 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Non-Parametric Test to Detect Data-Copying in Generative Models
Apr 12, 2020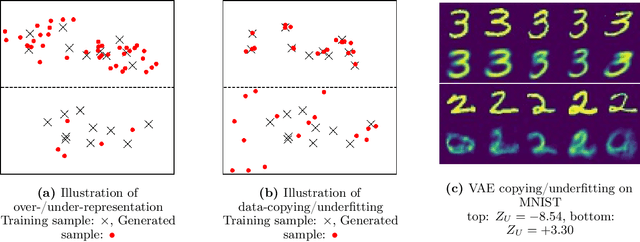

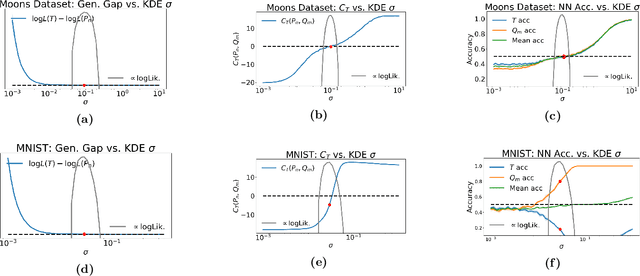
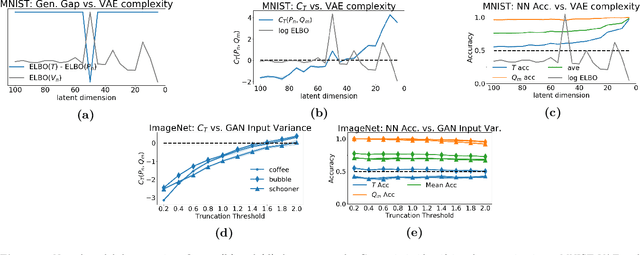
Detecting overfitting in generative models is an important challenge in machine learning. In this work, we formalize a form of overfitting that we call {\em{data-copying}} -- where the generative model memorizes and outputs training samples or small variations thereof. We provide a three sample non-parametric test for detecting data-copying that uses the training set, a separate sample from the target distribution, and a generated sample from the model, and study the performance of our test on several canonical models and datasets. For code \& examples, visit https://github.com/casey-meehan/data-copying
When are Non-Parametric Methods Robust?
Mar 13, 2020
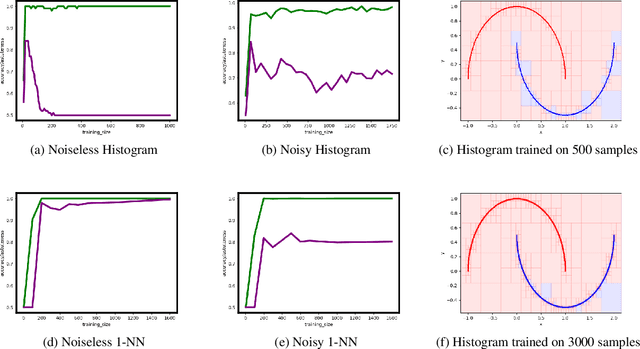
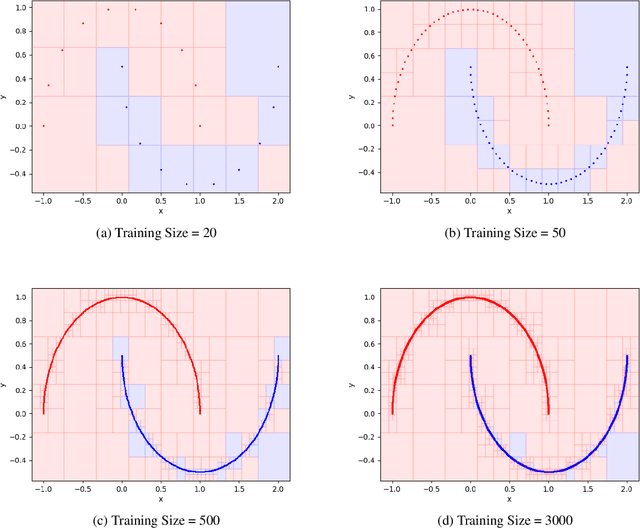
A growing body of research has shown that many classifiers are susceptible to {\em{adversarial examples}} -- small strategic modifications to test inputs that lead to misclassification. In this work, we study general non-parametric methods, with a view towards understanding when they are robust to these modifications. We establish general conditions under which non-parametric methods are r-consistent -- in the sense that they converge to optimally robust and accurate classifiers in the large sample limit. Concretely, our results show that when data is well-separated, nearest neighbors and kernel classifiers are r-consistent, while histograms are not. For general data distributions, we prove that preprocessing by Adversarial Pruning (Yang et. al., 2019) -- that makes data well-separated -- followed by nearest neighbors or kernel classifiers also leads to r-consistency.
Approximate Data Deletion from Machine Learning Models: Algorithms and Evaluations
Feb 24, 2020
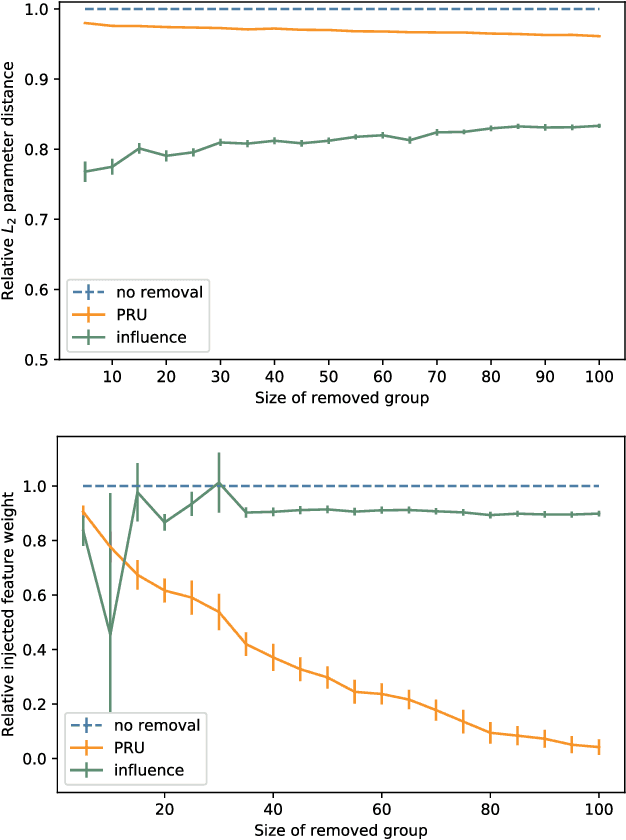
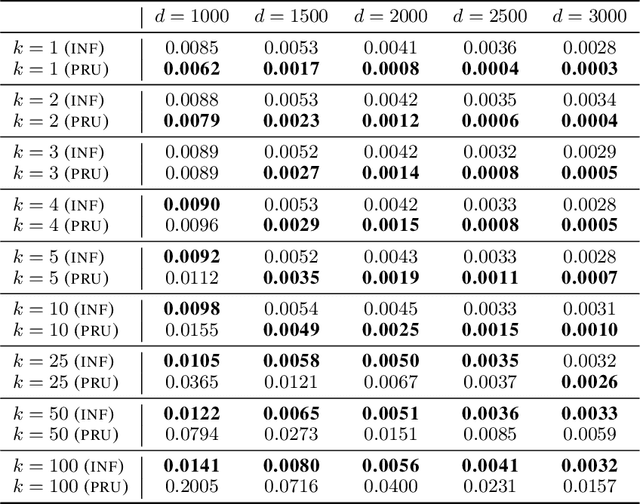
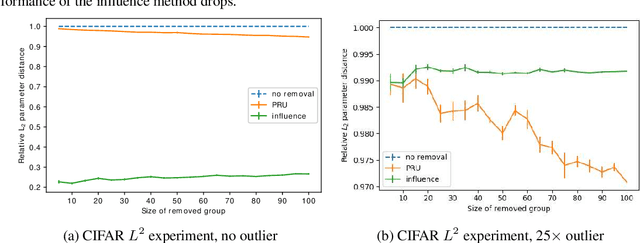
Deleting data from a trained machine learning (ML) model is a critical task in many applications. For example, we may want to remove the influence of training points that might be out of date or outliers. Regulations such as EU's General Data Protection Regulation also stipulate that individuals can request to have their data deleted. The naive approach to data deletion is to retrain the ML model on the remaining data, but this is too time consuming. Moreover there is no known efficient algorithm that exactly deletes data from most ML models. In this work, we evaluate several approaches for approximate data deletion from trained models. For the case of linear regression, we propose a new method with linear dependence on the feature dimension $d$, a significant gain over all existing methods which all have superlinear time dependence on the dimension. We also provide a new test for evaluating data deletion from linear models.
Capacity Bounded Differential Privacy
Jul 03, 2019


Differential privacy, a notion of algorithmic stability, is a gold standard for measuring the additional risk an algorithm's output poses to the privacy of a single record in the dataset. Differential privacy is defined as the distance between the output distribution of an algorithm on neighboring datasets that differ in one entry. In this work, we present a novel relaxation of differential privacy, capacity bounded differential privacy, where the adversary that distinguishes output distributions is assumed to be capacity-bounded -- i.e. bounded not in computational power, but in terms of the function class from which their attack algorithm is drawn. We model adversaries in terms of restricted f-divergences between probability distributions, and study properties of the definition and algorithms that satisfy them.
Adversarial Examples for Non-Parametric Methods: Attacks, Defenses and Large Sample Limits
Jun 07, 2019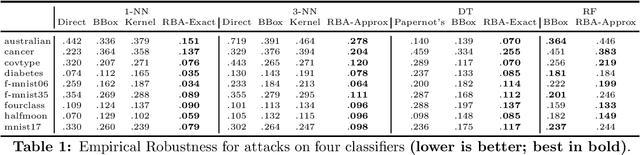
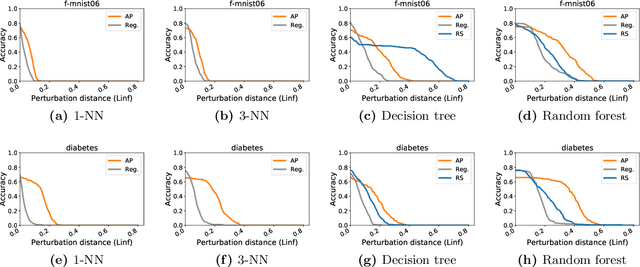
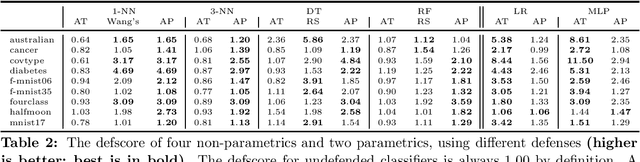
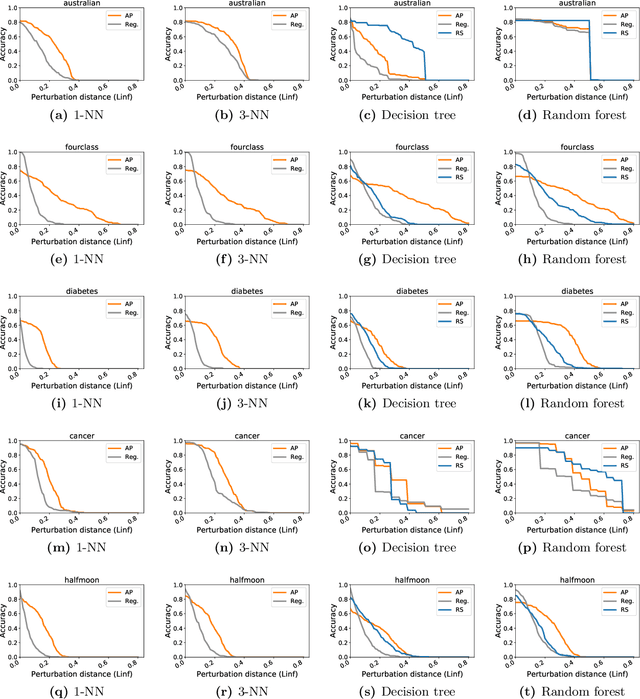
Adversarial examples have received a great deal of recent attention because of their potential to uncover security flaws in machine learning systems. However, most prior work on adversarial examples has been on parametric classifiers, for which generic attack and defense methods are known; non-parametric methods have been only considered on an ad-hoc or classifier-specific basis. In this work, we take a holistic look at adversarial examples for non-parametric methods. We first provide a general region-based attack that applies to a wide range of classifiers, including nearest neighbors, decision trees, and random forests. Motivated by the close connection between non-parametric methods and the Bayes Optimal classifier, we next exhibit a robust analogue to the Bayes Optimal, and we use it to motivate a novel and generic defense that we call adversarial pruning. We empirically show that the region-based attack and adversarial pruning defense are either better than or competitive with existing attacks and defenses for non-parametric methods, while being considerably more generally applicable.
The Label Complexity of Active Learning from Observational Data
May 29, 2019
Counterfactual learning from observational data involves learning a classifier on an entire population based on data that is observed conditioned on a selection policy. This work considers this problem in an active setting, where the learner additionally has access to unlabeled examples and can choose to get a subset of these labeled by an oracle. Prior work on this problem uses disagreement-based active learning, along with an importance weighted loss estimator to account for counterfactuals, which leads to a high label complexity. We show how to instead incorporate a more efficient counterfactual risk minimizer into the active learning algorithm. This requires us to modify both the counterfactual risk to make it amenable to active learning, as well as the active learning process to make it amenable to the risk. We provably demonstrate that the result of this is an algorithm which is statistically consistent as well as more label-efficient than prior work.
An Investigation of Data Poisoning Defenses for Online Learning
May 28, 2019
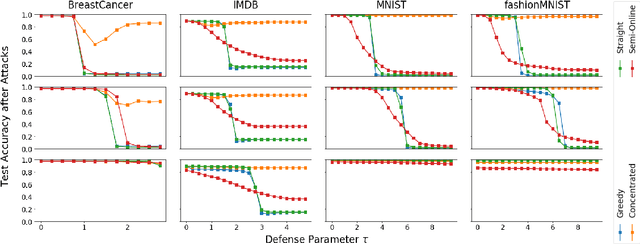
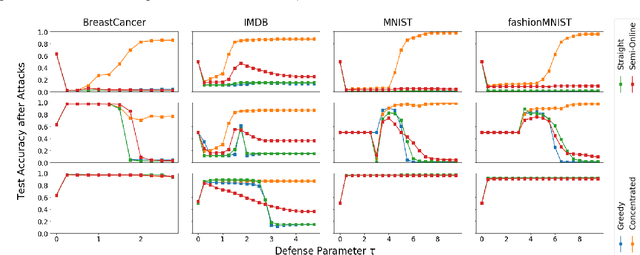
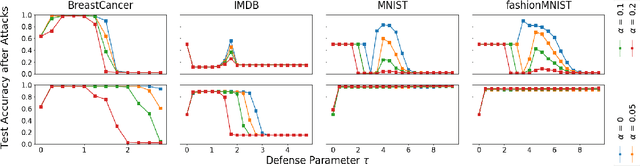
We consider data poisoning attacks, where an adversary can modify a small fraction of training data, with the goal of forcing the trained classifier to have low accuracy. While a body of prior work has developed many attacks and defenses, there is not much general understanding on when various attacks and defenses are effective. In this work, we undertake a rigorous study of defenses against data poisoning in online learning. First, we theoretically analyze four standard defenses and show conditions under which they are effective. Second, motivated by our analysis, we introduce powerful attacks against data-dependent defenses when the adversary can attack the dataset used to initialize them. Finally, we carry out an experimental study which confirms our theoretical findings, shows that the Slab defense is relatively robust, and demonstrates that defenses of moderate strength result in the highest classification accuracy overall.
Model Extraction and Active Learning
Dec 04, 2018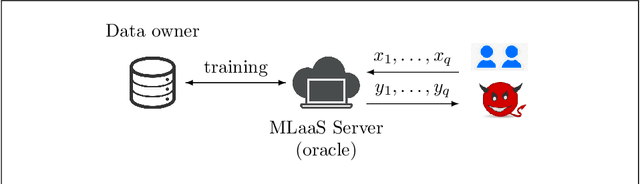
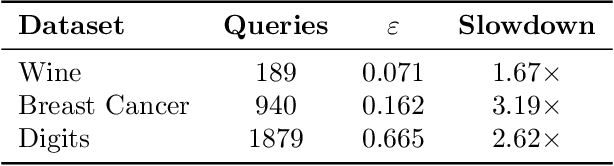
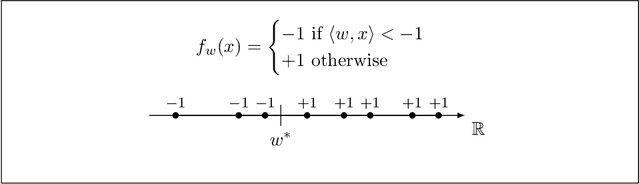
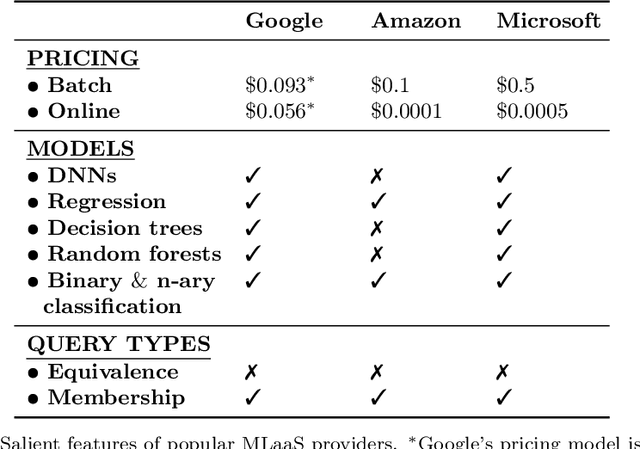
Machine learning is being increasingly used by individuals, research institutions, and corporations. This has resulted in the surge of Machine Learning-as-a-Service (MLaaS) cloud services that provide (a) tools and resources to learn the model, and (b) a user-friendly query interface to access the model. However, such MLaaS systems raise privacy concerns, one being model extraction. In model extraction attacks, adversaries maliciously exploit the query interface to steal the model. More precisely, in a model extraction attack, a good approximation of a sensitive or proprietary model held by the server is extracted (i.e. learned) by a dishonest user who interacts with the server only via the query interface. This attack was recently introduced by Tram\`er et al. at the 2016 USENIX Security Symposium, where practical attacks for various models were shown. We believe that better understanding the efficacy of model extraction attacks is paramount to designing better privacy-preserving MLaaS systems. To that end, we take the first step by (a) formalizing model extraction and discussing possible defense strategies, and (b) drawing parallels between model extraction and the better investigated active learning framework. In particular, we show that recent advancements in the active learning domain can be used to implement both model extraction attacks, and to investigate possible defense strategies.
The Inductive Bias of Restricted f-GANs
Sep 12, 2018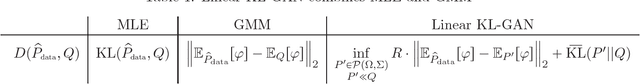
Generative adversarial networks are a novel method for statistical inference that have achieved much empirical success; however, the factors contributing to this success remain ill-understood. In this work, we attempt to analyze generative adversarial learning -- that is, statistical inference as the result of a game between a generator and a discriminator -- with the view of understanding how it differs from classical statistical inference solutions such as maximum likelihood inference and the method of moments. Specifically, we provide a theoretical characterization of the distribution inferred by a simple form of generative adversarial learning called restricted f-GANs -- where the discriminator is a function in a given function class, the distribution induced by the generator is restricted to lie in a pre-specified distribution class and the objective is similar to a variational form of the f-divergence. A consequence of our result is that for linear KL-GANs -- that is, when the discriminator is a linear function over some feature space and f corresponds to the KL-divergence -- the distribution induced by the optimal generator is neither the maximum likelihood nor the method of moments solution, but an interesting combination of both.
Data Poisoning Attacks against Online Learning
Aug 27, 2018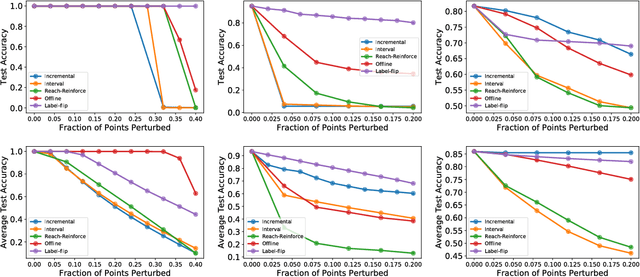

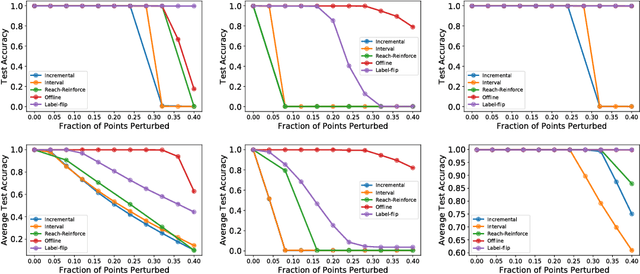
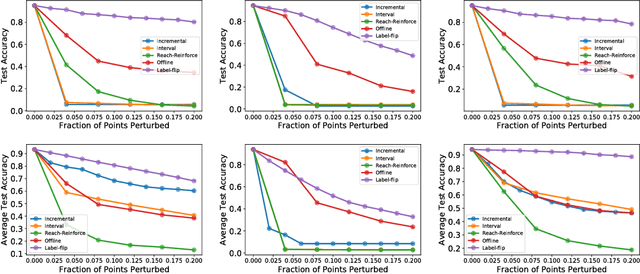
We consider data poisoning attacks, a class of adversarial attacks on machine learning where an adversary has the power to alter a small fraction of the training data in order to make the trained classifier satisfy certain objectives. While there has been much prior work on data poisoning, most of it is in the offline setting, and attacks for online learning, where training data arrives in a streaming manner, are not well understood. In this work, we initiate a systematic investigation of data poisoning attacks for online learning. We formalize the problem into two settings, and we propose a general attack strategy, formulated as an optimization problem, that applies to both with some modifications. We propose three solution strategies, and perform extensive experimental evaluation. Finally, we discuss the implications of our findings for building successful defenses.