 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Sequential Generative Models for Semi-Supervised Language Instruction Following
Dec 29, 2022



Agents that can follow language instructions are expected to be useful in a variety of situations such as navigation. However, training neural network-based agents requires numerous paired trajectories and languages. This paper proposes using multimodal generative models for semi-supervised learning in the instruction following tasks. The models learn a shared representation of the paired data, and enable semi-supervised learning by reconstructing unpaired data through the representation. Key challenges in applying the models to sequence-to-sequence tasks including instruction following are learning a shared representation of variable-length mulitimodal data and incorporating attention mechanisms. To address the problems, this paper proposes a novel network architecture to absorb the difference in the sequence lengths of the multimodal data. In addition, to further improve the performance, this paper shows how to incorporate the generative model-based approach with an existing semi-supervised method called a speaker-follower model, and proposes a regularization term that improves inference using unpaired trajectories. Experiments on BabyAI and Room-to-Room (R2R) environments show that the proposed method improves the performance of instruction following by leveraging unpaired data, and improves the performance of the speaker-follower model by 2\% to 4\% in R2R.
Conditional Deep Hierarchical Variational Autoencoder for Voice Conversion
Dec 06, 2021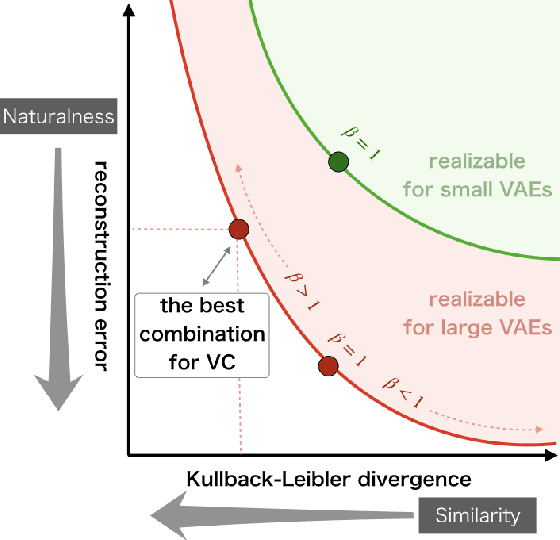
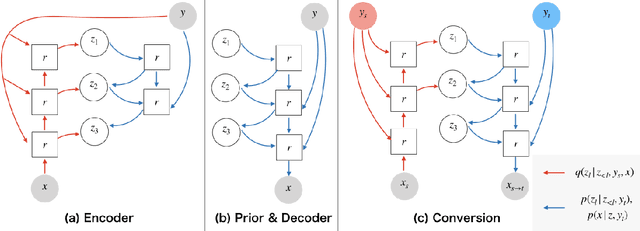
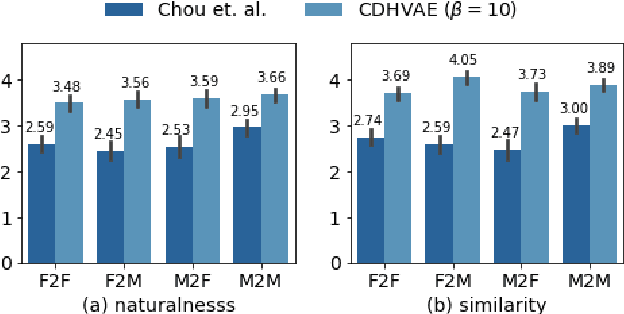
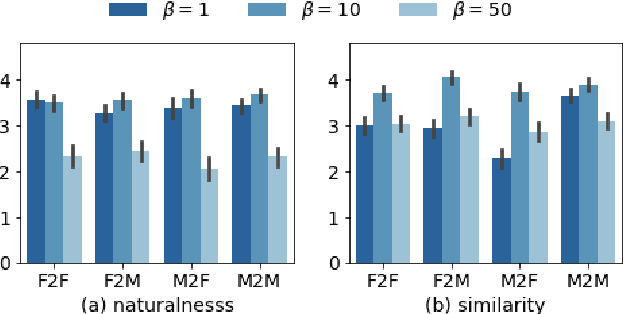
Variational autoencoder-based voice conversion (VAE-VC) has the advantage of requiring only pairs of speeches and speaker labels for training. Unlike the majority of the research in VAE-VC which focuses on utilizing auxiliary losses or discretizing latent variables, this paper investigates how an increasing model expressiveness has benefits and impacts on the VAE-VC. Specifically, we first analyze VAE-VC from a rate-distortion perspective, and point out that model expressiveness is significant for VAE-VC because rate and distortion reflect similarity and naturalness of converted speeches. Based on the analysis, we propose a novel VC method using a deep hierarchical VAE, which has high model expressiveness as well as having fast conversion speed thanks to its non-autoregressive decoder. Also, our analysis reveals another problem that similarity can be degraded when the latent variable of VAEs has redundant information. We address the problem by controlling the information contained in the latent variable using $\beta$-VAE objective. In the experiment using VCTK corpus, the proposed method achieved mean opinion scores higher than 3.5 on both naturalness and similarity in inter-gender settings, which are higher than the scores of existing autoencoder-based VC methods.
Estimating Disentangled Belief about Hidden State and Hidden Task for Meta-RL
May 14, 2021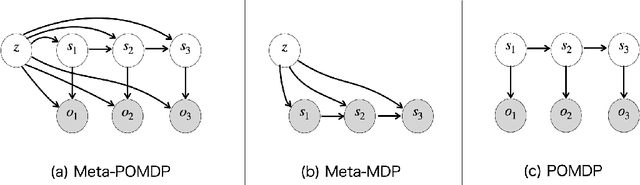
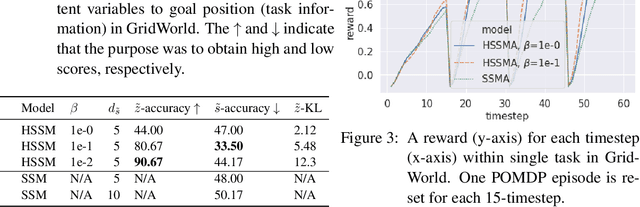
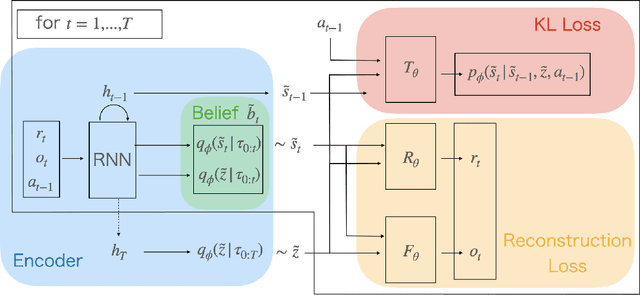
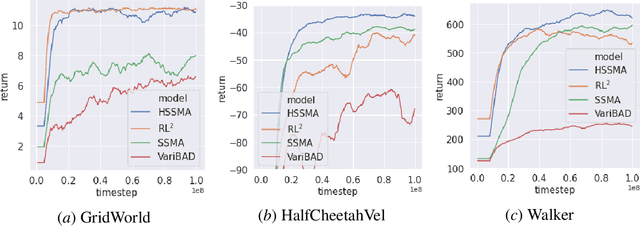
There is considerable interest in designing meta-reinforcement learning (meta-RL) algorithms, which enable autonomous agents to adapt new tasks from small amount of experience. In meta-RL, the specification (such as reward function) of current task is hidden from the agent. In addition, states are hidden within each task owing to sensor noise or limitations in realistic environments. Therefore, the meta-RL agent faces the challenge of specifying both the hidden task and states based on small amount of experience. To address this, we propose estimating disentangled belief about task and states, leveraging an inductive bias that the task and states can be regarded as global and local features of each task. Specifically, we train a hierarchical state-space model (HSSM) parameterized by deep neural networks as an environment model, whose global and local latent variables correspond to task and states, respectively. Because the HSSM does not allow analytical computation of posterior distribution, i.e., belief, we employ amortized inference to approximate it. After the belief is obtained, we can augment observations of a model-free policy with the belief to efficiently train the policy. Moreover, because task and state information are factorized and interpretable, the downstream policy training is facilitated compared with the prior methods that did not consider the hierarchical nature. Empirical validations on a GridWorld environment confirm that the HSSM can separate the hidden task and states information. Then, we compare the meta-RL agent with the HSSM to prior meta-RL methods in MuJoCo environments, and confirm that our agent requires less training data and reaches higher final performance.
Adversarial Invariant Feature Learning with Accuracy Constraint for Domain Generalization
Apr 29, 2019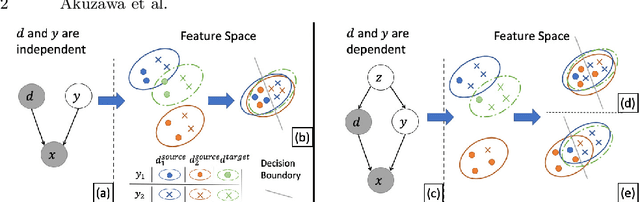

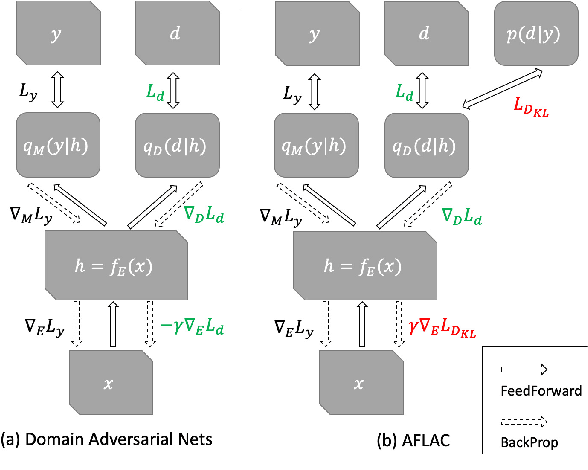
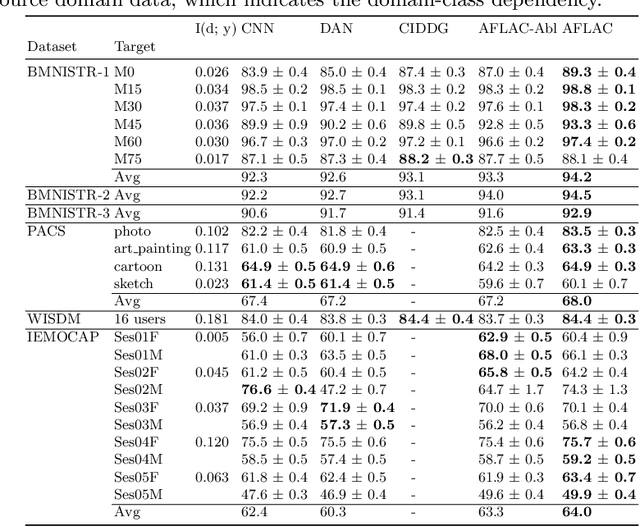
Learning domain-invariant representation is a dominant approach for domain generalization (DG), where we need to build a classifier that is robust toward domain shifts. However, previous domain-invariance-based methods overlooked the underlying dependency of classes on domains, which is responsible for the trade-off between classification accuracy and domain invariance. Because the primary purpose of DG is to classify unseen domains rather than the invariance itself, the improvement of the invariance can negatively affect DG performance under this trade-off. To overcome the problem, this study first expands the analysis of the trade-off by Xie et. al., and provides the notion of accuracy-constrained domain invariance, which means the maximum domain invariance within a range that does not interfere with accuracy. We then propose a novel method adversarial feature learning with accuracy constraint (AFLAC), which explicitly leads to that invariance on adversarial training. Empirical validations show that the performance of AFLAC is superior to that of domain-invariance-based methods on both synthetic and three real-world datasets, supporting the importance of considering the dependency and the efficacy of the proposed method.
Expressive Speech Synthesis via Modeling Expressions with Variational Autoencoder
Jun 27, 2018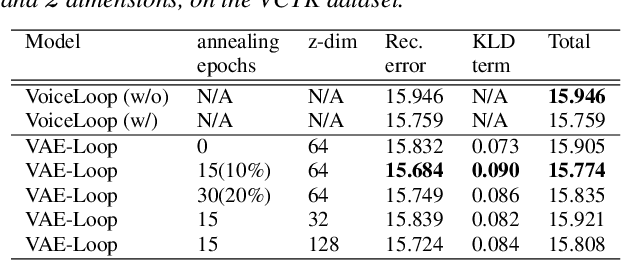
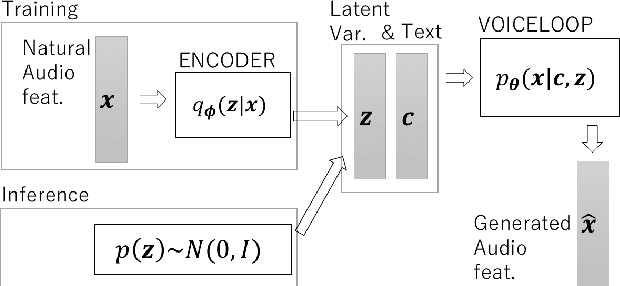
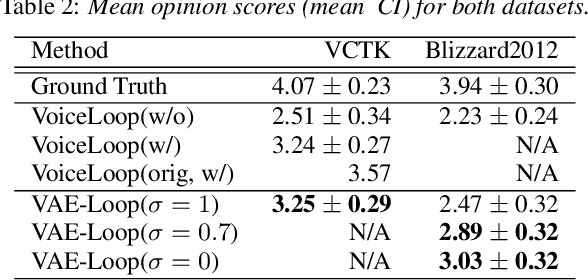
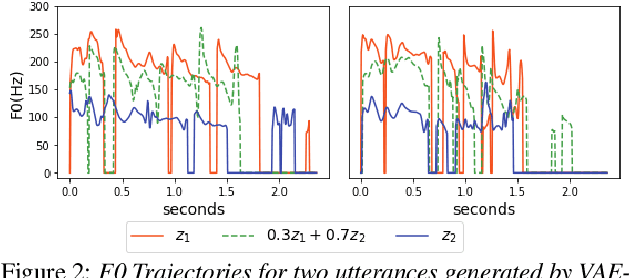
Recent advances in neural autoregressive models have improve the performance of speech synthesis (SS). However, as they lack the ability to model global characteristics of speech (such as speaker individualities or speaking styles), particularly when these characteristics have not been labeled, making neural autoregressive SS systems more expressive is still an open issue. In this paper, we propose to combine VoiceLoop, an autoregressive SS model, with Variational Autoencoder (VAE). This approach, unlike traditional autoregressive SS systems, uses VAE to model the global characteristics explicitly, enabling the expressiveness of the synthesized speech to be controlled in an unsupervised manner. Experiments using the VCTK and Blizzard2012 datasets show the VAE helps VoiceLoop to generate higher quality speech and to control the expressions in its synthesized speech by incorporating global characteristics into the speech generating process.