview article aims to provide a good starting point for researchers and practitioners interested in learning about and working with tensors. As such, it focuses on fundamentals and motivation (using various application examples), aiming to strike an appropriate balance of breadth {\em and depth} that will enable someone having taken first graduate courses in matrix algebra and probability to get started doing research and/or developing tensor algorithms and software. Some background in applied optimization is useful but not strictly required. The material covered includes tensor rank and rank decomposition; basic tensor factorization models and their relationships and properties (including fairly good coverage of identifiability); broad coverage of algorithms ranging from alternating optimization to stochastic gradient; statistical performance analysis; and applications ranging from source separation to collaborative filtering, mixture and topic modeling, classification, and multilinear subspace learning.
Anchor-Free Correlated Topic Modeling: Identifiability and Algorithm
Nov 15, 2016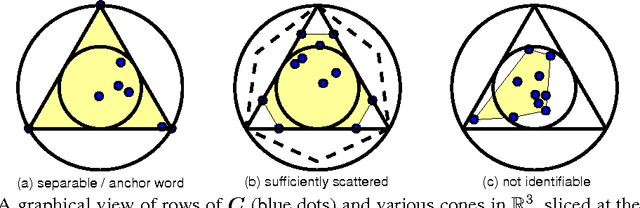
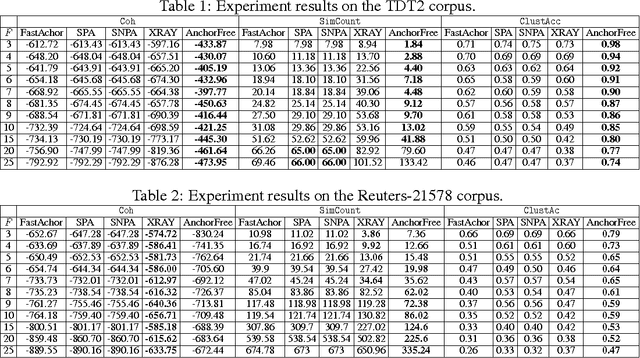
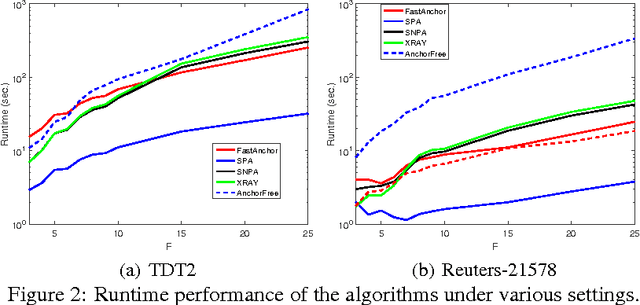
In topic modeling, many algorithms that guarantee identifiability of the topics have been developed under the premise that there exist anchor words -- i.e., words that only appear (with positive probability) in one topic. Follow-up work has resorted to three or higher-order statistics of the data corpus to relax the anchor word assumption. Reliable estimates of higher-order statistics are hard to obtain, however, and the identification of topics under those models hinges on uncorrelatedness of the topics, which can be unrealistic. This paper revisits topic modeling based on second-order moments, and proposes an anchor-free topic mining framework. The proposed approach guarantees the identification of the topics under a much milder condition compared to the anchor-word assumption, thereby exhibiting much better robustness in practice. The associated algorithm only involves one eigen-decomposition and a few small linear programs. This makes it easy to implement and scale up to very large problem instances. Experiments using the TDT2 and Reuters-21578 corpus demonstrate that the proposed anchor-free approach exhibits very favorable performance (measured using coherence, similarity count, and clustering accuracy metrics) compared to the prior art.
Robust Volume Minimization-Based Matrix Factorization for Remote Sensing and Document Clustering
Aug 15, 2016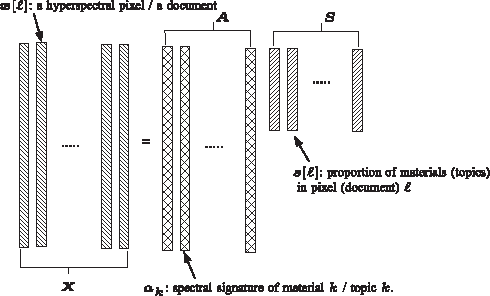
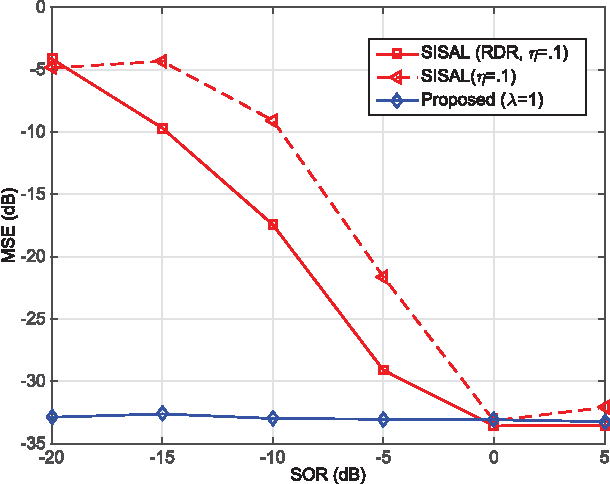
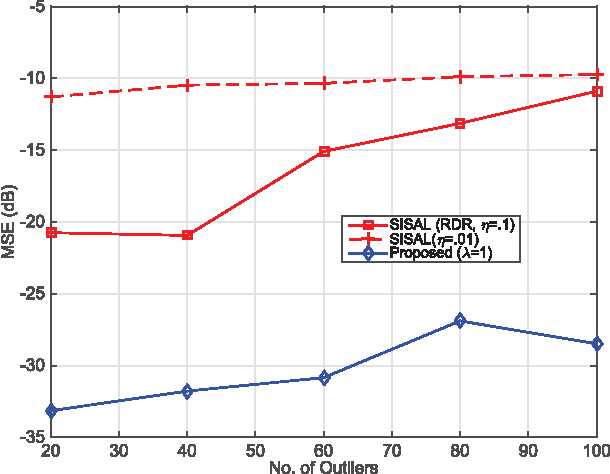
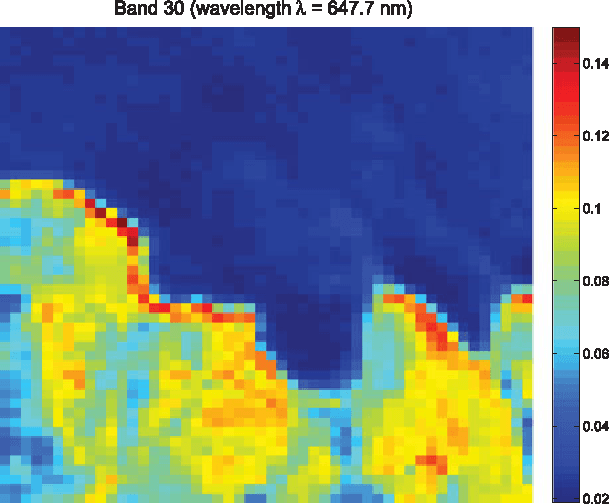
This paper considers \emph{volume minimization} (VolMin)-based structured matrix factorization (SMF). VolMin is a factorization criterion that decomposes a given data matrix into a basis matrix times a structured coefficient matrix via finding the minimum-volume simplex that encloses all the columns of the data matrix. Recent work showed that VolMin guarantees the identifiability of the factor matrices under mild conditions that are realistic in a wide variety of applications. This paper focuses on both theoretical and practical aspects of VolMin. On the theory side, exact equivalence of two independently developed sufficient conditions for VolMin identifiability is proven here, thereby providing a more comprehensive understanding of this aspect of VolMin. On the algorithm side, computational complexity and sensitivity to outliers are two key challenges associated with real-world applications of VolMin. These are addressed here via a new VolMin algorithm that handles volume regularization in a computationally simple way, and automatically detects and {iteratively downweights} outliers, simultaneously. Simulations and real-data experiments using a remotely sensed hyperspectral image and the Reuters document corpus are employed to showcase the effectiveness of the proposed algorithm.
A Flexible and Efficient Algorithmic Framework for Constrained Matrix and Tensor Factorization
Oct 28, 2015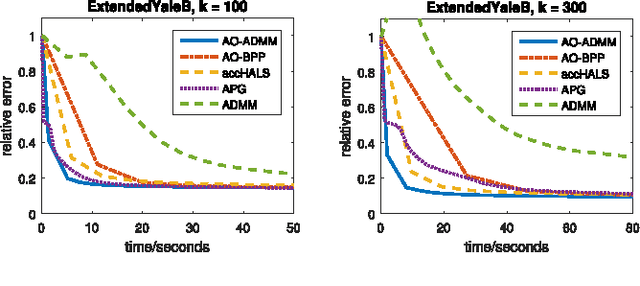
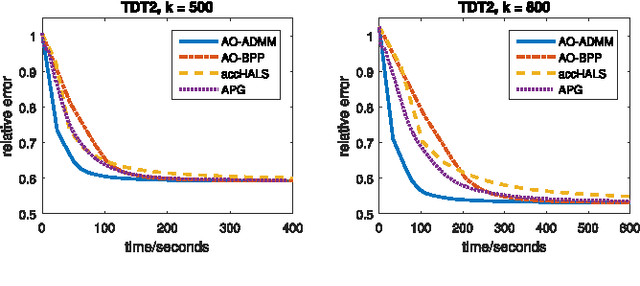
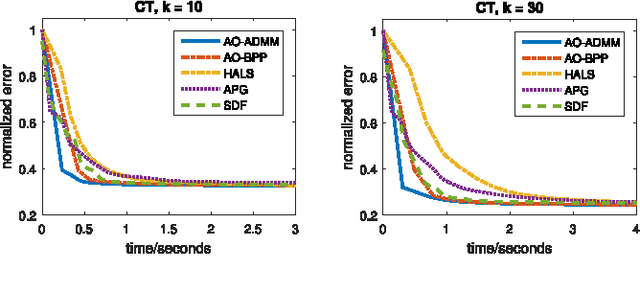
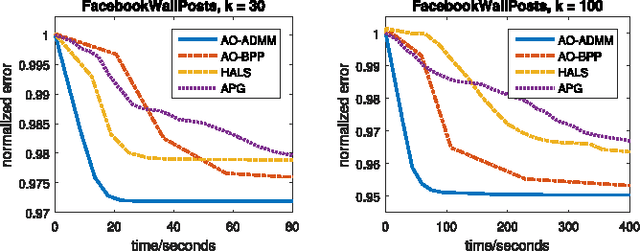
We propose a general algorithmic framework for constrained matrix and tensor factorization, which is widely used in signal processing and machine learning. The new framework is a hybrid between alternating optimization (AO) and the alternating direction method of multipliers (ADMM): each matrix factor is updated in turn, using ADMM, hence the name AO-ADMM. This combination can naturally accommodate a great variety of constraints on the factor matrices, and almost all possible loss measures for the fitting. Computation caching and warm start strategies are used to ensure that each update is evaluated efficiently, while the outer AO framework exploits recent developments in block coordinate descent (BCD)-type methods which help ensure that every limit point is a stationary point, as well as faster and more robust convergence in practice. Three special cases are studied in detail: non-negative matrix/tensor factorization, constrained matrix/tensor completion, and dictionary learning. Extensive simulations and experiments with real data are used to showcase the effectiveness and broad applicability of the proposed framework.
Joint Tensor Factorization and Outlying Slab Suppression with Applications
Jul 16, 2015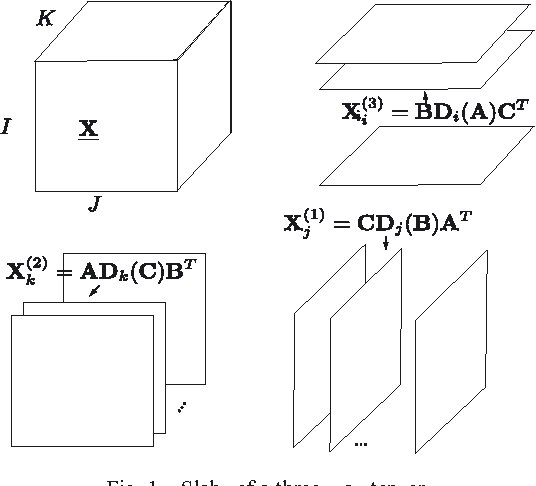
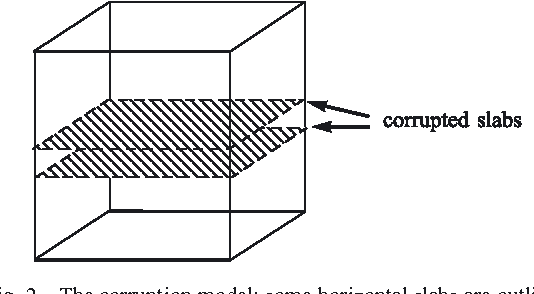
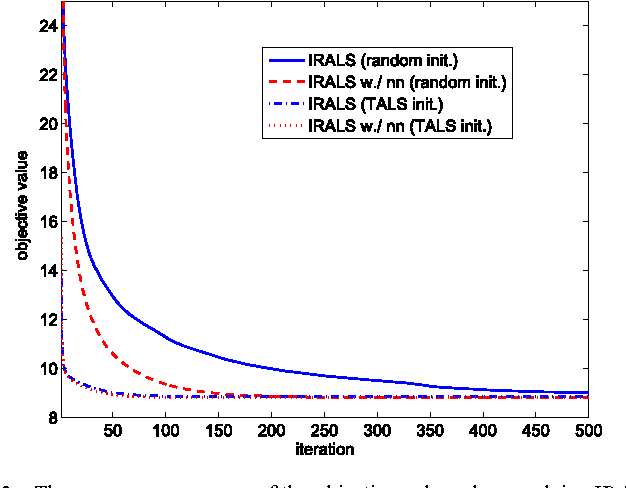
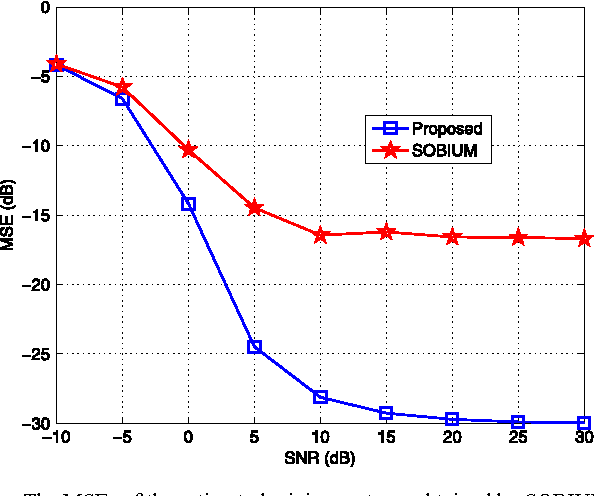
We consider factoring low-rank tensors in the presence of outlying slabs. This problem is important in practice, because data collected in many real-world applications, such as speech, fluorescence, and some social network data, fit this paradigm. Prior work tackles this problem by iteratively selecting a fixed number of slabs and fitting, a procedure which may not converge. We formulate this problem from a group-sparsity promoting point of view, and propose an alternating optimization framework to handle the corresponding $\ell_p$ ($0<p\leq 1$) minimization-based low-rank tensor factorization problem. The proposed algorithm features a similar per-iteration complexity as the plain trilinear alternating least squares (TALS) algorithm. Convergence of the proposed algorithm is also easy to analyze under the framework of alternating optimization and its variants. In addition, regularization and constraints can be easily incorporated to make use of \emph{a priori} information on the latent loading factors. Simulations and real data experiments on blind speech separation, fluorescence data analysis, and social network mining are used to showcase the effectiveness of the proposed algorithm.