 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling the Low-resource Challenge for Canonical Segmentation
Oct 06, 2020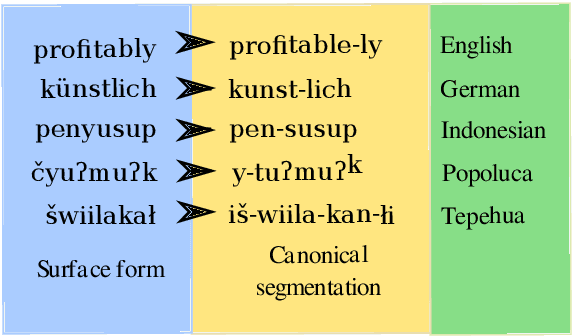
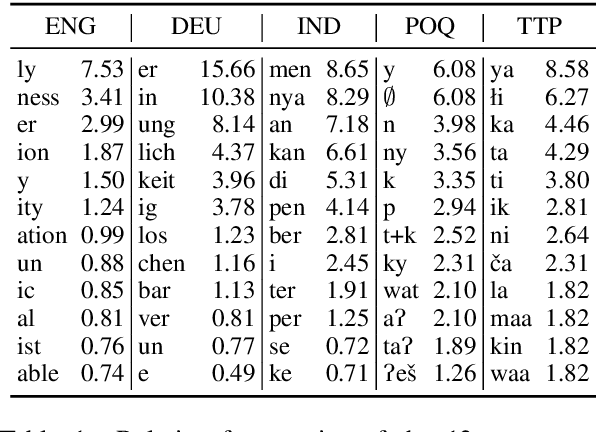
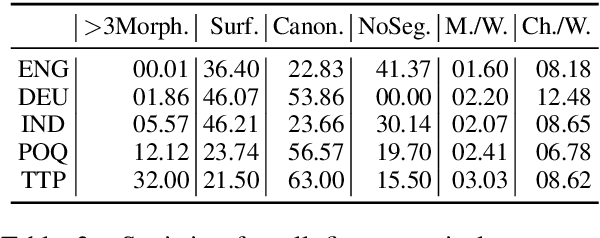
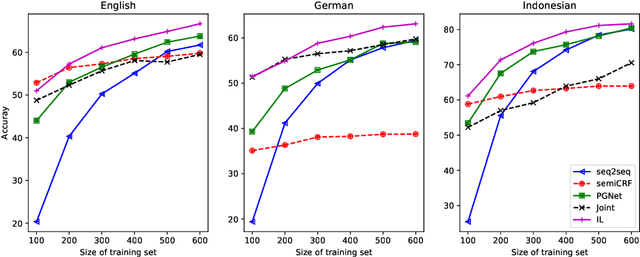
Canonical morphological segmentation consists of dividing words into their standardized morphemes. Here, we are interested in approaches for the task when training data is limited. We compare model performance in a simulated low-resource setting for the high-resource languages German, English, and Indonesian to experiments on new datasets for the truly low-resource languages Popoluca and Tepehua. We explore two new models for the task, borrowing from the closely related area of morphological generation: an LSTM pointer-generator and a sequence-to-sequence model with hard monotonic attention trained with imitation learning. We find that, in the low-resource setting, the novel approaches outperform existing ones on all languages by up to 11.4% accuracy. However, while accuracy in emulated low-resource scenarios is over 50% for all languages, for the truly low-resource languages Popoluca and Tepehua, our best model only obtains 37.4% and 28.4% accuracy, respectively. Thus, we conclude that canonical segmentation is still a challenging task for low-resource languages.
Acrostic Poem Generation
Oct 05, 2020
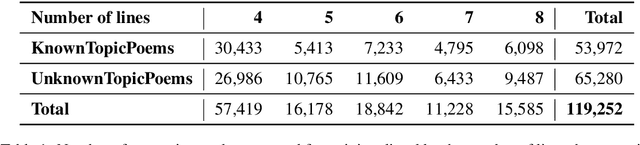
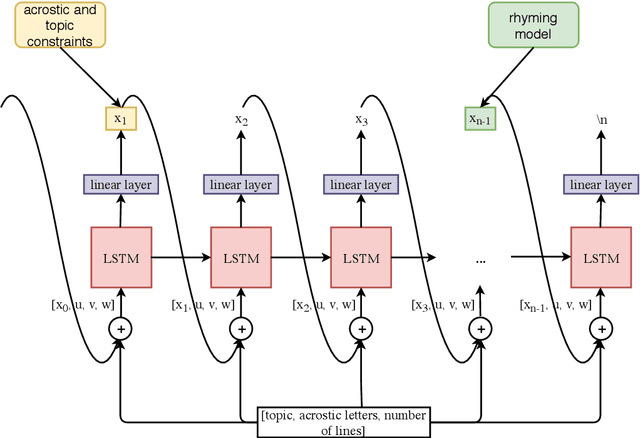
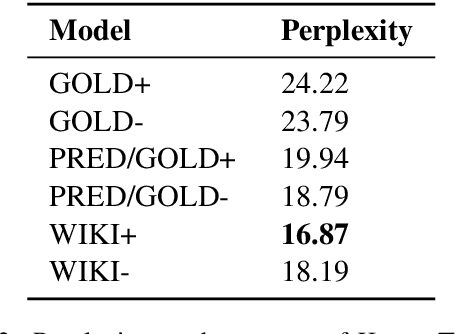
We propose a new task in the area of computational creativity: acrostic poem generation in English. Acrostic poems are poems that contain a hidden message; typically, the first letter of each line spells out a word or short phrase. We define the task as a generation task with multiple constraints: given an input word, 1) the initial letters of each line should spell out the provided word, 2) the poem's semantics should also relate to it, and 3) the poem should conform to a rhyming scheme. We further provide a baseline model for the task, which consists of a conditional neural language model in combination with a neural rhyming model. Since no dedicated datasets for acrostic poem generation exist, we create training data for our task by first training a separate topic prediction model on a small set of topic-annotated poems and then predicting topics for additional poems. Our experiments show that the acrostic poems generated by our baseline are received well by humans and do not lose much quality due to the additional constraints. Last, we confirm that poems generated by our model are indeed closely related to the provided prompts, and that pretraining on Wikipedia can boost performance.
The NYU-CUBoulder Systems for SIGMORPHON 2020 Task 0 and Task 2
Jun 21, 2020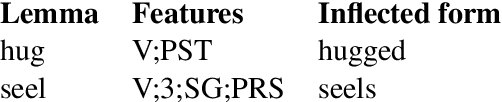
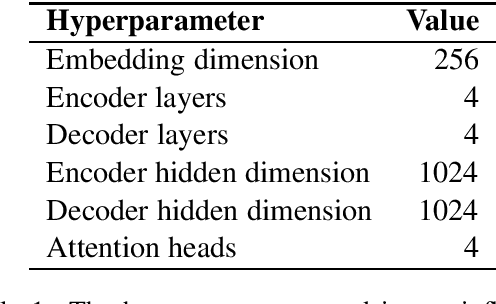

We describe the NYU-CUBoulder systems for the SIGMORPHON 2020 Task 0 on typologically diverse morphological inflection and Task 2 on unsupervised morphological paradigm completion. The former consists of generating morphological inflections from a lemma and a set of morphosyntactic features describing the target form. The latter requires generating entire paradigms for a set of given lemmas from raw text alone. We model morphological inflection as a sequence-to-sequence problem, where the input is the sequence of the lemma's characters with morphological tags, and the output is the sequence of the inflected form's characters. First, we apply a transformer model to the task. Second, as inflected forms share most characters with the lemma, we further propose a pointer-generator transformer model to allow easy copying of input characters. Our best performing system for Task 0 is placed 6th out of 23 systems. We further use our inflection systems as subcomponents of approaches for Task 2. Our best performing system for Task 2 is the 2nd best out of 7 submissions.
The SIGMORPHON 2020 Shared Task on Unsupervised Morphological Paradigm Completion
May 28, 2020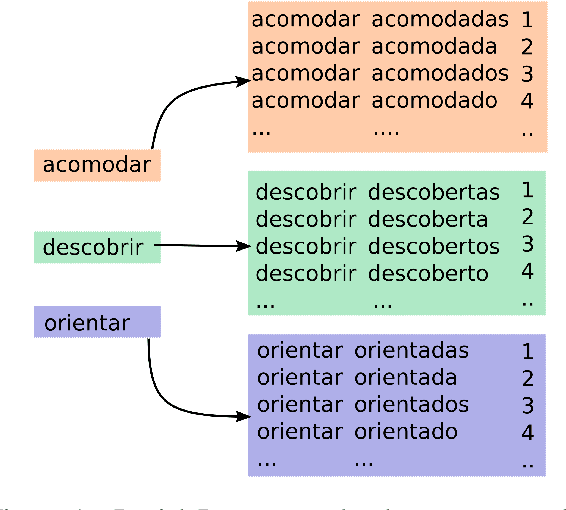
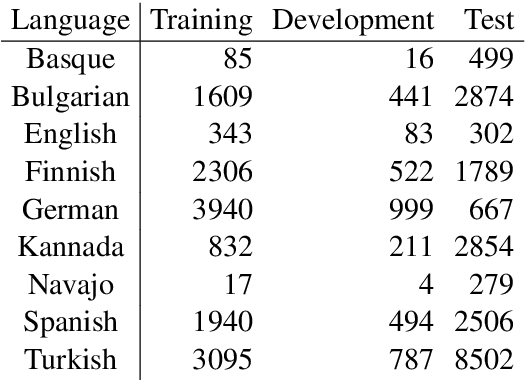
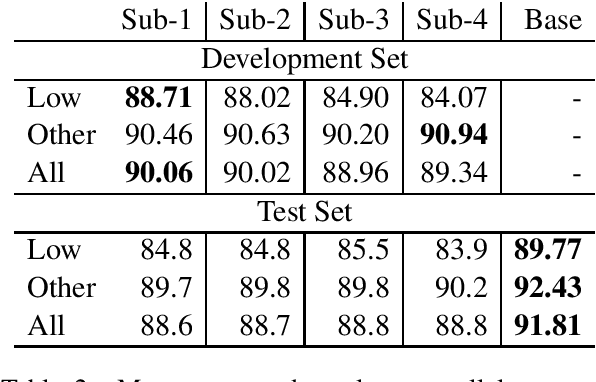
In this paper, we describe the findings of the SIGMORPHON 2020 shared task on unsupervised morphological paradigm completion (SIGMORPHON 2020 Task 2), a novel task in the field of inflectional morphology. Participants were asked to submit systems which take raw text and a list of lemmas as input, and output all inflected forms, i.e., the entire morphological paradigm, of each lemma. In order to simulate a realistic use case, we first released data for 5 development languages. However, systems were officially evaluated on 9 surprise languages, which were only revealed a few days before the submission deadline. We provided a modular baseline system, which is a pipeline of 4 components. 3 teams submitted a total of 7 systems, but, surprisingly, none of the submitted systems was able to improve over the baseline on average over all 9 test languages. Only on 3 languages did a submitted system obtain the best results. This shows that unsupervised morphological paradigm completion is still largely unsolved. We present an analysis here, so that this shared task will ground further research on the topic.
Self-Training for Unsupervised Parsing with PRPN
May 27, 2020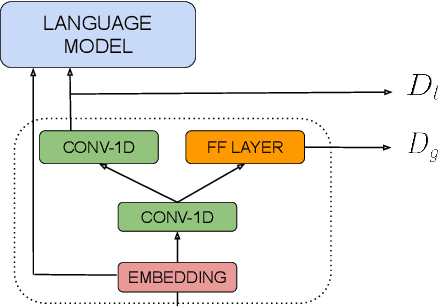
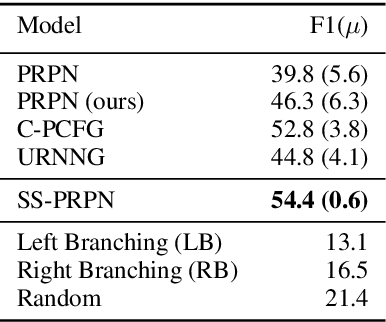
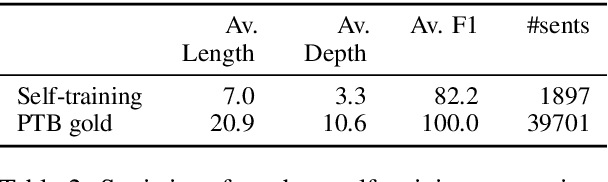
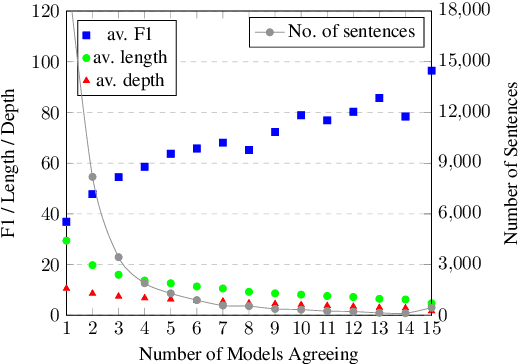
Neural unsupervised parsing (UP) models learn to parse without access to syntactic annotations, while being optimized for another task like language modeling. In this work, we propose self-training for neural UP models: we leverage aggregated annotations predicted by copies of our model as supervision for future copies. To be able to use our model's predictions during training, we extend a recent neural UP architecture, the PRPN (Shen et al., 2018a) such that it can be trained in a semi-supervised fashion. We then add examples with parses predicted by our model to our unlabeled UP training data. Our self-trained model outperforms the PRPN by 8.1% F1 and the previous state of the art by 1.6% F1. In addition, we show that our architecture can also be helpful for semi-supervised parsing in ultra-low-resource settings.
English Intermediate-Task Training Improves Zero-Shot Cross-Lingual Transfer Too
May 26, 2020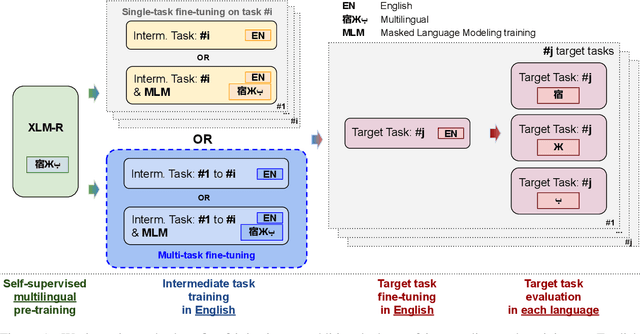
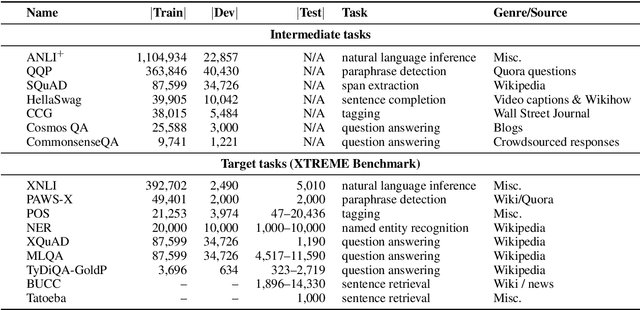
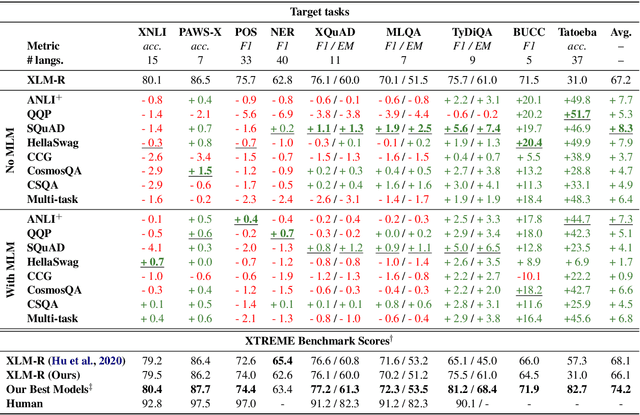

Intermediate-task training has been shown to substantially improve pretrained model performance on many language understanding tasks, at least in monolingual English settings. Here, we investigate whether English intermediate-task training is still helpful on non-English target tasks in a zero-shot cross-lingual setting. Using a set of 7 intermediate language understanding tasks, we evaluate intermediate-task transfer in a zero-shot cross-lingual setting on 9 target tasks from the XTREME benchmark. Intermediate-task training yields large improvements on the BUCC and Tatoeba tasks that use model representations directly without training, and moderate improvements on question-answering target tasks. Using SQuAD for intermediate training achieves the best results across target tasks, with an average improvement of 8.4 points on development sets. Selecting the best intermediate task model for each target task, we obtain a 6.1 point improvement over XLM-R Large on the XTREME benchmark, setting a new state of the art. Finally, we show that neither multi-task intermediate-task training nor continuing multilingual MLM during intermediate-task training offer significant improvements.
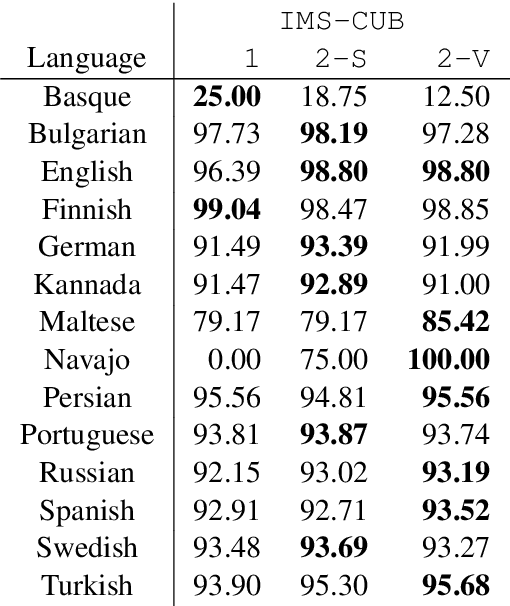
The IMS-CUBoulder System for the SIGMORPHON 2020 Shared Task on Unsupervised Morphological Paradigm Completion
May 25, 2020In this paper, we present the systems of the University of Stuttgart IMS and the University of Colorado Boulder (IMS-CUBoulder) for SIGMORPHON 2020 Task 2 on unsupervised morphological paradigm completion (Kann et al., 2020). The task consists of generating the morphological paradigms of a set of lemmas, given only the lemmas themselves and unlabeled text. Our proposed system is a modified version of the baseline introduced together with the task. In particular, we experiment with substituting the inflection generation component with an LSTM sequence-to-sequence model and an LSTM pointer-generator network. Our pointer-generator system obtains the best score of all seven submitted systems on average over all languages, and outperforms the official baseline, which was best overall, on Bulgarian and Kannada.
Unsupervised Morphological Paradigm Completion
May 20, 2020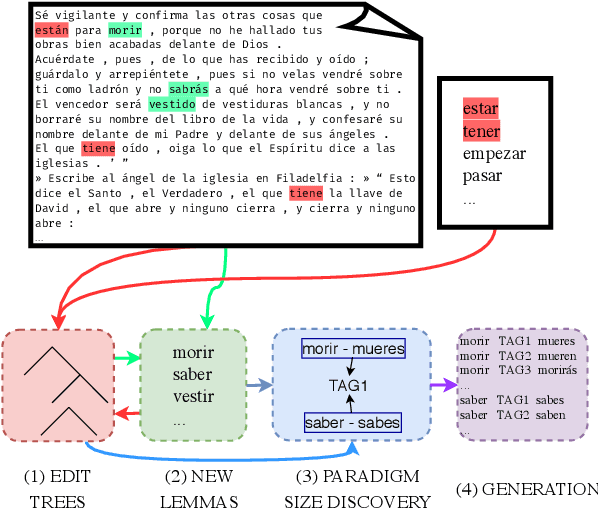
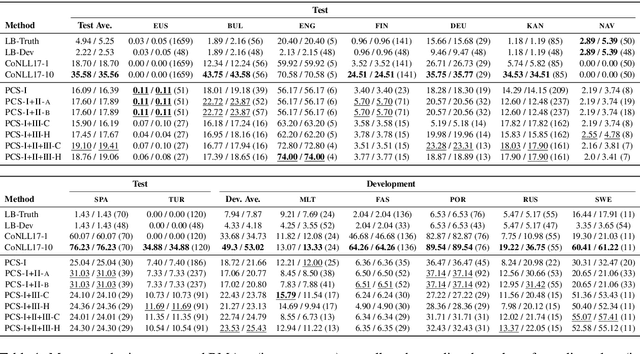
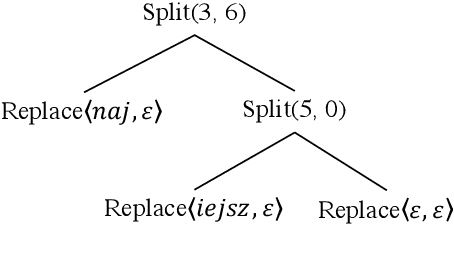
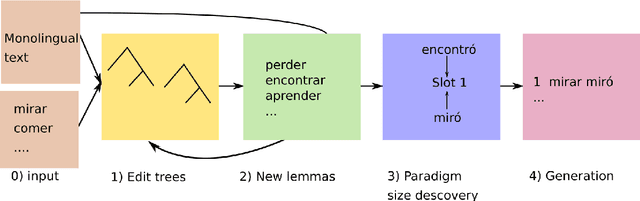
We propose the task of unsupervised morphological paradigm completion. Given only raw text and a lemma list, the task consists of generating the morphological paradigms, i.e., all inflected forms, of the lemmas. From a natural language processing (NLP) perspective, this is a challenging unsupervised task, and high-performing systems have the potential to improve tools for low-resource languages or to assist linguistic annotators. From a cognitive science perspective, this can shed light on how children acquire morphological knowledge. We further introduce a system for the task, which generates morphological paradigms via the following steps: (i) EDIT TREE retrieval, (ii) additional lemma retrieval, (iii) paradigm size discovery, and (iv) inflection generation. We perform an evaluation on 14 typologically diverse languages. Our system outperforms trivial baselines with ease and, for some languages, even obtains a higher accuracy than minimally supervised systems.
Intermediate-Task Transfer Learning with Pretrained Models for Natural Language Understanding: When and Why Does It Work?
May 09, 2020
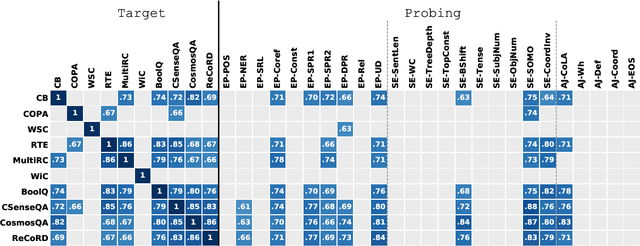
While pretrained models such as BERT have shown large gains across natural language understanding tasks, their performance can be improved by further training the model on a data-rich intermediate task, before fine-tuning it on a target task. However, it is still poorly understood when and why intermediate-task training is beneficial for a given target task. To investigate this, we perform a large-scale study on the pretrained RoBERTa model with 110 intermediate-target task combinations. We further evaluate all trained models with 25 probing tasks meant to reveal the specific skills that drive transfer. We observe that intermediate tasks requiring high-level inference and reasoning abilities tend to work best. We also observe that target task performance is strongly correlated with higher-level abilities such as coreference resolution. However, we fail to observe more granular correlations between probing and target task performance, highlighting the need for further work on broad-coverage probing benchmarks. We also observe evidence that the forgetting of knowledge learned during pretraining may limit our analysis, highlighting the need for further work on transfer learning methods in these settings.
Weakly Supervised POS Taggers Perform Poorly on Truly Low-Resource Languages
Apr 28, 2020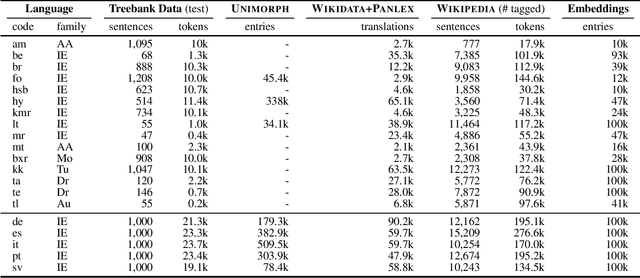
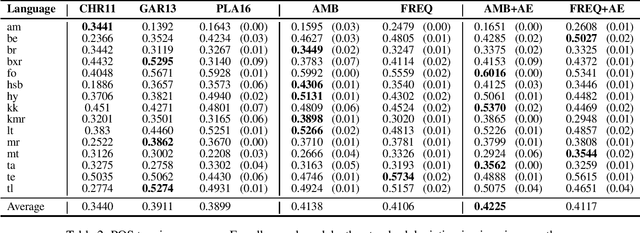
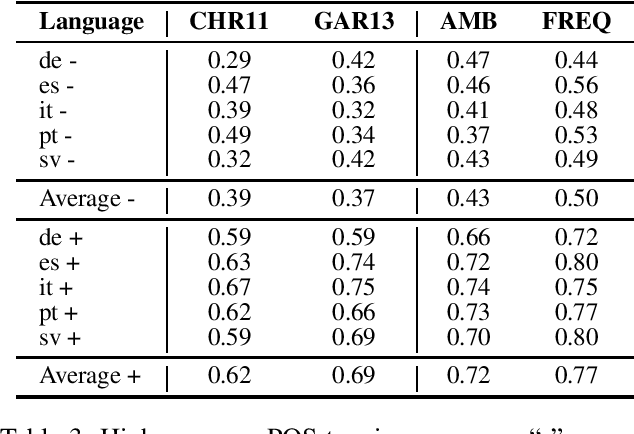
Part-of-speech (POS) taggers for low-resource languages which are exclusively based on various forms of weak supervision - e.g., cross-lingual transfer, type-level supervision, or a combination thereof - have been reported to perform almost as well as supervised ones. However, weakly supervised POS taggers are commonly only evaluated on languages that are very different from truly low-resource languages, and the taggers use sources of information, like high-coverage and almost error-free dictionaries, which are likely not available for resource-poor languages. We train and evaluate state-of-the-art weakly supervised POS taggers for a typologically diverse set of 15 truly low-resource languages. On these languages, given a realistic amount of resources, even our best model gets only less than half of the words right. Our results highlight the need for new and different approaches to POS tagging for truly low-resource languages.