 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a self-supervised tone mapping operator via feature contrast masking loss
Oct 19, 2021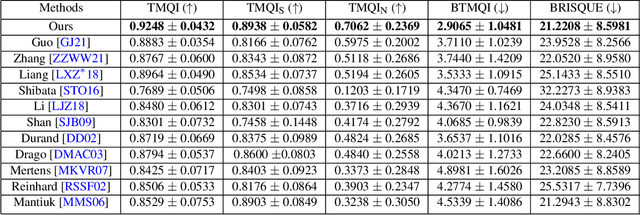
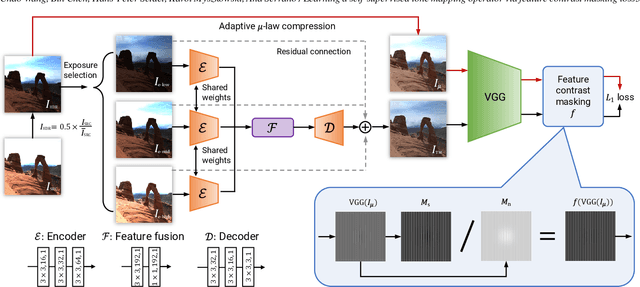

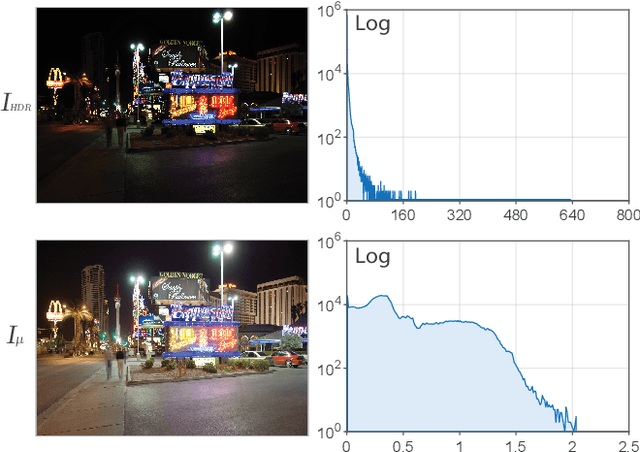
High Dynamic Range (HDR) content is becoming ubiquitous due to the rapid development of capture technologies. Nevertheless, the dynamic range of common display devices is still limited, therefore tone mapping (TM) remains a key challenge for image visualization. Recent work has demonstrated that neural networks can achieve remarkable performance in this task when compared to traditional methods, however, the quality of the results of these learning-based methods is limited by the training data. Most existing works use as training set a curated selection of best-performing results from existing traditional tone mapping operators (often guided by a quality metric), therefore, the quality of newly generated results is fundamentally limited by the performance of such operators. This quality might be even further limited by the pool of HDR content that is used for training. In this work we propose a learning-based self-supervised tone mapping operator that is trained at test time specifically for each HDR image and does not need any data labeling. The key novelty of our approach is a carefully designed loss function built upon fundamental knowledge on contrast perception that allows for directly comparing the content in the HDR and tone mapped images. We achieve this goal by reformulating classic VGG feature maps into feature contrast maps that normalize local feature differences by their average magnitude in a local neighborhood, allowing our loss to account for contrast masking effects. We perform extensive ablation studies and exploration of parameters and demonstrate that our solution outperforms existing approaches with a single set of fixed parameters, as confirmed by both objective and subjective metrics.
Learning Foveated Reconstruction to Preserve Perceived Image Statistics
Aug 07, 2021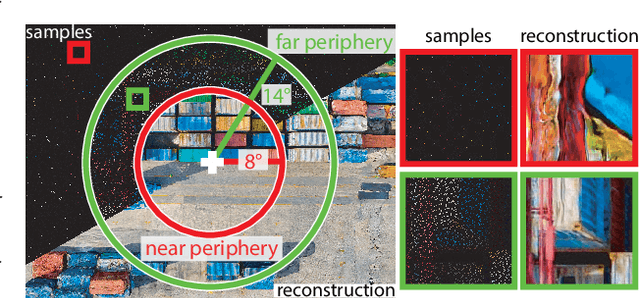

Foveated image reconstruction recovers full image from a sparse set of samples distributed according to the human visual system's retinal sensitivity that rapidly drops with eccentricity. Recently, the use of Generative Adversarial Networks was shown to be a promising solution for such a task as they can successfully hallucinate missing image information. Like for other supervised learning approaches, also for this one, the definition of the loss function and training strategy heavily influences the output quality. In this work, we pose the question of how to efficiently guide the training of foveated reconstruction techniques such that they are fully aware of the human visual system's capabilities and limitations, and therefore, reconstruct visually important image features. Due to the nature of GAN-based solutions, we concentrate on the human's sensitivity to hallucination for different input sample densities. We present new psychophysical experiments, a dataset, and a procedure for training foveated image reconstruction. The strategy provides flexibility to the generator network by penalizing only perceptually important deviations in the output. As a result, the method aims to preserve perceived image statistics rather than natural image statistics. We evaluate our strategy and compare it to alternative solutions using a newly trained objective metric and user experiments.
HDR Denoising and Deblurring by Learning Spatio-temporal Distortion Models
Dec 23, 2020
We seek to reconstruct sharp and noise-free high-dynamic range (HDR) video from a dual-exposure sensor that records different low-dynamic range (LDR) information in different pixel columns: Odd columns provide low-exposure, sharp, but noisy information; even columns complement this with less noisy, high-exposure, but motion-blurred data. Previous LDR work learns to deblur and denoise (DISTORTED->CLEAN) supervised by pairs of CLEAN and DISTORTED images. Regrettably, capturing DISTORTED sensor readings is time-consuming; as well, there is a lack of CLEAN HDR videos. We suggest a method to overcome those two limitations. First, we learn a different function instead: CLEAN->DISTORTED, which generates samples containing correlated pixel noise, and row and column noise, as well as motion blur from a low number of CLEAN sensor readings. Second, as there is not enough CLEAN HDR video available, we devise a method to learn from LDR video in-stead. Our approach compares favorably to several strong baselines, and can boost existing methods when they are re-trained on our data. Combined with spatial and temporal super-resolution, it enables applications such as re-lighting with low noise or blur.
X-Fields: Implicit Neural View-, Light- and Time-Image Interpolation
Oct 01, 2020
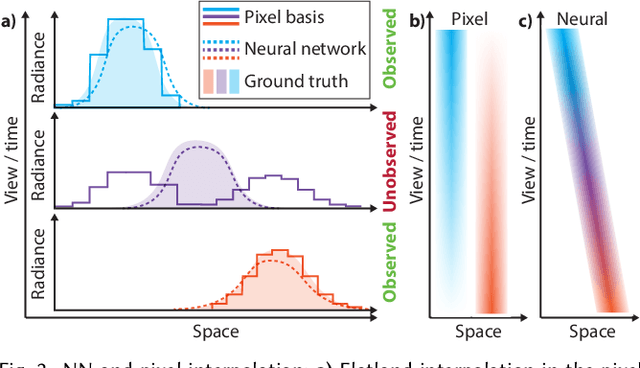
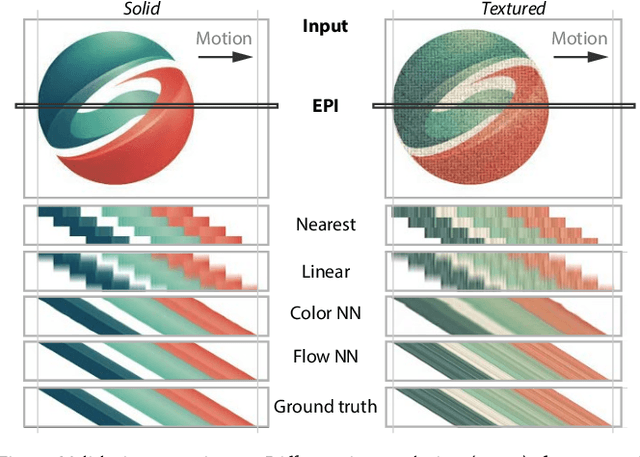
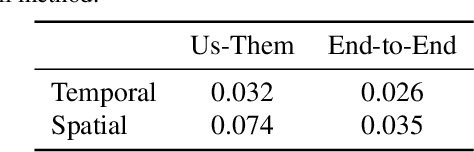
We suggest to represent an X-Field -a set of 2D images taken across different view, time or illumination conditions, i.e., video, light field, reflectance fields or combinations thereof-by learning a neural network (NN) to map their view, time or light coordinates to 2D images. Executing this NN at new coordinates results in joint view, time or light interpolation. The key idea to make this workable is a NN that already knows the "basic tricks" of graphics (lighting, 3D projection, occlusion) in a hard-coded and differentiable form. The NN represents the input to that rendering as an implicit map, that for any view, time, or light coordinate and for any pixel can quantify how it will move if view, time or light coordinates change (Jacobian of pixel position with respect to view, time, illumination, etc.). Our X-Field representation is trained for one scene within minutes, leading to a compact set of trainable parameters and hence real-time navigation in view, time and illumination.
Neural View-Interpolation for Sparse Light Field Video
Nov 06, 2019
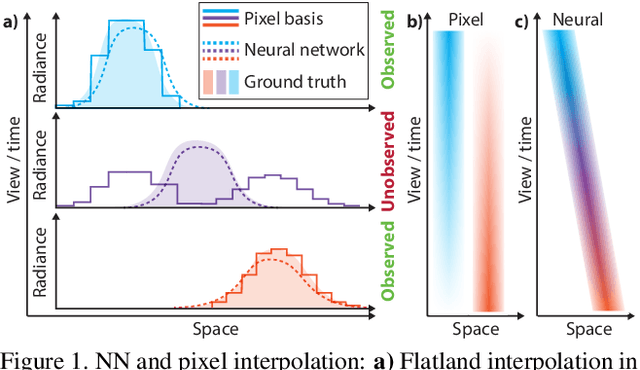
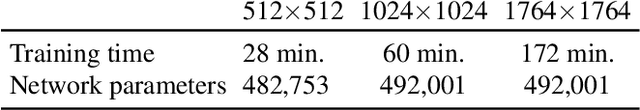

We suggest representing light field (LF) videos as "one-off" neural networks (NN), i.e., a learned mapping from view-plus-time coordinates to high-resolution color values, trained on sparse views. Initially, this sounds like a bad idea for three main reasons: First, a NN LF will likely have less quality than a same-sized pixel basis representation. Second, only few training data, e.g., 9 exemplars per frame are available for sparse LF videos. Third, there is no generalization across LFs, but across view and time instead. Consequently, a network needs to be trained for each LF video. Surprisingly, these problems can turn into substantial advantages: Other than the linear pixel basis, a NN has to come up with a compact, non-linear i.e., more intelligent, explanation of color, conditioned on the sparse view and time coordinates. As observed for many NN however, this representation now is interpolatable: if the image output for sparse view coordinates is plausible, it is for all intermediate, continuous coordinates as well. Our specific network architecture involves a differentiable occlusion-aware warping step, which leads to a compact set of trainable parameters and consequently fast learning and fast execution.
Towards a quality metric for dense light fields
Apr 25, 2017

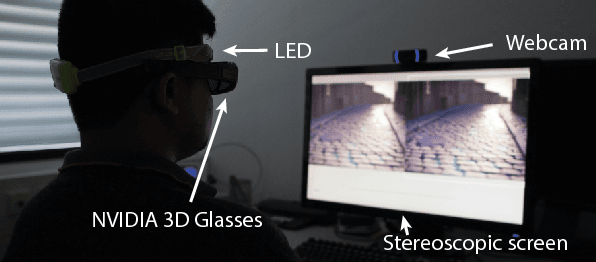
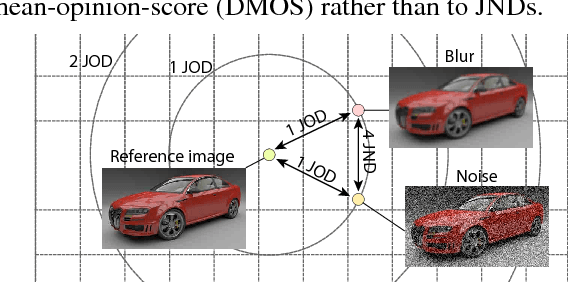
Light fields become a popular representation of three dimensional scenes, and there is interest in their processing, resampling, and compression. As those operations often result in loss of quality, there is a need to quantify it. In this work, we collect a new dataset of dense reference and distorted light fields as well as the corresponding quality scores which are scaled in perceptual units. The scores were acquired in a subjective experiment using an interactive light-field viewing setup. The dataset contains typical artifacts that occur in light-field processing chain due to light-field reconstruction, multi-view compression, and limitations of automultiscopic displays. We test a number of existing objective quality metrics to determine how well they can predict the quality of light fields. We find that the existing image quality metrics provide good measures of light-field quality, but require dense reference light- fields for optimal performance. For more complex tasks of comparing two distorted light fields, their performance drops significantly, which reveals the need for new, light-field-specific metrics.