 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can disambiguate opioid slang on social media
Mar 11, 2026Social media text shows promise for monitoring trends in the opioid overdose crisis; however, the overwhelming majority of social media text is unrelated to opioids. When leveraging social media text to monitor trends in the ongoing opioid overdose crisis, a common strategy for identifying relevant content is to use a lexicon of opioid-related terms as inclusion criteria. However, many slang terms for opioids, such as "smack" or "blues," have common non-opioid meanings, making them ambiguous. The advanced textual reasoning capability of large language models (LLMs) presents an opportunity to disambiguate these slang terms at scale. We present three tasks on which to evaluate four state-of-the-art LLMs (GPT-4, GPT-5, Gemini 2.5 Pro, and Claude Sonnet 4.5): a lexicon-based setting, in which the LLM must disambiguate a specific term within the context of a given post; a lexicon-free setting, in which the LLM must identify opioid-related posts from context without a lexicon; and an emergent slang setting, in which the LLM must identify opioid-related posts with simulated new slang terms. All four LLMs showed excellent performance across all tasks. In both subtasks of the lexicon-based setting, LLM F1 scores ("fenty" subtask: 0.824-0.972; "smack" subtask: 0.540-0.862) far exceeded those of the best lexicon strategy (0.126 and 0.009, respectively). In the lexicon-free task, LLM F1 scores (0.544-0.769) surpassed those of lexicons (0.080-0.540), and LLMs demonstrated uniformly higher recall. On emergent slang, all LLMs had higher accuracy (average: 0.784), F1 score (average: 0.712), precision (average: 0.981), and recall (average: 0.587) than the two lexicons assessed. Our results show that LLMs can be used to identify relevant content for low-prevalence topics, including but not limited to opioid references, enhancing data provided to downstream analyses and predictive models.
Asymptotically Exact and Fast Gaussian Copula Models for Imputation of Mixed Data Types
Feb 04, 2021


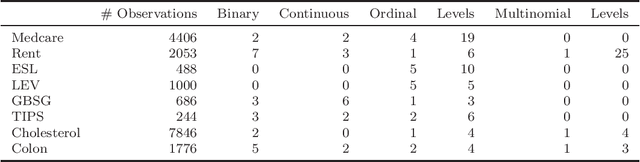
Missing values with mixed data types is a common problem in a large number of machine learning applications such as processing of surveys and in different medical applications. Recently, Gaussian copula models have been suggested as a means of performing imputation of missing values using a probabilistic framework. While the present Gaussian copula models have shown to yield state of the art performance, they have two limitations: they are based on an approximation that is fast but may be imprecise and they do not support unordered multinomial variables. We address the first limitation using direct and arbitrarily precise approximations both for model estimation and imputation by using randomized quasi-Monte Carlo procedures. The method we provide has lower errors for the estimated model parameters and the imputed values, compared to previously proposed methods. We also extend the previous Gaussian copula models to include unordered multinomial variables in addition to the present support of ordinal, binary, and continuous variables.