 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-time Analysis of Approximate Policy Iteration for the Linear Quadratic Regulator
May 30, 2019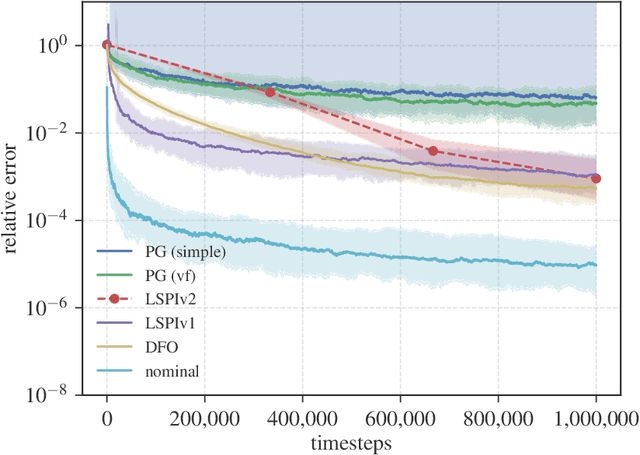
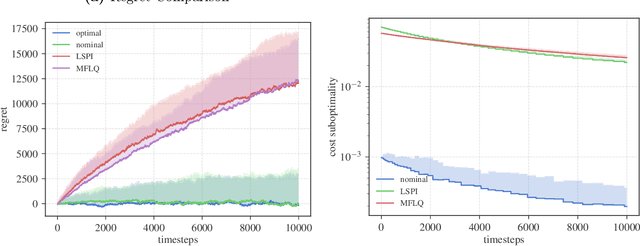
We study the sample complexity of approximate policy iteration (PI) for the Linear Quadratic Regulator (LQR), building on a recent line of work using LQR as a testbed to understand the limits of reinforcement learning (RL) algorithms on continuous control tasks. Our analysis quantifies the tension between policy improvement and policy evaluation, and suggests that policy evaluation is the dominant factor in terms of sample complexity. Specifically, we show that to obtain a controller that is within $\varepsilon$ of the optimal LQR controller, each step of policy evaluation requires at most $(n+d)^3/\varepsilon^2$ samples, where $n$ is the dimension of the state vector and $d$ is the dimension of the input vector. On the other hand, only $\log(1/\varepsilon)$ policy improvement steps suffice, resulting in an overall sample complexity of $(n+d)^3 \varepsilon^{-2} \log(1/\varepsilon)$. We furthermore build on our analysis and construct a simple adaptive procedure based on $\varepsilon$-greedy exploration which relies on approximate PI as a sub-routine and obtains $T^{2/3}$ regret, improving upon a recent result of Abbasi-Yadkori et al.
Generic Inference in Latent Gaussian Process Models
Nov 05, 2018
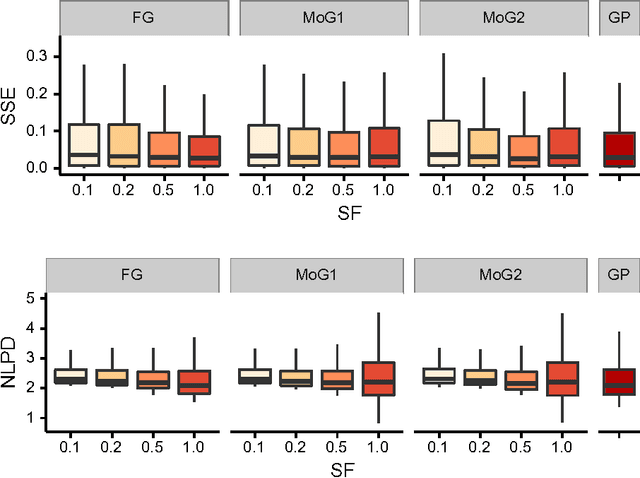
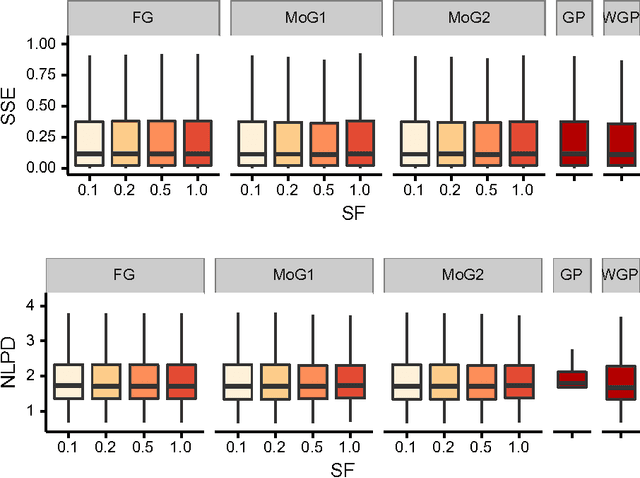
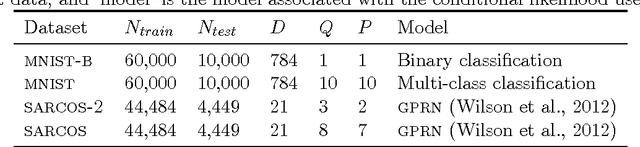
We develop an automated variational method for inference in models with Gaussian process (GP) priors and general likelihoods. The method supports multiple outputs and multiple latent functions and does not require detailed knowledge of the conditional likelihood, only needing its evaluation as a black-box function. Using a mixture of Gaussians as the variational distribution, we show that the evidence lower bound and its gradients can be estimated efficiently using samples from univariate Gaussian distributions. Furthermore, the method is scalable to large datasets which is achieved by using an augmented prior via the inducing-variable approach underpinning most sparse GP approximations, along with parallel computation and stochastic optimization. We evaluate our approach quantitatively and qualitatively with experiments on small datasets, medium-scale datasets and large datasets, showing its competitiveness under different likelihood models and sparsity levels. On the large-scale experiments involving prediction of airline delays and classification of handwritten digits, we show that our method is on par with the state-of-the-art hard-coded approaches for scalable GP regression and classification.
AutoGP: Exploring the Capabilities and Limitations of Gaussian Process Models
Mar 06, 2017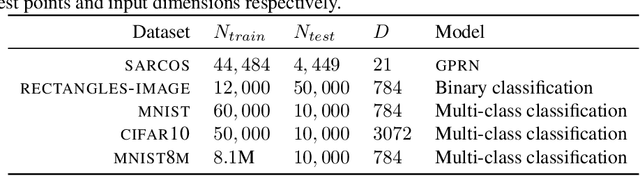
We investigate the capabilities and limitations of Gaussian process models by jointly exploring three complementary directions: (i) scalable and statistically efficient inference; (ii) flexible kernels; and (iii) objective functions for hyperparameter learning alternative to the marginal likelihood. Our approach outperforms all previously reported GP methods on the standard MNIST dataset; performs comparatively to previous kernel-based methods using the RECTANGLES-IMAGE dataset; and breaks the 1% error-rate barrier in GP models using the MNIST8M dataset, showing along the way the scalability of our method at unprecedented scale for GP models (8 million observations) in classification problems. Overall, our approach represents a significant breakthrough in kernel methods and GP models, bridging the gap between deep learning approaches and kernel machines.