 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnonyNoise: Anonymizing Event Data with Smart Noise to Outsmart Re-Identification and Preserve Privacy
Nov 25, 2024The increasing capabilities of deep neural networks for re-identification, combined with the rise in public surveillance in recent years, pose a substantial threat to individual privacy. Event cameras were initially considered as a promising solution since their output is sparse and therefore difficult for humans to interpret. However, recent advances in deep learning proof that neural networks are able to reconstruct high-quality grayscale images and re-identify individuals using data from event cameras. In our paper, we contribute a crucial ethical discussion on data privacy and present the first event anonymization pipeline to prevent re-identification not only by humans but also by neural networks. Our method effectively introduces learnable data-dependent noise to cover personally identifiable information in raw event data, reducing attackers' re-identification capabilities by up to 60%, while maintaining substantial information for the performing of downstream tasks. Moreover, our anonymization generalizes well on unseen data and is robust against image reconstruction and inversion attacks. Code: https://github.com/dfki-av/AnonyNoise
ShapeAug++: More Realistic Shape Augmentation for Event Data
Sep 17, 2024



The novel Dynamic Vision Sensors (DVSs) gained a great amount of attention recently as they are superior compared to RGB cameras in terms of latency, dynamic range and energy consumption. This is particularly of interest for autonomous applications since event cameras are able to alleviate motion blur and allow for night vision. One challenge in real-world autonomous settings is occlusion where foreground objects hinder the view on traffic participants in the background. The ShapeAug method addresses this problem by using simulated events resulting from objects moving on linear paths for event data augmentation. However, the shapes and movements lack complexity, making the simulation fail to resemble the behavior of objects in the real world. Therefore in this paper, we propose ShapeAug++, an extended version of ShapeAug which involves randomly generated polygons as well as curved movements. We show the superiority of our method on multiple DVS classification datasets, improving the top-1 accuracy by up to 3.7% compared to ShapeAug.
ShapeAug: Occlusion Augmentation for Event Camera Data
Jan 04, 2024Recently, Dynamic Vision Sensors (DVSs) sparked a lot of interest due to their inherent advantages over conventional RGB cameras. These advantages include a low latency, a high dynamic range and a low energy consumption. Nevertheless, the processing of DVS data using Deep Learning (DL) methods remains a challenge, particularly since the availability of event training data is still limited. This leads to a need for event data augmentation techniques in order to improve accuracy as well as to avoid over-fitting on the training data. Another challenge especially in real world automotive applications is occlusion, meaning one object is hindering the view onto the object behind it. In this paper, we present a novel event data augmentation approach, which addresses this problem by introducing synthetic events for randomly moving objects in a scene. We test our method on multiple DVS classification datasets, resulting in an relative improvement of up to 6.5 % in top1-accuracy. Moreover, we apply our augmentation technique on the real world Gen1 Automotive Event Dataset for object detection, where we especially improve the detection of pedestrians by up to 5 %.
Self-SuperFlow: Self-supervised Scene Flow Prediction in Stereo Sequences
Jun 30, 2022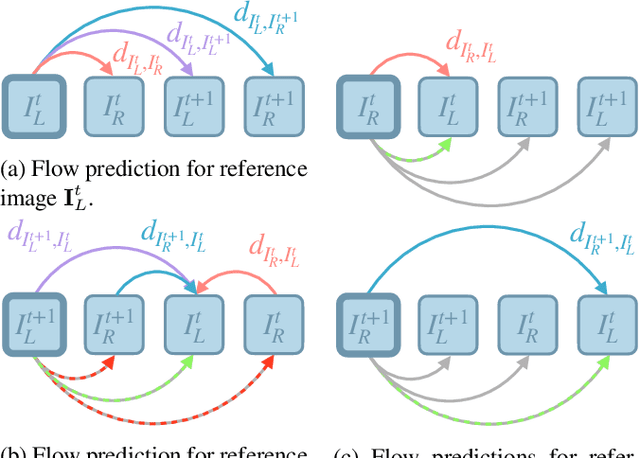


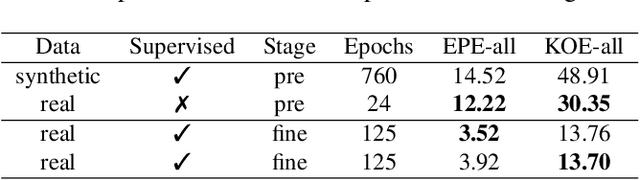
In recent years, deep neural networks showed their exceeding capabilities in addressing many computer vision tasks including scene flow prediction. However, most of the advances are dependent on the availability of a vast amount of dense per pixel ground truth annotations, which are very difficult to obtain for real life scenarios. Therefore, synthetic data is often relied upon for supervision, resulting in a representation gap between the training and test data. Even though a great quantity of unlabeled real world data is available, there is a huge lack in self-supervised methods for scene flow prediction. Hence, we explore the extension of a self-supervised loss based on the Census transform and occlusion-aware bidirectional displacements for the problem of scene flow prediction. Regarding the KITTI scene flow benchmark, our method outperforms the corresponding supervised pre-training of the same network and shows improved generalization capabilities while achieving much faster convergence.