 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Multi-View Perspective of Light Fields for Low-Light Imaging
Mar 05, 2020


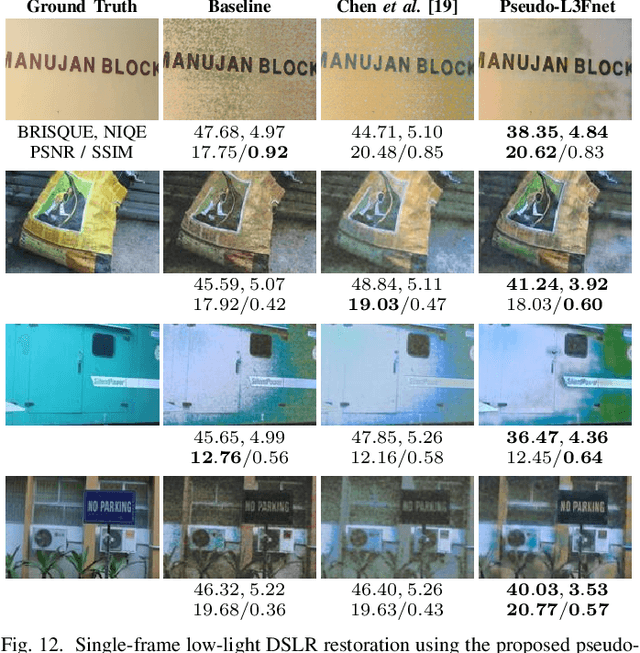
Light Field (LF) offers unique advantages such as post-capture refocusing and depth estimation, but low-light conditions limit these capabilities. To restore low-light LFs we should harness the geometric cues present in different LF views, which is not possible using single-frame low-light enhancement techniques. We, therefore, propose a deep neural network for Low-Light Light Field (L3F) restoration, which we refer to as L3Fnet. The proposed L3Fnet not only performs the necessary visual enhancement of each LF view but also preserves the epipolar geometry across views. We achieve this by adopting a two-stage architecture for L3Fnet. Stage-I looks at all the LF views to encode the LF geometry. This encoded information is then used in Stage-II to reconstruct each LF view. To facilitate learning-based techniques for low-light LF imaging, we collected a comprehensive LF dataset of various scenes. For each scene, we captured four LFs, one with near-optimal exposure and ISO settings and the others at different levels of low-light conditions varying from low to extreme low-light settings. The effectiveness of the proposed L3Fnet is supported by both visual and numerical comparisons on this dataset. To further analyze the performance of low-light reconstruction methods, we also propose an L3F-wild dataset that contains LF captured late at night with almost zero lux values. No ground truth is available in this dataset. To perform well on the L3F-wild dataset, any method must adapt to the light level of the captured scene. To do this we propose a novel pre-processing block that makes L3Fnet robust to various degrees of low-light conditions. Lastly, we show that L3Fnet can also be used for low-light enhancement of single-frame images, despite it being engineered for LF data. We do so by converting the single-frame DSLR image into a form suitable to L3Fnet, which we call as pseudo-LF.
multi-patch aggregation models for resampling detection
Mar 03, 2020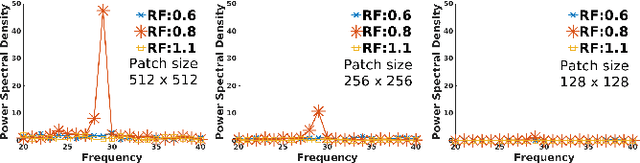

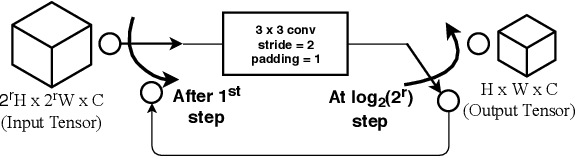
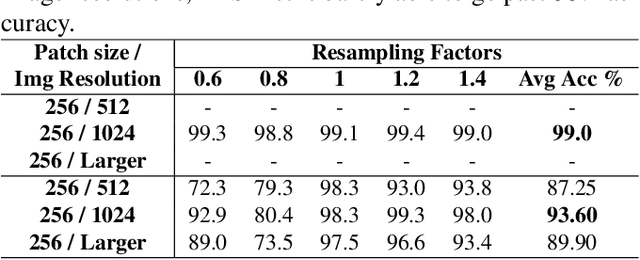
Images captured nowadays are of varying dimensions with smartphones and DSLR's allowing users to choose from a list of available image resolutions. It is therefore imperative for forensic algorithms such as resampling detection to scale well for images of varying dimensions. However, in our experiments, we observed that many state-of-the-art forensic algorithms are sensitive to image size and their performance quickly degenerates when operated on images of diverse dimensions despite re-training them using multiple image sizes. To handle this issue, we propose a novel pooling strategy called ITERATIVE POOLING. This pooling strategy can dynamically adjust input tensors in a discrete without much loss of information as in ROI Max-pooling. This pooling strategy can be used with any of the existing deep models and for demonstration purposes, we show its utility on Resnet-18 for the case of resampling detection a fundamental operation for any image sought of image manipulation. Compared to existing strategies and Max-pooling it gives up to 7-8% improvement on public datasets.
Unsupervised Single Image Underwater Depth Estimation
May 28, 2019

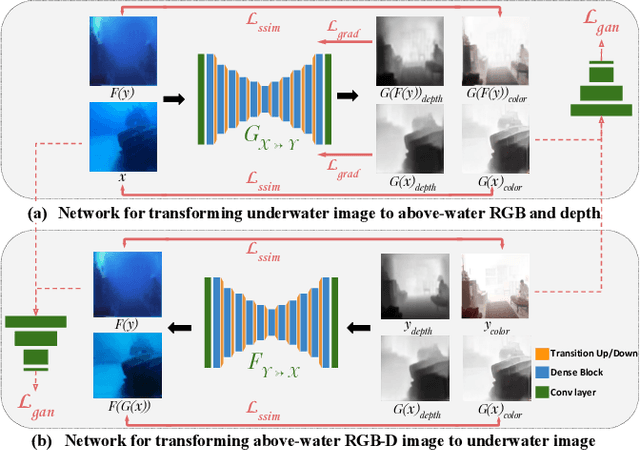

Depth estimation from a single underwater image is one of the most challenging problems and is highly ill-posed. Due to the absence of large generalized underwater depth datasets and the difficulty in obtaining ground truth depth-maps, supervised learning techniques such as direct depth regression cannot be used. In this paper, we propose an unsupervised method for depth estimation from a single underwater image taken `in the wild' by using haze as a cue for depth. Our approach is based on indirect depth-map estimation where we learn the mapping functions between unpaired RGB-D terrestrial images and arbitrary underwater images to estimate the required depth-map. We propose a method which is based on the principles of cycle-consistent learning and uses dense-block based auto-encoders as generator networks. We evaluate and compare our method both quantitatively and qualitatively on various underwater images with diverse attenuation and scattering conditions and show that our method produces state-of-the-art results for unsupervised depth estimation from a single underwater image.
Fully Convolutional Networks for Monocular Retinal Depth Estimation and Optic Disc-Cup Segmentation
Feb 04, 2019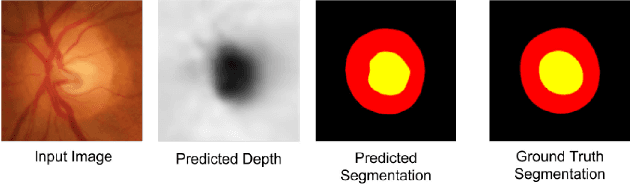
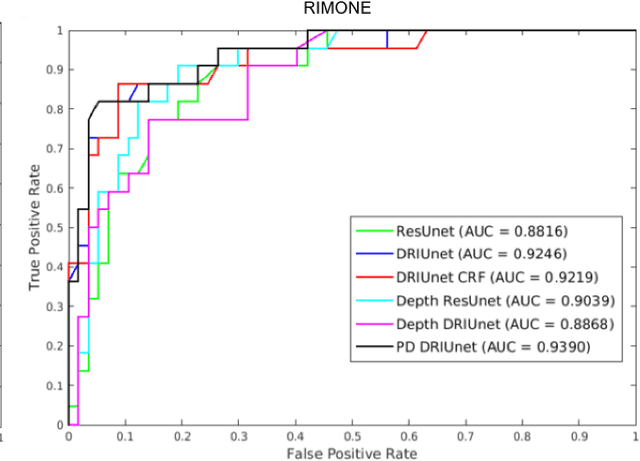
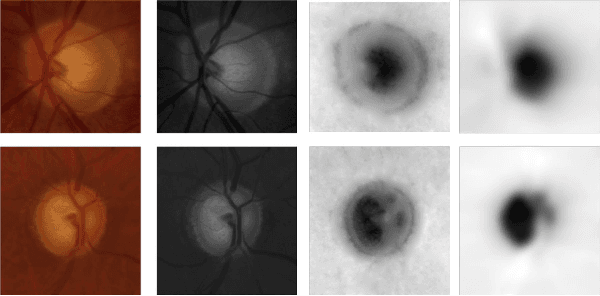

Glaucoma is a serious ocular disorder for which the screening and diagnosis are carried out by the examination of the optic nerve head (ONH). The color fundus image (CFI) is the most common modality used for ocular screening. In CFI, the central r
Neural Decoder for Topological Codes using Pseudo-Inverse of Parity Check Matrix
Jan 24, 2019
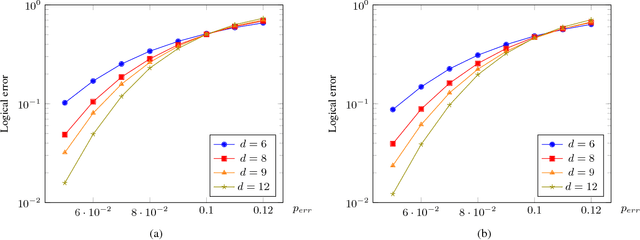
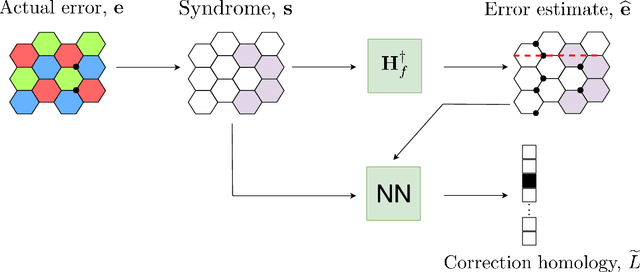
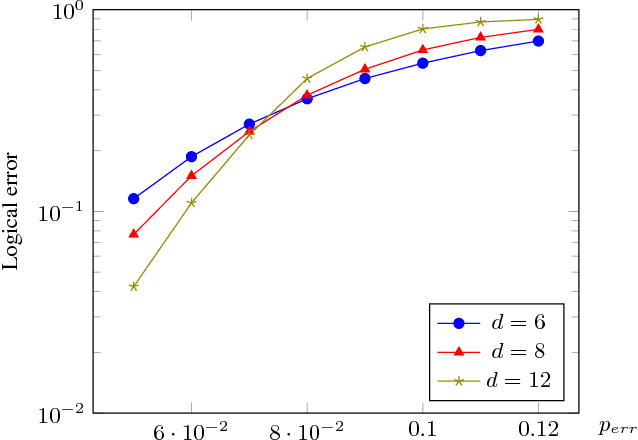
Recent developments in the field of deep learning have motivated many researchers to apply these methods to problems in quantum information. Torlai and Melko first proposed a decoder for surface codes based on neural networks. Since then, many other researchers have applied neural networks to study a variety of problems in the context of decoding. An important development in this regard was due to Varsamopoulos et al. who proposed a two-step decoder using neural networks. Subsequent work of Maskara et al. used the same concept for decoding for various noise models. We propose a similar two-step neural decoder using inverse parity-check matrix for topological color codes. We show that it outperforms the state-of-the-art performance of non-neural decoders for independent Pauli errors noise model on a 2D hexagonal color code. Our final decoder is independent of the noise model and achieves a threshold of $10 \%$. Our result is comparable to the recent work on neural decoder for quantum error correction by Maskara et al.. It appears that our decoder has significant advantages with respect to training cost and complexity of the network for higher lengths when compared to that of Maskara et al.. Our proposed method can also be extended to arbitrary dimension and other stabilizer codes.
A Unified Learning Based Framework for Light Field Reconstruction from Coded Projections
Dec 26, 2018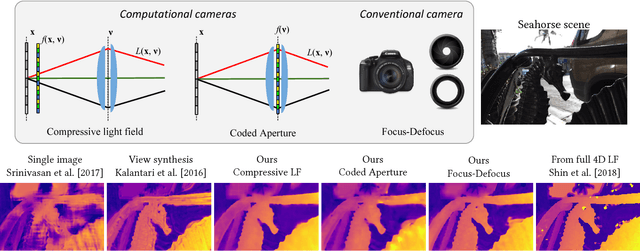
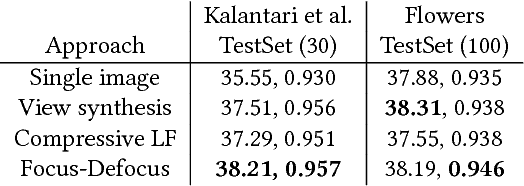
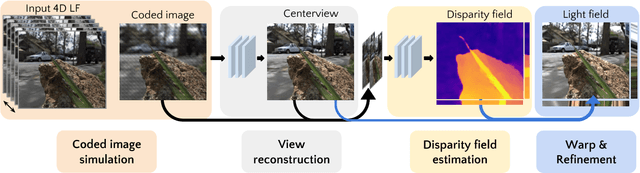
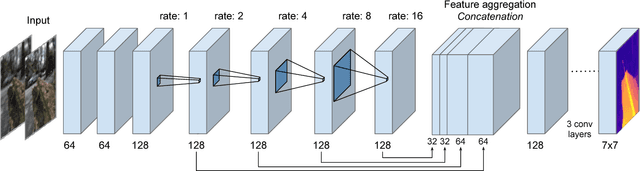
Light field presents a rich way to represent the 3D world by capturing the spatio-angular dimensions of the visual signal. However, the popular way of capturing light field (LF) via a plenoptic camera presents spatio-angular resolution trade-off. Computational imaging techniques such as compressive light field and programmable coded aperture reconstruct full sensor resolution LF from coded projections obtained by multiplexing the incoming spatio-angular light field. Here, we present a unified learning framework that can reconstruct LF from a variety of multiplexing schemes with minimal number of coded images as input. We consider three light field capture schemes: heterodyne capture scheme with code placed near the sensor, coded aperture scheme with code at the camera aperture and finally the dual exposure scheme of capturing a focus-defocus pair where there is no explicit coding. Our algorithm consists of three stages 1) we recover the all-in-focus image from the coded image 2) we estimate the disparity maps for all the LF views from the coded image and the all-in-focus image, 3) we then render the LF by warping the all-in-focus image using disparity maps and refine it. For these three stages we propose three deep neural networks - ViewNet, DispairtyNet and RefineNet. Our reconstructions show that our learning algorithm achieves state-of-the-art results for all the three multiplexing schemes. Especially, our LF reconstructions from focus-defocus pair is comparable to other learning-based view synthesis approaches from multiple images. Thus, our work paves the way for capturing high-resolution LF (~ a megapixel) using conventional cameras such as DSLRs. Please check our supplementary materials $\href{https://docs.google.com/presentation/d/1Vr-F8ZskrSd63tvnLfJ2xmEXY6OBc1Rll3XeOAtc11I/}{online}$ to better appreciate the reconstructed light fields.
Photorealistic Image Reconstruction from Hybrid Intensity and Event based Sensor
Oct 25, 2018
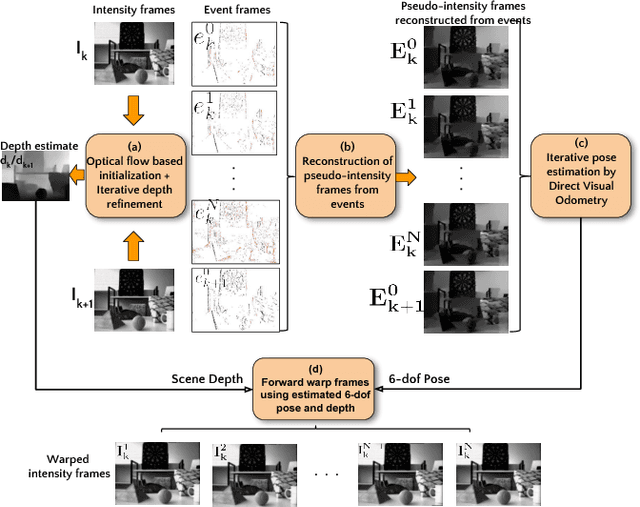
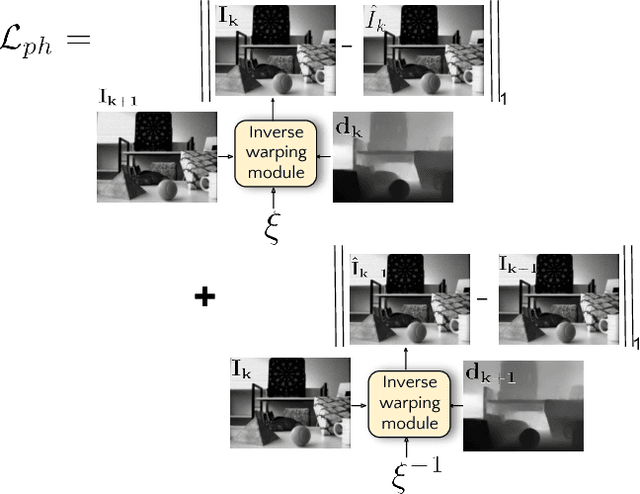
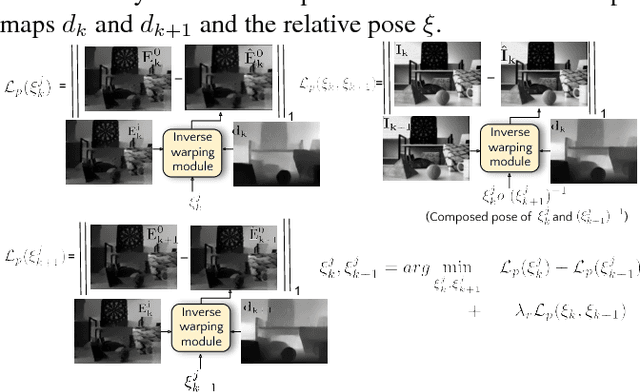
Event sensors output a stream of asynchronous brightness changes (called "events") at a very high temporal rate. Since, these "events" cannot be used directly for traditional computer vision algorithms, many researchers attempted at recovering the intensity information from this stream of events. Although the results are promising, they lack the texture and the consistency of natural videos. We propose to reconstruct photorealistic intensity images from a hybrid sensor consisting of a low frame rate conventional camera along with the event sensor. DAVIS is a commercially available hybrid sensor which bundles the conventional image sensor and the event sensor into a single hardware. To accomplish our task, we use the low frame rate intensity images and warp them to the temporally dense locations of the event data by estimating a spatially dense scene depth and temporally dense sensor ego-motion. We thereby obtain temporally dense photorealisitic images which would have been very difficult by using only either the event sensor or the conventional low frame-rate image sensor. In addition, we also obtain spatio-temporally dense scene flow as a by product of estimating spatially dense depth map and temporally dense sensor ego-motion.
Phase retrieval for Fourier Ptychography under varying amount of measurements
May 09, 2018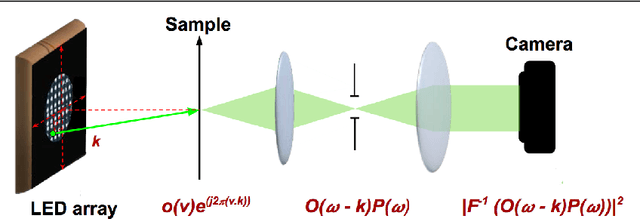



Fourier Ptychography is a recently proposed imaging technique that yields high-resolution images by computationally transcending the diffraction blur of an optical system. At the crux of this method is the phase retrieval algorithm, which is used for computationally stitching together low-resolution images taken under varying illumination angles of a coherent light source. However, the traditional iterative phase retrieval technique relies heavily on the initialization and also need a good amount of overlap in the Fourier domain for the successively captured low-resolution images, thus increasing the acquisition time and data. We show that an auto-encoder based architecture can be adaptively trained for phase retrieval under both low overlap, where traditional techniques completely fail, and at higher levels of overlap. For the low overlap case we show that a supervised deep learning technique using an autoencoder generator is a good choice for solving the Fourier ptychography problem. And for the high overlap case, we show that optimizing the generator for reducing the forward model error is an appropriate choice. Using simulations for the challenging case of uncorrelated phase and amplitude, we show that our method outperforms many of the previously proposed Fourier ptychography phase retrieval techniques.
Learning Light Field Reconstruction from a Single Coded Image
Apr 26, 2018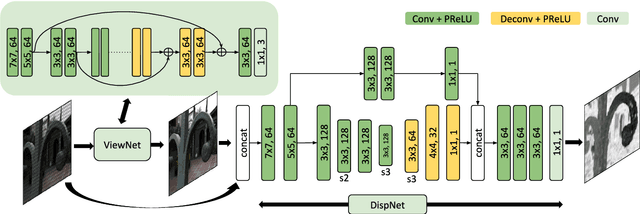



Light field imaging is a rich way of representing the 3D world around us. However, due to limited sensor resolution capturing light field data inherently poses spatio-angular resolution trade-off. In this paper, we propose a deep learning based solution to tackle the resolution trade-off. Specifically, we reconstruct full sensor resolution light field from a single coded image. We propose to do this in three stages 1) reconstruction of center view from the coded image 2) estimating disparity map from the coded image and center view 3) warping center view using the disparity to generate light field. We propose three neural networks for these stages. Our disparity estimation network is trained in an unsupervised manner alleviating the need for ground truth disparity. Our results demonstrate better recovery of parallax from the coded image. Also, we get better results than dictionary learning based approaches both qualitatively and quatitatively.
Solving Inverse Computational Imaging Problems using Deep Pixel-level Prior
Apr 24, 2018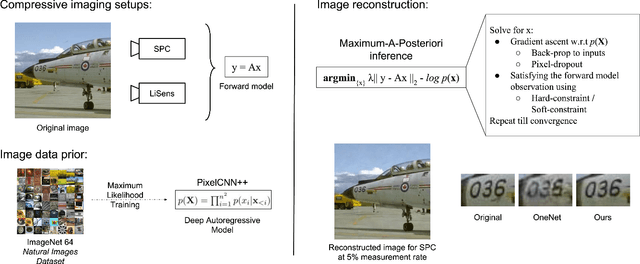



Signal reconstruction is a challenging aspect of computational imaging as it often involves solving ill-posed inverse problems. Recently, deep feed-forward neural networks have led to state-of-the-art results in solving various inverse imaging problems. However, being task specific, these networks have to be learned for each inverse problem. On the other hand, a more flexible approach would be to learn a deep generative model once and then use it as a signal prior for solving various inverse problems. We show that among the various state of the art deep generative models, autoregressive models are especially suitable for our purpose for the following reasons. First, they explicitly model the pixel level dependencies and hence are capable of reconstructing low-level details such as texture patterns and edges better. Second, they provide an explicit expression for the image prior which can then be used for MAP based inference along with the forward model. Third, they can model long range dependencies in images which make them ideal for handling global multiplexing as encountered in various compressive imaging systems. We demonstrate the efficacy of our proposed approach in solving three computational imaging problems: Single Pixel Camera (SPC), LiSens and FlatCam. For both real and simulated cases, we obtain better reconstructions than the state-of-the-art methods in terms of perceptual and quantitative metrics.