 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples and Metrics
Jul 15, 2020
Adversarial examples are a type of attack on machine learning (ML) systems which cause misclassification of inputs. Achieving robustness against adversarial examples is crucial to apply ML in the real world. While most prior work on adversarial examples is empirical, a recent line of work establishes fundamental limitations of robust classification based on cryptographic hardness. Most positive and negative results in this field however assume that there is a fixed target metric which constrains the adversary, and we argue that this is often an unrealistic assumption. In this work we study the limitations of robust classification if the target metric is uncertain. Concretely, we construct a classification problem, which admits robust classification by a small classifier if the target metric is known at the time the model is trained, but for which robust classification is impossible for small classifiers if the target metric is chosen after the fact. In the process, we explore a novel connection between hardness of robust classification and bounded storage model cryptography.
A new measure for overfitting and its implications for backdooring of deep learning
Jun 18, 2020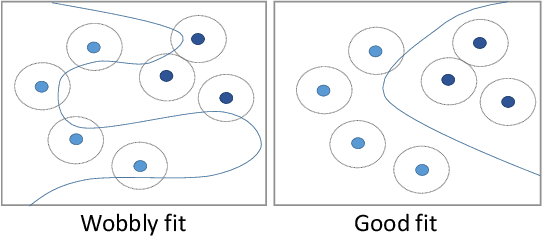
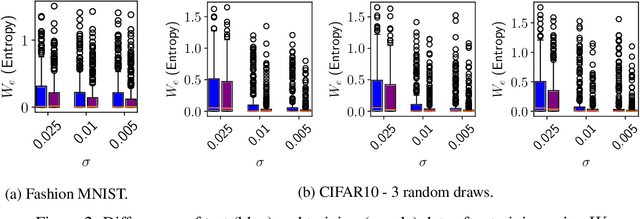
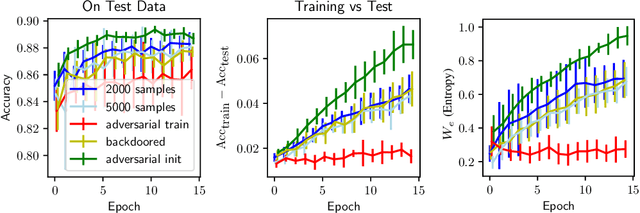
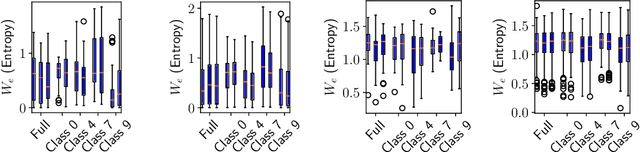
Overfitting describes the phenomenon that a machine learning model fits the given data instead of learning the underlying distribution. Existing approaches are computationally expensive, require large amounts of labeled data, consider overfitting global phenomenon, and often compute a single measurement. Instead, we propose a local measurement around a small number of unlabeled test points to obtain features of overfitting. Our extensive evaluation shows that the measure can reflect the model's different fit of training and test data, identify changes of the fit during training, and even suggest different fit among classes. We further apply our method to verify if backdoors rely on overfitting, a common claim in security of deep learning. Instead, we find that backdoors rely on underfitting. Our findings also provide evidence that even unbackdoored neural networks contain patterns similar to backdoors that are reliably classified as one class.
How many winning tickets are there in one DNN?
Jun 12, 2020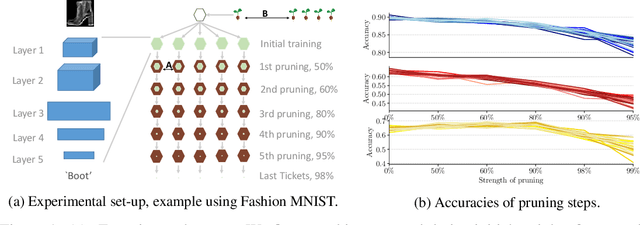
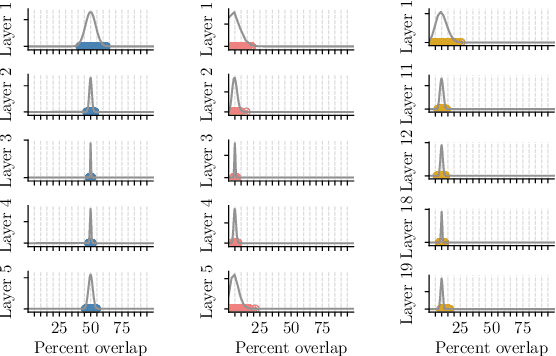
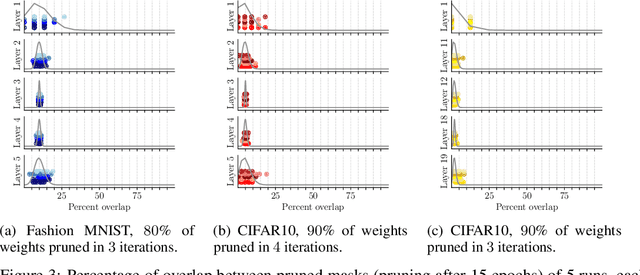
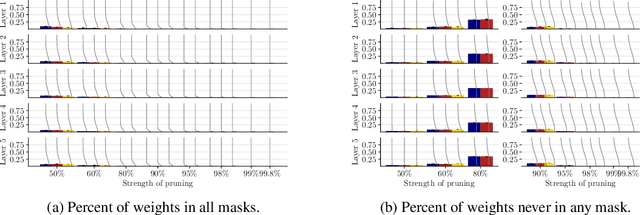
The recent lottery ticket hypothesis proposes that there is one sub-network that matches the accuracy of the original network when trained in isolation. We show that instead each network contains several winning tickets, even if the initial weights are fixed. The resulting winning sub-networks are not instances of the same network under weight space symmetry, and show no overlap or correlation significantly larger than expected by chance. If randomness during training is decreased, overlaps higher than chance occur, even if the networks are trained on different tasks. We conclude that there is rather a distribution over capable sub-networks, as opposed to a single winning ticket.
Adversarial Vulnerability Bounds for Gaussian Process Classification
Sep 19, 2019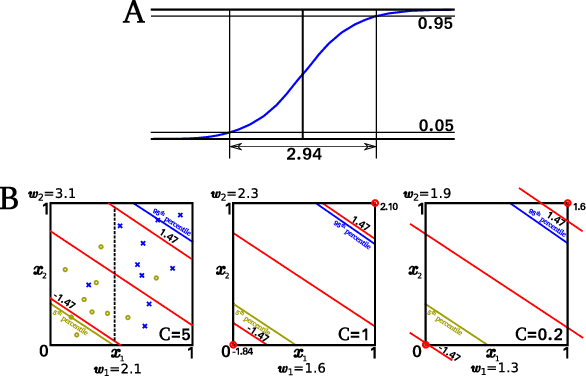

Machine learning (ML) classification is increasingly used in safety-critical systems. Protecting ML classifiers from adversarial examples is crucial. We propose that the main threat is that of an attacker perturbing a confidently classified input to produce a confident misclassification. To protect against this we devise an adversarial bound (AB) for a Gaussian process classifier, that holds for the entire input domain, bounding the potential for any future adversarial method to cause such misclassification. This is a formal guarantee of robustness, not just an empirically derived result. We investigate how to configure the classifier to maximise the bound, including the use of a sparse approximation, leading to the method producing a practical, useful and provably robust classifier, which we test using a variety of datasets.
Adversarial Initialization -- when your network performs the way I want
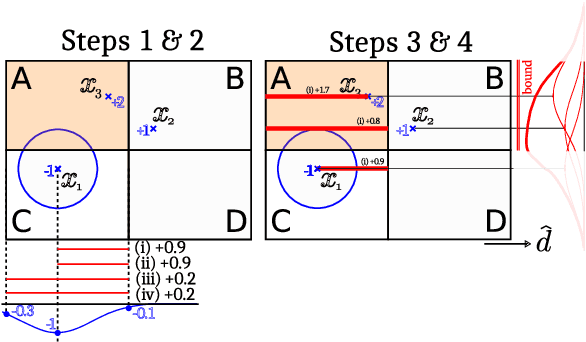
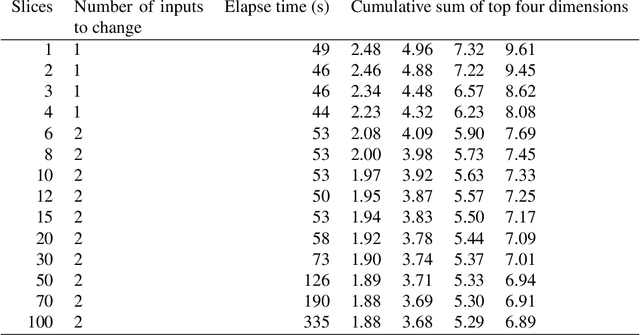
Feb 08, 2019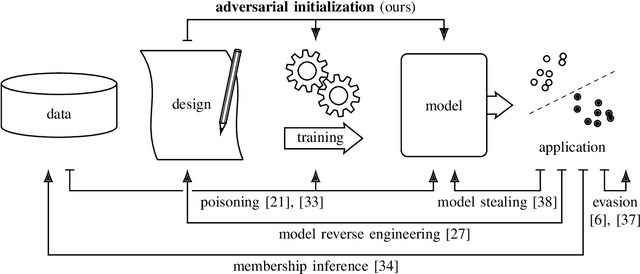
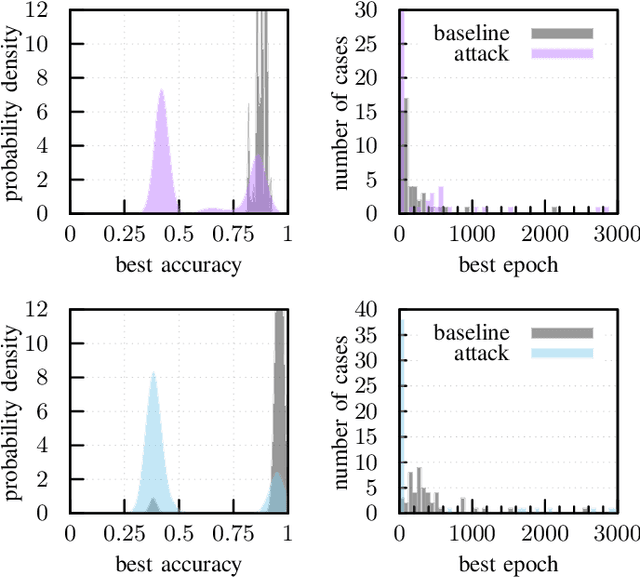
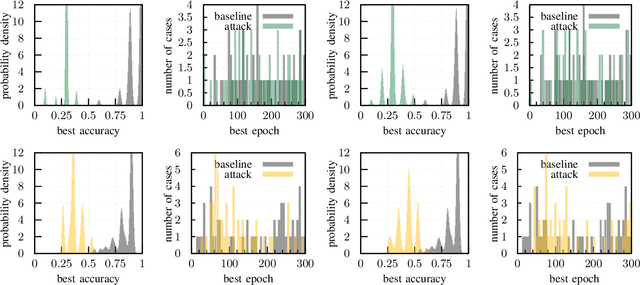
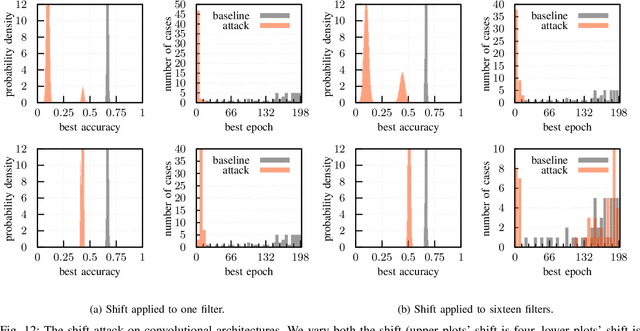
The increase in computational power and available data has fueled a wide deployment of deep learning in production environments. Despite their successes, deep architectures are still poorly understood and costly to train. We demonstrate in this paper how a simple recipe enables a market player to harm or delay the development of a competing product. Such a threat model is novel and has not been considered so far. We derive the corresponding attacks and show their efficacy both formally and empirically. These attacks only require access to the initial, untrained weights of a network. No knowledge of the problem domain and the data used by the victim is needed. On the initial weights, a mere permutation is sufficient to limit the achieved accuracy to for example 50% on the MNIST dataset or double the needed training time. While we can show straightforward ways to mitigate the attacks, the respective steps are not part of the standard procedure taken by developers so far.
The Limitations of Model Uncertainty in Adversarial Settings
Dec 06, 2018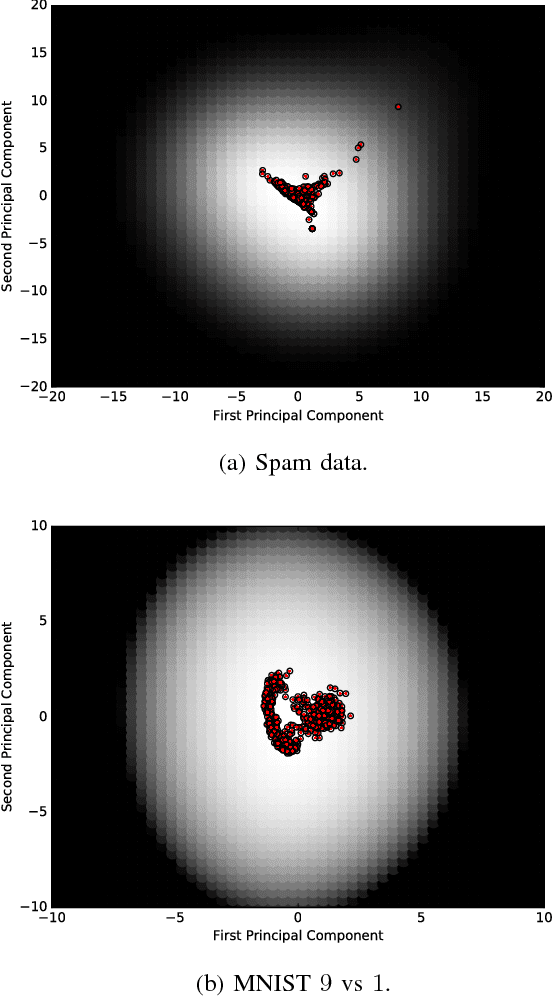
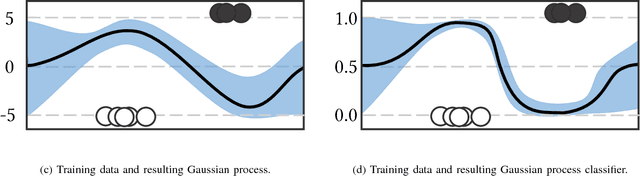
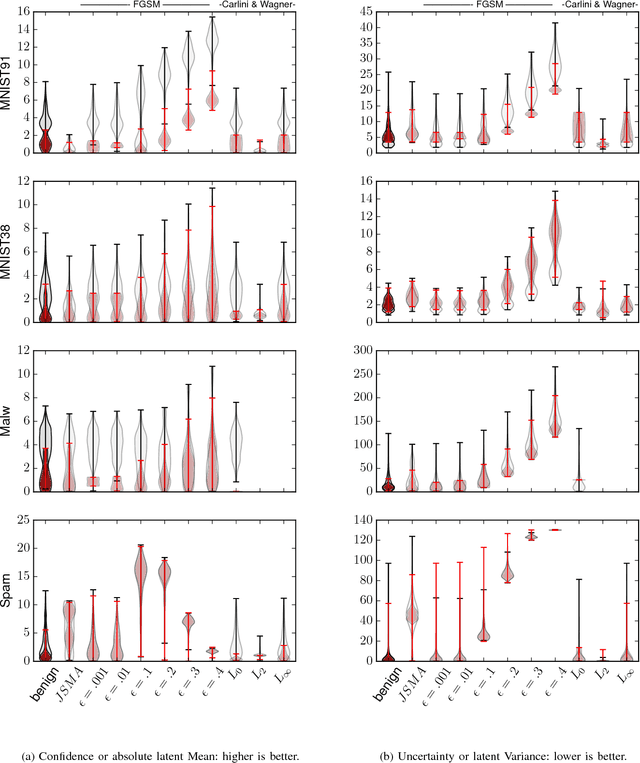
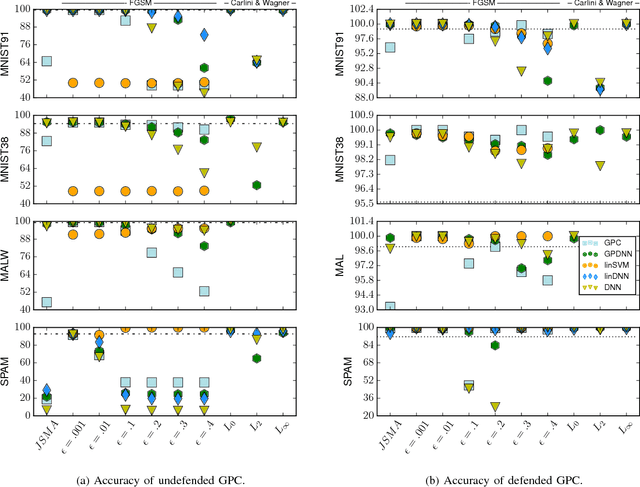
Machine learning models are vulnerable to adversarial examples: minor perturbations to input samples intended to deliberately cause misclassification. Many defenses have led to an arms race-we thus study a promising, recent trend in this setting, Bayesian uncertainty measures. These measures allow a classifier to provide principled confidence and uncertainty for an input, where the latter refers to how usual the input is. We focus on Gaussian processes (GP), a classifier providing such principled uncertainty and confidence measures. Using correctly classified benign data as comparison, GP's intrinsic uncertainty and confidence deviate for misclassified benign samples and misclassified adversarial examples. We therefore introduce high-confidence-low-uncertainty adversarial examples: adversarial examples crafted maximizing GP confidence and minimizing GP uncertainty. Visual inspection shows HCLU adversarial examples are malicious, and resemble the original rather than the target class. HCLU adversarial examples also transfer to other classifiers. We focus on transferability to other algorithms providing uncertainty measures, and find that a Bayesian neural network confidently misclassifies HCLU adversarial examples. We conclude that uncertainty and confidence, even in the Bayesian sense, can be circumvented by both white-box and black-box attackers.
MLCapsule: Guarded Offline Deployment of Machine Learning as a Service
Aug 01, 2018

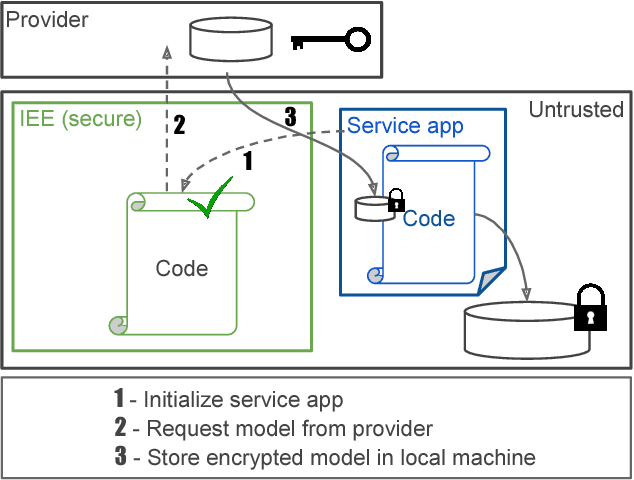
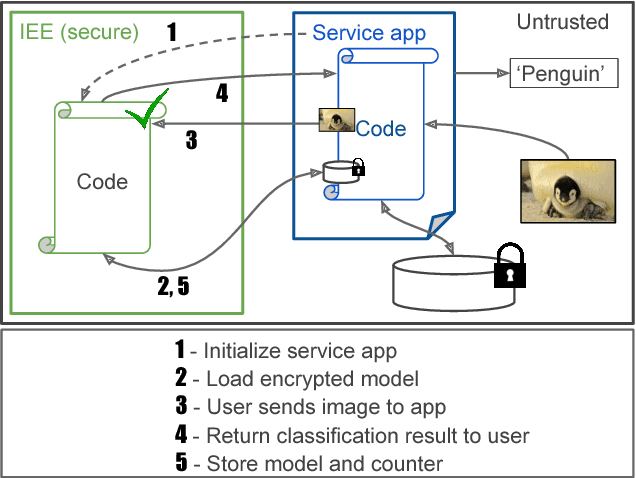
With the widespread use of machine learning (ML) techniques, ML as a service has become increasingly popular. In this setting, an ML model resides on a server and users can query the model with their data via an API. However, if the user's input is sensitive, sending it to the server is not an option. Equally, the service provider does not want to share the model by sending it to the client for protecting its intellectual property and pay-per-query business model. In this paper, we propose MLCapsule, a guarded offline deployment of machine learning as a service. MLCapsule executes the machine learning model locally on the user's client and therefore the data never leaves the client. Meanwhile, MLCapsule offers the service provider the same level of control and security of its model as the commonly used server-side execution. In addition, MLCapsule is applicable to offline applications that require local execution. Beyond protecting against direct model access, we demonstrate that MLCapsule allows for implementing defenses against advanced attacks on machine learning models such as model stealing/reverse engineering and membership inference.
Killing Three Birds with one Gaussian Process: Analyzing Attack Vectors on Classification
Jun 06, 2018
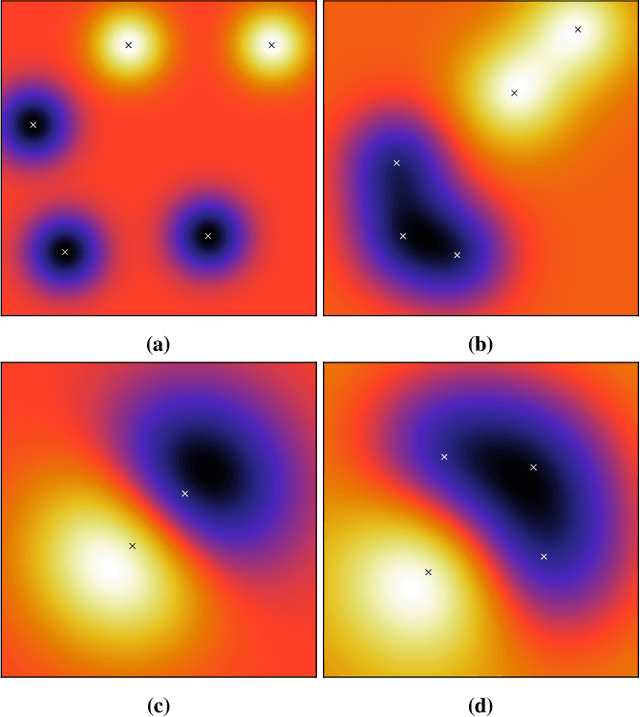
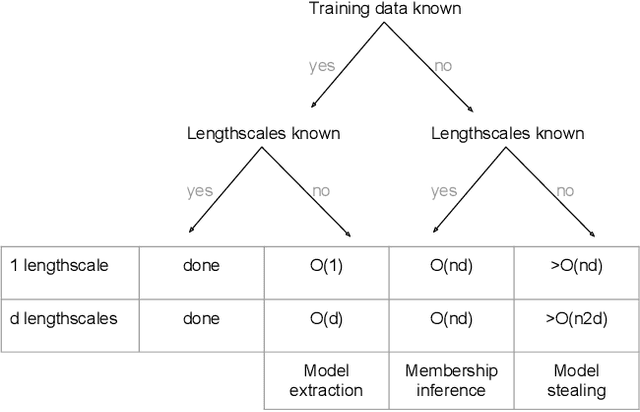
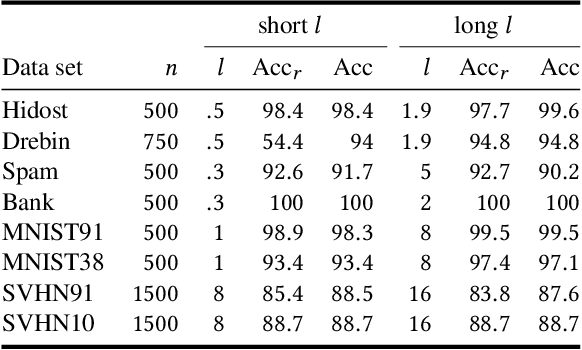
The wide usage of Machine Learning (ML) has lead to research on the attack vectors and vulnerability of these systems. The defenses in this area are however still an open problem, and often lead to an arms race. We define a naive, secure classifier at test time and show that a Gaussian Process (GP) is an instance of this classifier given two assumptions: one concerns the distances in the training data, the other rejection at test time. Using these assumptions, we are able to show that a classifier is either secure, or generalizes and thus learns. Our analysis also points towards another factor influencing robustness, the curvature of the classifier. This connection is not unknown for linear models, but GP offer an ideal framework to study this relationship for nonlinear classifiers. We evaluate on five security and two computer vision datasets applying test and training time attacks and membership inference. We show that we only change which attacks are needed to succeed, instead of alleviating the threat. Only for membership inference, there is a setting in which attacks are unsuccessful (<10% increase in accuracy over random guess). Given these results, we define a classification scheme based on voting, ParGP. This allows us to decide how many points vote and how large the agreement on a class has to be. This ensures a classification output only in cases when there is evidence for a decision, where evidence is parametrized. We evaluate this scheme and obtain promising results.
How Wrong Am I? - Studying Adversarial Examples and their Impact on Uncertainty in Gaussian Process Machine Learning Models
Feb 16, 2018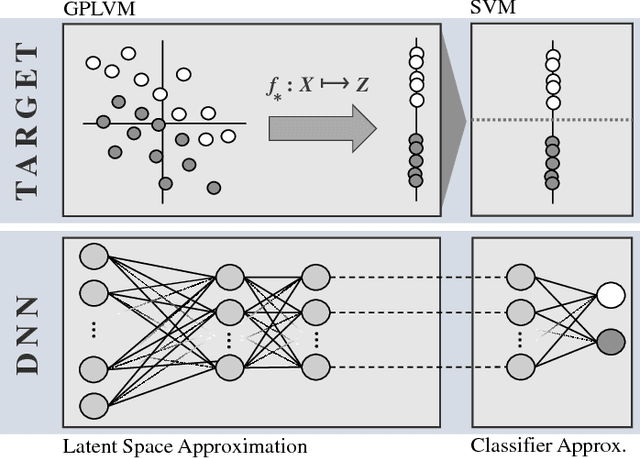
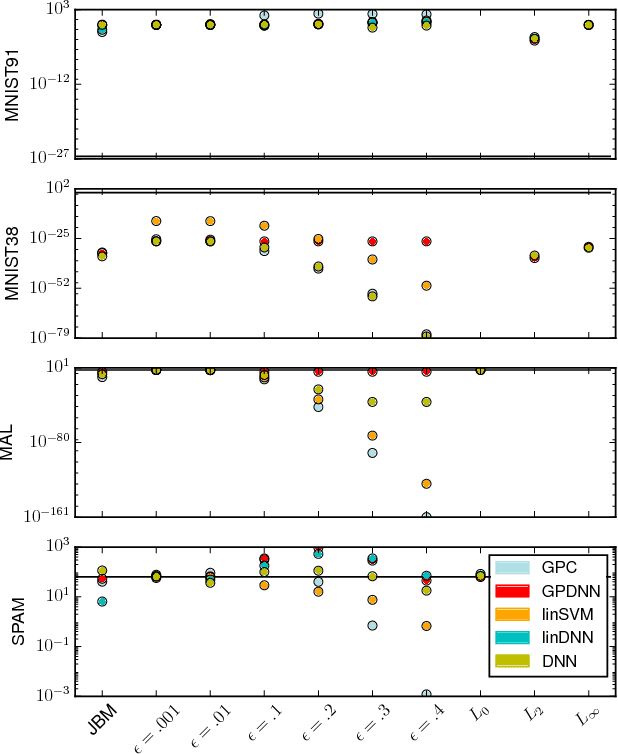
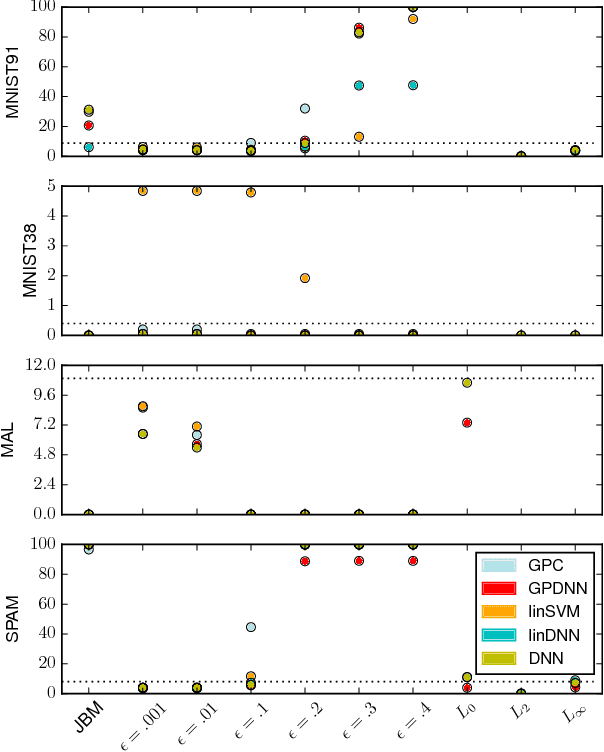
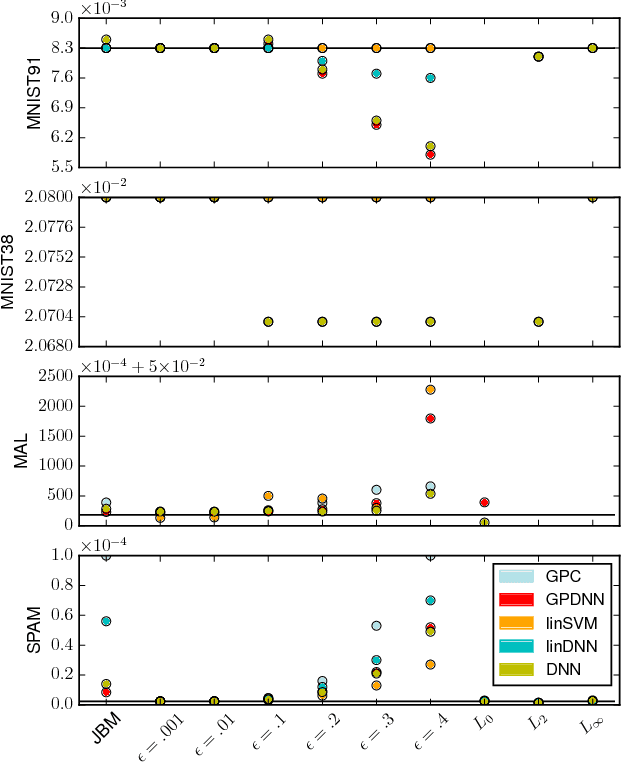
Machine learning models are vulnerable to Adversarial Examples: minor perturbations to input samples intended to deliberately cause misclassification. Current defenses against adversarial examples, especially for Deep Neural Networks (DNN), are primarily derived from empirical developments, and their security guarantees are often only justified retroactively. Many defenses therefore rely on hidden assumptions that are subsequently subverted by increasingly elaborate attacks. This is not surprising: deep learning notoriously lacks a comprehensive mathematical framework to provide meaningful guarantees. In this paper, we leverage Gaussian Processes to investigate adversarial examples in the framework of Bayesian inference. Across different models and datasets, we find deviating levels of uncertainty reflect the perturbation introduced to benign samples by state-of-the-art attacks, including novel white-box attacks on Gaussian Processes. Our experiments demonstrate that even unoptimized uncertainty thresholds already reject adversarial examples in many scenarios.
On the (Statistical) Detection of Adversarial Examples
Oct 17, 2017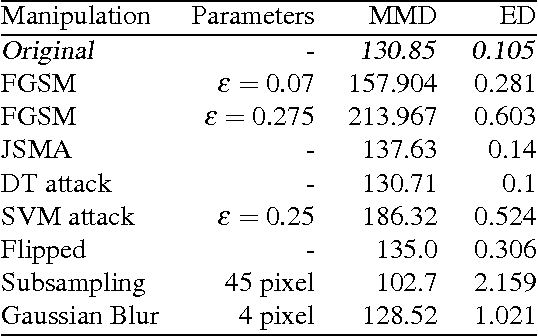
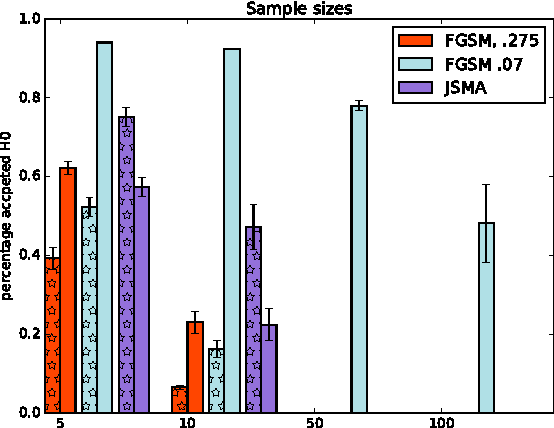

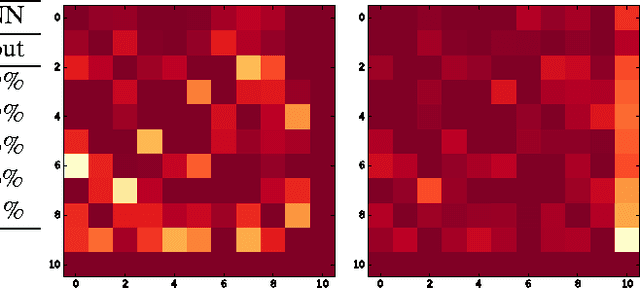
Machine Learning (ML) models are applied in a variety of tasks such as network intrusion detection or Malware classification. Yet, these models are vulnerable to a class of malicious inputs known as adversarial examples. These are slightly perturbed inputs that are classified incorrectly by the ML model. The mitigation of these adversarial inputs remains an open problem. As a step towards understanding adversarial examples, we show that they are not drawn from the same distribution than the original data, and can thus be detected using statistical tests. Using thus knowledge, we introduce a complimentary approach to identify specific inputs that are adversarial. Specifically, we augment our ML model with an additional output, in which the model is trained to classify all adversarial inputs. We evaluate our approach on multiple adversarial example crafting methods (including the fast gradient sign and saliency map methods) with several datasets. The statistical test flags sample sets containing adversarial inputs confidently at sample sizes between 10 and 100 data points. Furthermore, our augmented model either detects adversarial examples as outliers with high accuracy (> 80%) or increases the adversary's cost - the perturbation added - by more than 150%. In this way, we show that statistical properties of adversarial examples are essential to their detection.