 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Performance to Purpose: A Sociotechnical Taxonomy for Evaluating Large Language Model Utility
Feb 24, 2026As large language models (LLMs) continue to improve at completing discrete tasks, they are being integrated into increasingly complex and diverse real-world systems. However, task-level success alone does not establish a model's fit for use in practice. In applied, high-stakes settings, LLM effectiveness is driven by a wider array of sociotechnical determinants that extend beyond conventional performance measures. Although a growing set of metrics capture many of these considerations, they are rarely organized in a way that supports consistent evaluation, leaving no unified taxonomy for assessing and comparing LLM utility across use cases. To address this gap, we introduce the Language Model Utility Taxonomy (LUX), a comprehensive framework that structures utility evaluation across four domains: performance, interaction, operations, and governance. Within each domain, LUX is organized hierarchically into thematically aligned dimensions and components, each grounded in metrics that enable quantitative comparison and alignment of model selection with intended use. In addition, an external dynamic web tool is provided to support exploration of the framework by connecting each component to a repository of relevant metrics (factors) for applied evaluation.
Representing Outcome-driven Higher-order Dependencies in Graphs of Disease Trajectories
Dec 23, 2023



The widespread application of machine learning techniques to biomedical data has produced many new insights into disease progression and improving clinical care. Inspired by the flexibility and interpretability of graphs (networks), as well as the potency of sequence models like transformers and higher-order networks (HONs), we propose a method that identifies combinations of risk factors for a given outcome and accurately encodes these higher-order relationships in a graph. Using historical data from 913,475 type 2 diabetes (T2D) patients, we found that, compared to other approaches, the proposed networks encode significantly more information about the progression of T2D toward a variety of outcomes. We additionally demonstrate how structural information from the proposed graph can be used to augment the performance of transformer-based models on predictive tasks, especially when the data are noisy. By increasing the order, or memory, of the graph, we show how the proposed method illuminates key risk factors while successfully ignoring noisy elements, which facilitates analysis that is simultaneously accurate and interpretable.
Beyond Volume: The Impact of Complex Healthcare Data on the Machine Learning Pipeline
Jan 26, 2018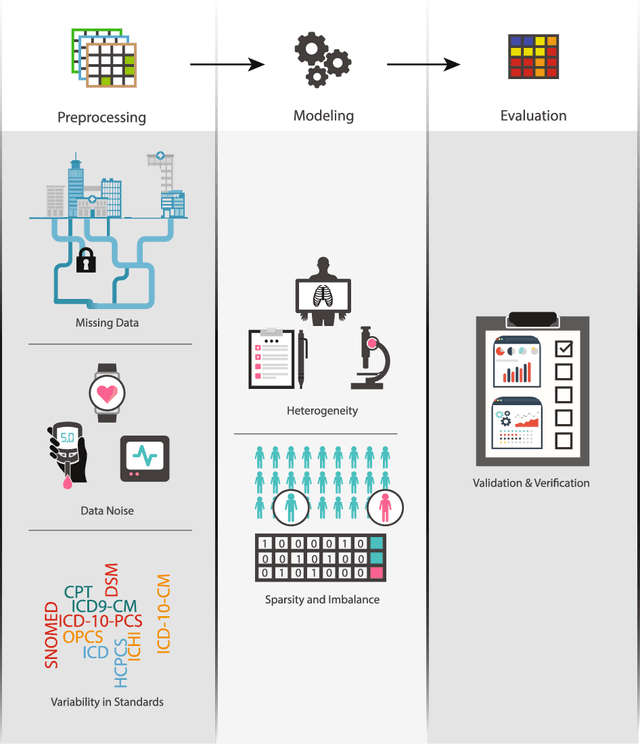
From medical charts to national census, healthcare has traditionally operated under a paper-based paradigm. However, the past decade has marked a long and arduous transformation bringing healthcare into the digital age. Ranging from electronic health records, to digitized imaging and laboratory reports, to public health datasets, today, healthcare now generates an incredible amount of digital information. Such a wealth of data presents an exciting opportunity for integrated machine learning solutions to address problems across multiple facets of healthcare practice and administration. Unfortunately, the ability to derive accurate and informative insights requires more than the ability to execute machine learning models. Rather, a deeper understanding of the data on which the models are run is imperative for their success. While a significant effort has been undertaken to develop models able to process the volume of data obtained during the analysis of millions of digitalized patient records, it is important to remember that volume represents only one aspect of the data. In fact, drawing on data from an increasingly diverse set of sources, healthcare data presents an incredibly complex set of attributes that must be accounted for throughout the machine learning pipeline. This chapter focuses on highlighting such challenges, and is broken down into three distinct components, each representing a phase of the pipeline. We begin with attributes of the data accounted for during preprocessing, then move to considerations during model building, and end with challenges to the interpretation of model output. For each component, we present a discussion around data as it relates to the healthcare domain and offer insight into the challenges each may impose on the efficiency of machine learning techniques.
* Healthcare Informatics, Machine Learning, Knowledge Discovery: 20 Pages, 1 Figure