 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Set-Sequence Model for Time Series
May 16, 2025In many financial prediction problems, the behavior of individual units (such as loans, bonds, or stocks) is influenced by observable unit-level factors and macroeconomic variables, as well as by latent cross-sectional effects. Traditional approaches attempt to capture these latent effects via handcrafted summary features. We propose a Set-Sequence model that eliminates the need for handcrafted features. The Set model first learns a shared cross-sectional summary at each period. The Sequence model then ingests the summary-augmented time series for each unit independently to predict its outcome. Both components are learned jointly over arbitrary sets sampled during training. Our approach harnesses the set nature of the cross-section and is computationally efficient, generating set summaries in linear time relative to the number of units. It is also flexible, allowing the use of existing sequence models and accommodating a variable number of units at inference. Empirical evaluations demonstrate that our Set-Sequence model significantly outperforms benchmarks on stock return prediction and mortgage behavior tasks. Code will be released.
Computationally Efficient Feature Significance and Importance for Machine Learning Models
May 23, 2019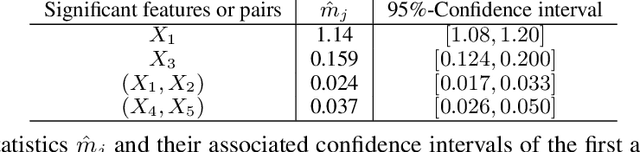
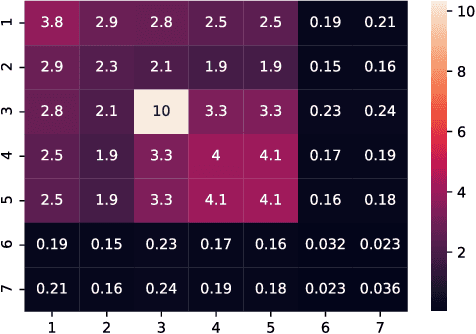
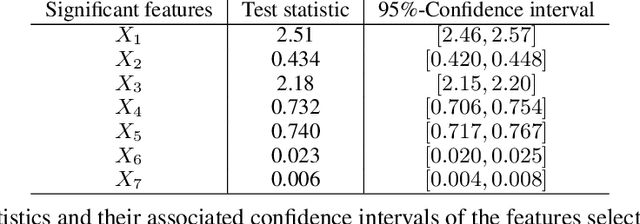
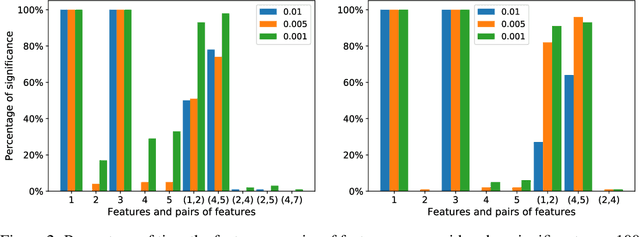
We develop a simple and computationally efficient significance test for the features of a machine learning model. Our forward-selection approach applies to any model specification, learning task and variable type. The test is non-asymptotic, straightforward to implement, and does not require model refitting. It identifies the statistically significant features as well as feature interactions of any order in a hierarchical manner, and generates a model-free notion of feature importance. Numerical results illustrate its performance.
Towards Explainable AI: Significance Tests for Neural Networks
Feb 16, 2019



Neural networks underpin many of the best-performing AI systems. Their success is largely due to their strong approximation properties, superior predictive performance, and scalability. However, a major caveat is explainability: neural networks are often perceived as black boxes that permit little insight into how predictions are being made. We tackle this issue by developing a pivotal test to assess the statistical significance of the feature variables of a neural network. We propose a gradient-based test statistic and study its asymptotics using nonparametric techniques. The limiting distribution is given by a mixture of chi-square distributions. The tests enable one to discern the impact of individual variables on the prediction of a neural network. The test statistic can be used to rank variables according to their influence. Simulation results illustrate the computational efficiency and the performance of the test. An empirical application to house price valuation highlights the behavior of the test using actual data.
Sensitivity based Neural Networks Explanations
Dec 03, 2018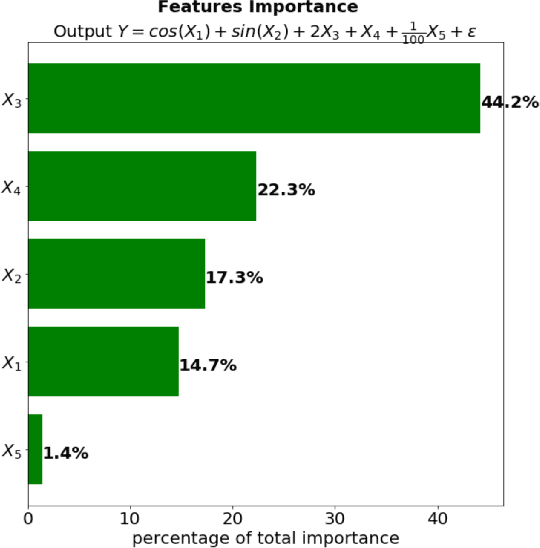
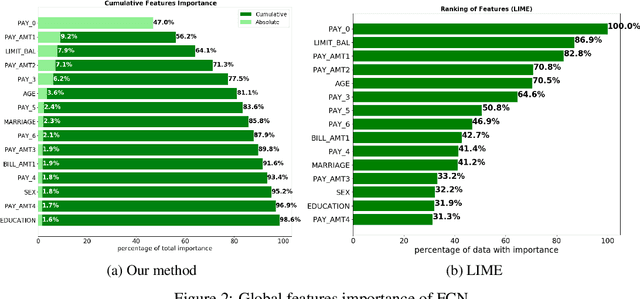
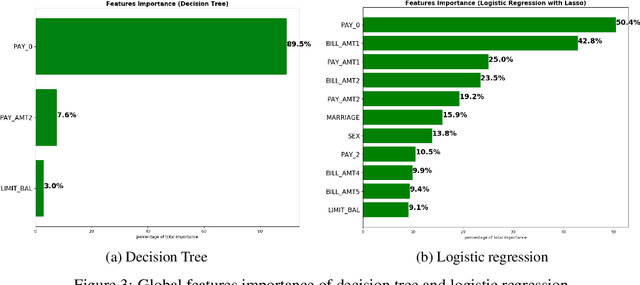
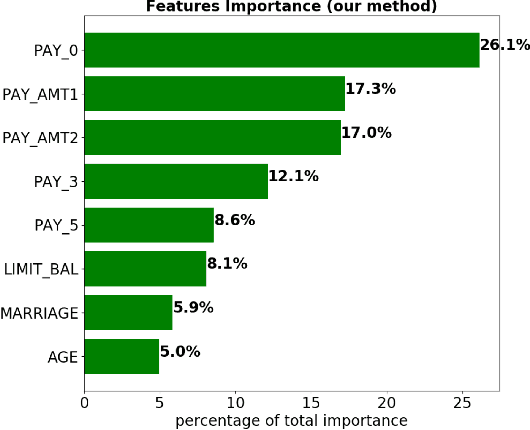
Although neural networks can achieve very high predictive performance on various different tasks such as image recognition or natural language processing, they are often considered as opaque "black boxes". The difficulty of interpreting the predictions of a neural network often prevents its use in fields where explainability is important, such as the financial industry where regulators and auditors often insist on this aspect. In this paper, we present a way to assess the relative input features importance of a neural network based on the sensitivity of the model output with respect to its input. This method has the advantage of being fast to compute, it can provide both global and local levels of explanations and is applicable for many types of neural network architectures. We illustrate the performance of this method on both synthetic and real data and compare it with other interpretation techniques. This method is implemented into an open-source Python package that allows its users to easily generate and visualize explanations for their neural networks.