 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information Theory Approach on Deciding Spectroscopic Follow Ups
Nov 06, 2019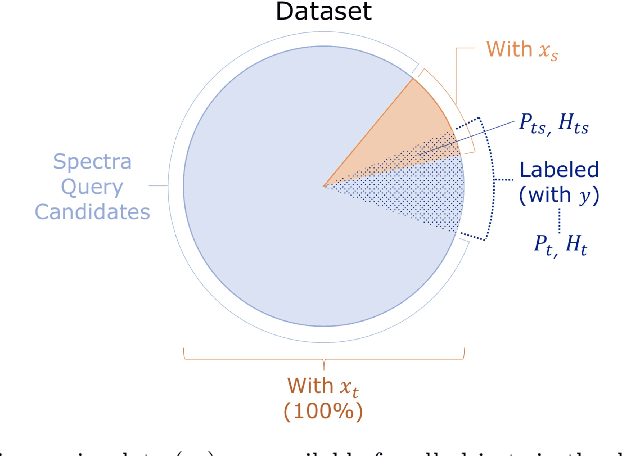
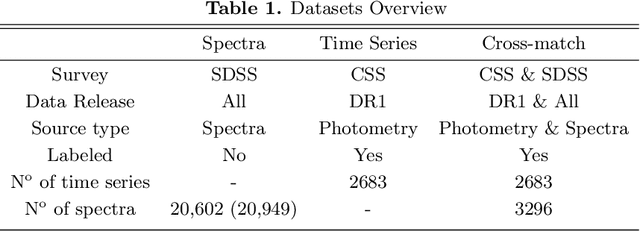
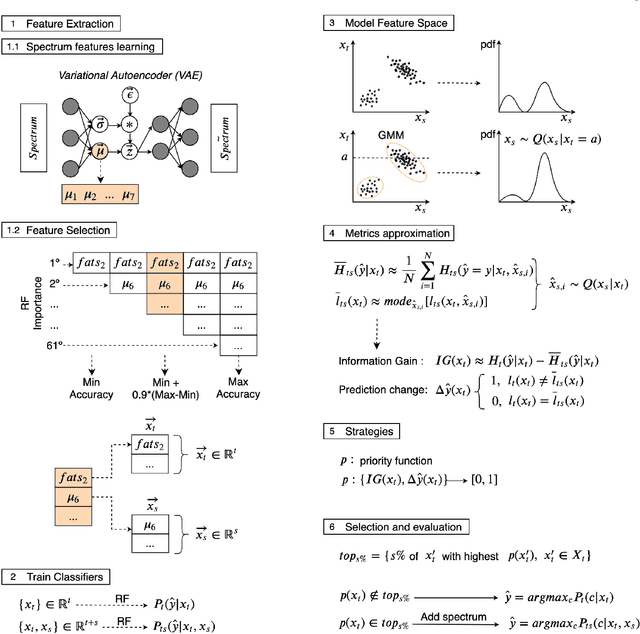
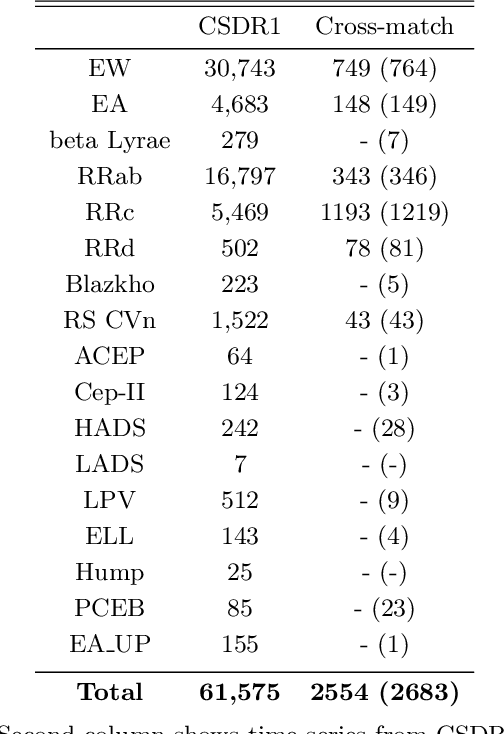
Classification and characterization of variable phenomena and transient phenomena are critical for astrophysics and cosmology. These objects are commonly studied using photometric time series or spectroscopic data. Given that many ongoing and future surveys are in time-domain and given that adding spectra provide further insights but requires more observational resources, it would be valuable to know which objects should we prioritize to have spectrum in addition to time series. We propose a methodology in a probabilistic setting that determines a-priory which objects are worth taking spectrum to obtain better insights, where we focus 'insight' as the type of the object (classification). Objects for which we query its spectrum are reclassified using their full spectrum information. We first train two classifiers, one that uses photometric data and another that uses photometric and spectroscopic data together. Then for each photometric object we estimate the probability of each possible spectrum outcome. We combine these models in various probabilistic frameworks (strategies) which are used to guide the selection of follow up observations. The best strategy depends on the intended use, whether it is getting more confidence or accuracy. For a given number of candidate objects (127, equal to 5% of the dataset) for taking spectra, we improve 37% class prediction accuracy as opposed to 20% of a non-naive (non-random) best base-line strategy. Our approach provides a general framework for follow-up strategies and can be extended beyond classification and to include other forms of follow-ups beyond spectroscopy.
An Algorithm for the Visualization of Relevant Patterns in Astronomical Light Curves
Mar 08, 2019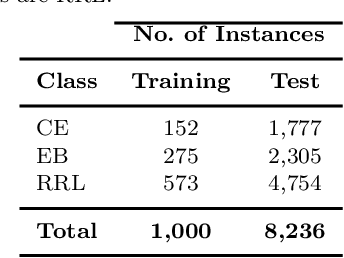

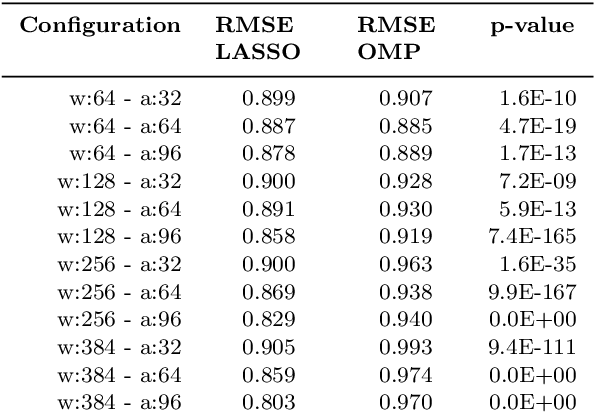
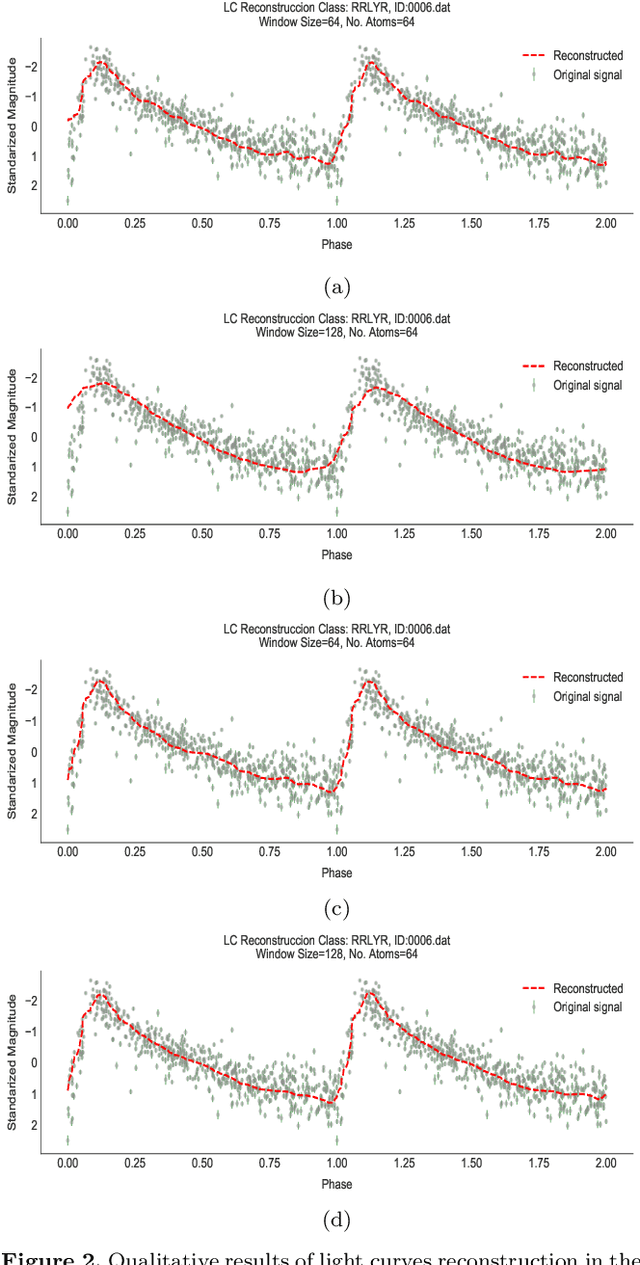
Within the last years, the classification of variable stars with Machine Learning has become a mainstream area of research. Recently, visualization of time series is attracting more attention in data science as a tool to visually help scientists to recognize significant patterns in complex dynamics. Within the Machine Learning literature, dictionary-based methods have been widely used to encode relevant parts of image data. These methods intrinsically assign a degree of importance to patches in pictures, according to their contribution in the image reconstruction. Inspired by dictionary-based techniques, we present an approach that naturally provides the visualization of salient parts in astronomical light curves, making the analogy between image patches and relevant pieces in time series. Our approach encodes the most meaningful patterns such that we can approximately reconstruct light curves by just using the encoded information. We test our method in light curves from the OGLE-III and StarLight databases. Our results show that the proposed model delivers an automatic and intuitive visualization of relevant light curve parts, such as local peaks and drops in magnitude.
* Accepted 2019 January 8. Received 2019 January 8; in original form 2018 January 29. 7 pages, 6 figures
A Full Probabilistic Model for Yes/No Type Crowdsourcing in Multi-Class Classification
Jan 02, 2019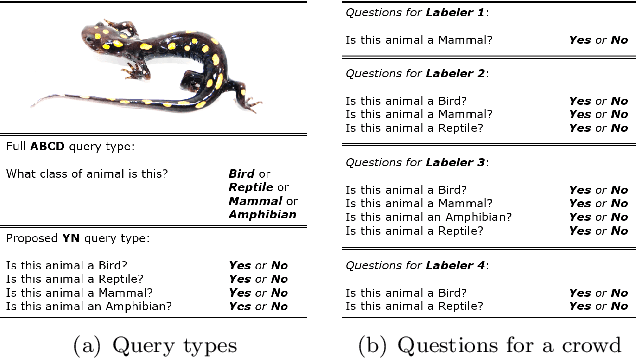
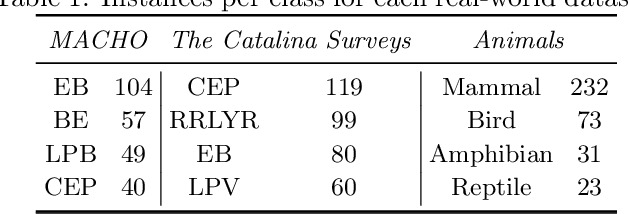
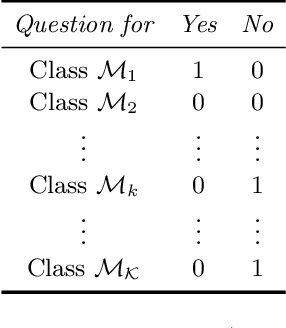

Crowdsourcing has become widely used in supervised scenarios where training sets are scarce and hard to obtain. Most crowdsourcing models in literature assume labelers can provide answers for full questions. In classification contexts, full questions mean that a labeler is asked to discern among all the possible classes. Unfortunately, that discernment is not always easy in realistic scenarios. Labelers may not be experts in differentiating all the classes. In this work, we provide a full probabilistic model for a shorter type of queries. Our shorter queries just required a 'yes' or 'no' response. Our model estimates a joint posterior distribution of matrices related to the labelers confusions and the posterior probability of the class of every object. We develop an approximate inference approach using Monte Carlo Sampling and Black Box Variational Inference, where we provide the derivation of the necessary gradients. We build two realistic crowdsourcing scenarios to test our model. The first scenario queries for irregular astronomical time-series. The second scenario relies on animal's image classification. Results show that we can achieve comparable results with full query crowdsourcing. Furthermore, we show that modeling the labelers failures plays an important role in estimating the true classes. Finally, we provide the community with two real datasets obtained from our crowdsourcing experiments. All our code is publicly available (Available at: revealed as soon as the paper gets published.)
Deep multi-survey classification of variable stars
Oct 21, 2018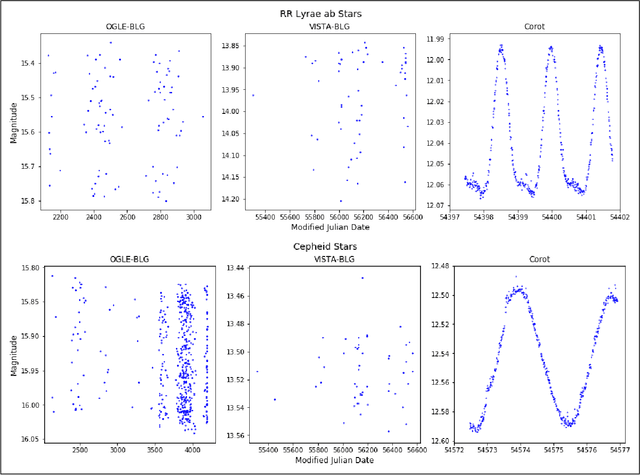
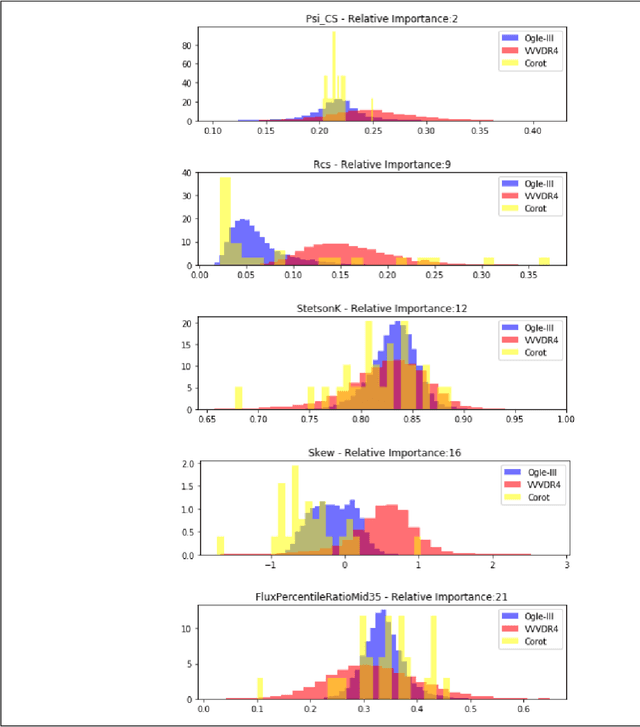
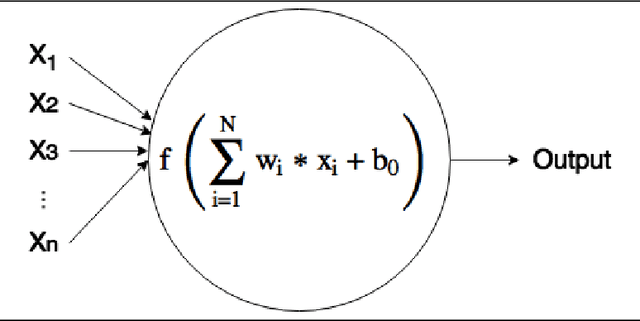
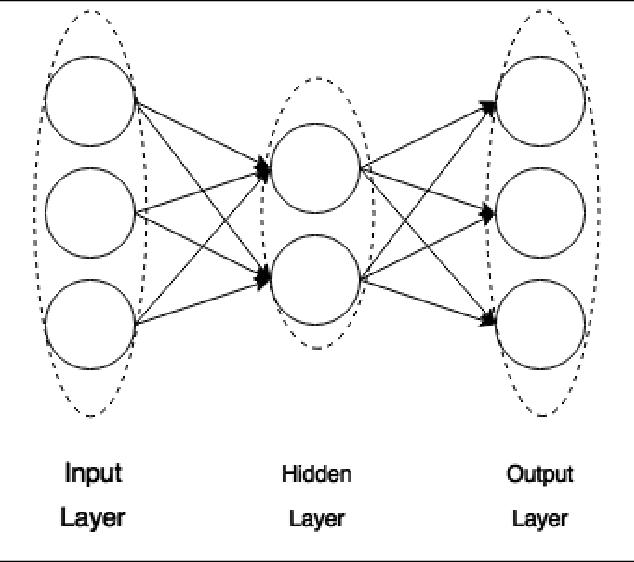
During the last decade, a considerable amount of effort has been made to classify variable stars using different machine learning techniques. Typically, light curves are represented as vectors of statistical descriptors or features that are used to train various algorithms. These features demand big computational powers that can last from hours to days, making impossible to create scalable and efficient ways of automatically classifying variable stars. Also, light curves from different surveys cannot be integrated and analyzed together when using features, because of observational differences. For example, having variations in cadence and filters, feature distributions become biased and require expensive data-calibration models. The vast amount of data that will be generated soon make necessary to develop scalable machine learning architectures without expensive integration techniques. Convolutional Neural Networks have shown impressing results in raw image classification and representation within the machine learning literature. In this work, we present a novel Deep Learning model for light curve classification, mainly based on convolutional units. Our architecture receives as input the differences between time and magnitude of light curves. It captures the essential classification patterns regardless of cadence and filter. In addition, we introduce a novel data augmentation schema for unevenly sampled time series. We test our method using three different surveys: OGLE-III; Corot; and VVV, which differ in filters, cadence, and area of the sky. We show that besides the benefit of scalability, our model obtains state of the art levels accuracy in light curve classification benchmarks.
Clustering Based Feature Learning on Variable Stars
Feb 29, 2016
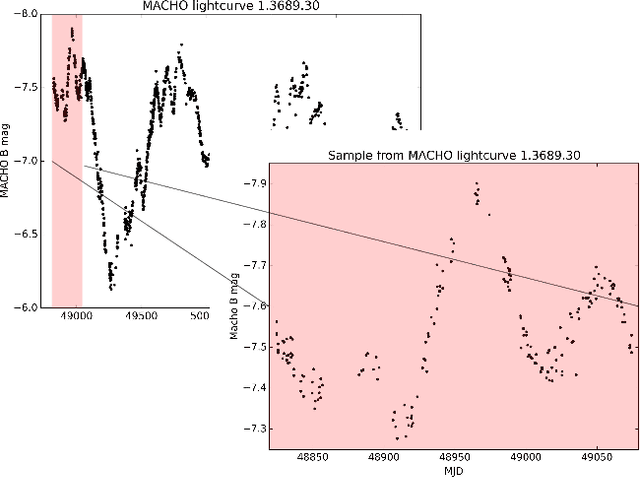
The success of automatic classification of variable stars strongly depends on the lightcurve representation. Usually, lightcurves are represented as a vector of many statistical descriptors designed by astronomers called features. These descriptors commonly demand significant computational power to calculate, require substantial research effort to develop and do not guarantee good performance on the final classification task. Today, lightcurve representation is not entirely automatic; algorithms that extract lightcurve features are designed by humans and must be manually tuned up for every survey. The vast amounts of data that will be generated in future surveys like LSST mean astronomers must develop analysis pipelines that are both scalable and automated. Recently, substantial efforts have been made in the machine learning community to develop methods that prescind from expert-designed and manually tuned features for features that are automatically learned from data. In this work we present what is, to our knowledge, the first unsupervised feature learning algorithm designed for variable stars. Our method first extracts a large number of lightcurve subsequences from a given set of photometric data, which are then clustered to find common local patterns in the time series. Representatives of these patterns, called exemplars, are then used to transform lightcurves of a labeled set into a new representation that can then be used to train an automatic classifier. The proposed algorithm learns the features from both labeled and unlabeled lightcurves, overcoming the bias generated when the learning process is done only with labeled data. We test our method on MACHO and OGLE datasets; the results show that the classification performance we achieve is as good and in some cases better than the performance achieved using traditional features, while the computational cost is significantly lower.
Supervised detection of anomalous light-curves in massive astronomical catalogs
May 27, 2015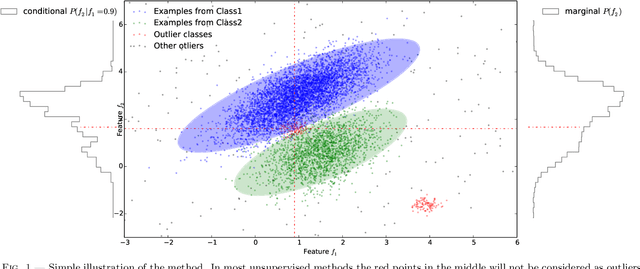
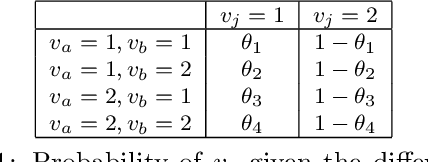
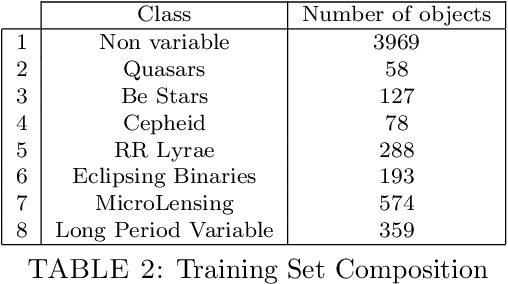
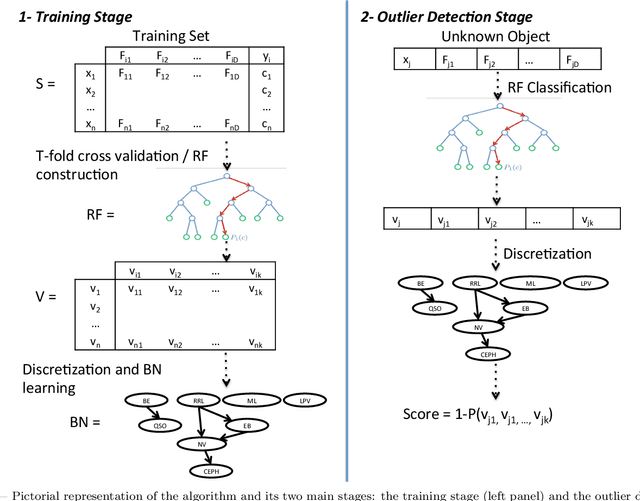
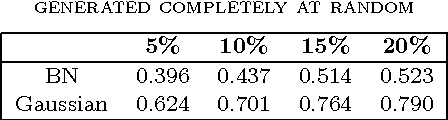
The development of synoptic sky surveys has led to a massive amount of data for which resources needed for analysis are beyond human capabilities. To process this information and to extract all possible knowledge, machine learning techniques become necessary. Here we present a new method to automatically discover unknown variable objects in large astronomical catalogs. With the aim of taking full advantage of all the information we have about known objects, our method is based on a supervised algorithm. In particular, we train a random forest classifier using known variability classes of objects and obtain votes for each of the objects in the training set. We then model this voting distribution with a Bayesian network and obtain the joint voting distribution among the training objects. Consequently, an unknown object is considered as an outlier insofar it has a low joint probability. Our method is suitable for exploring massive datasets given that the training process is performed offline. We tested our algorithm on 20 millions light-curves from the MACHO catalog and generated a list of anomalous candidates. We divided the candidates into two main classes of outliers: artifacts and intrinsic outliers. Artifacts were principally due to air mass variation, seasonal variation, bad calibration or instrumental errors and were consequently removed from our outlier list and added to the training set. After retraining, we selected about 4000 objects, which we passed to a post analysis stage by perfoming a cross-match with all publicly available catalogs. Within these candidates we identified certain known but rare objects such as eclipsing Cepheids, blue variables, cataclysmic variables and X-ray sources. For some outliers there were no additional information. Among them we identified three unknown variability types and few individual outliers that will be followed up for a deeper analysis.
* 16 pages, 18 figures, published in The Astrophysical Journal
Automatic Classification of Variable Stars in Catalogs with missing data
Oct 29, 2013
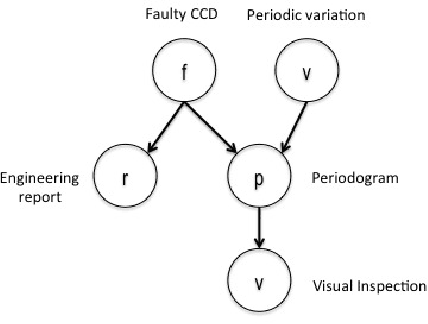
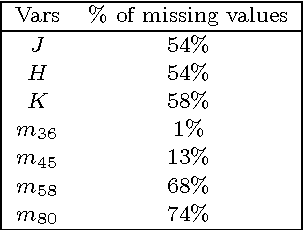
We present an automatic classification method for astronomical catalogs with missing data. We use Bayesian networks, a probabilistic graphical model, that allows us to perform inference to pre- dict missing values given observed data and dependency relationships between variables. To learn a Bayesian network from incomplete data, we use an iterative algorithm that utilises sampling methods and expectation maximization to estimate the distributions and probabilistic dependencies of variables from data with missing values. To test our model we use three catalogs with missing data (SAGE, 2MASS and UBVI) and one complete catalog (MACHO). We examine how classification accuracy changes when information from missing data catalogs is included, how our method compares to traditional missing data approaches and at what computational cost. Integrating these catalogs with missing data we find that classification of variable objects improves by few percent and by 15% for quasar detection while keeping the computational cost the same.
An improved quasar detection method in EROS-2 and MACHO LMC datasets
Apr 01, 2013

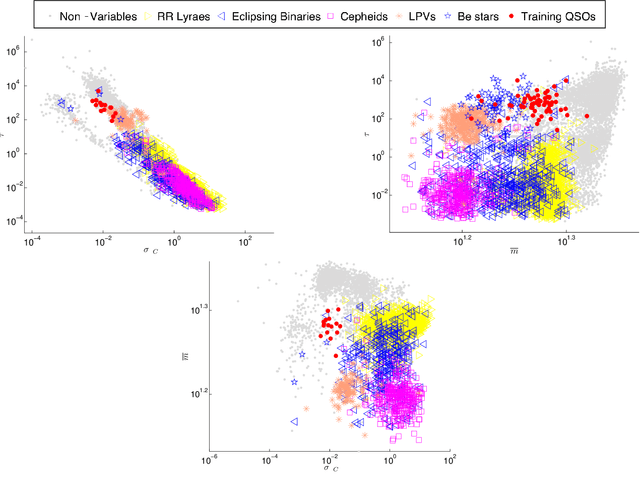

We present a new classification method for quasar identification in the EROS-2 and MACHO datasets based on a boosted version of Random Forest classifier. We use a set of variability features including parameters of a continuous auto regressive model. We prove that continuous auto regressive parameters are very important discriminators in the classification process. We create two training sets (one for EROS-2 and one for MACHO datasets) using known quasars found in the LMC. Our model's accuracy in both EROS-2 and MACHO training sets is about 90% precision and 86% recall, improving the state of the art models accuracy in quasar detection. We apply the model on the complete, including 28 million objects, EROS-2 and MACHO LMC datasets, finding 1160 and 2551 candidates respectively. To further validate our list of candidates, we crossmatched our list with a previous 663 known strong candidates, getting 74% of matches for MACHO and 40% in EROS-2. The main difference on matching level is because EROS-2 is a slightly shallower survey which translates to significantly lower signal-to-noise ratio lightcurves.